Las medidas antibots están muy extendidas y aparecen en los principales sitios web e incluso en algunas plataformas de ciberdelincuencia para evitar el spam o el abuso. Un sistema antibot avanzado es Netacea, aunque, según mis observaciones, es menos utilizado en sitios de ciberdelincuencia. Para sitios web más sofisticados, es posible que sea necesario controlar mediante programación un navegador web de escritorio en lugar de un navegador sin interfaz gráfica como Playwright. Una opción a tener en cuenta es Hidden VNC para la automatización de navegadores, que permite simular las interacciones del ratón y el teclado.
Dado que los sitios web no pueden acceder directamente a su sistema, pueden detectar los navegadores sin interfaz gráfica o las extensiones del navegador. Sin embargo, la automatización de las interacciones a través de su sistema operativo a menudo puede pasar desapercibida, ya que imita el comportamiento real de los usuarios de forma más eficaz. Aunque esta técnica va más allá del alcance de este curso, es una opción que puede investigar por su cuenta. La mayoría de los sitios de ciberdelincuencia implementan limitaciones de velocidad basadas en direcciones IP y CAPTCHA para bloquear los bots.
Los temas de esta sección incluyen lo siguiente:
- Limitación de velocidad
- Prohibiciones de IP
- Omisión de CAPTCHA
- Bloqueo de cuentas
Limitación de velocidad
La mayoría de los sitios web tienen habilitada la limitación de velocidad para determinados puntos finales, con el objetivo de evitar el envío de solicitudes excesivas a una página web. Desde la perspectiva de un desarrollador, así es como se configura la limitación de velocidad para una ruta:
limiter = Limiter(
get_remote_address,
app=app,
default_limits=["500 per day", "200 per hour"],
storage_uri="memory://"
)
@app.route('/post/<post_type>/<int:post_id>')
@limiter.limit("30 per minute")
@login_required
def post_detail(post_type, post_id):
Como referencia, estoy ejecutando «tornet_forum» localmente sin Tor.
El límite predeterminado es de 500 solicitudes desde una IP a todas las demás rutas cada día y 200 solicitudes por hora. Sin embargo, para «/api/post», el límite es de 30 solicitudes por minuto, por lo que después de 30 solicitudes no podrás enviar más. Esa ruta se utiliza para mostrar los detalles de una publicación, así es como se ve la URL:
http://127.0.0.1:5000/post/announcements/272
Aquí hay un ejemplo en Python para mostrar lo que sucede cuando se excede el límite:
import requests
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
for reqnum in range(31):
response = requests.get(url, cookies=cookies)
print(f"Request number: {reqnum} | HTTP Status code: {response.status_code}")
Salida:
-> % python3 rate_limit_test.py
Request number: 0 | HTTP Status code: 200
Request number: 1 | HTTP Status code: 200
Request number: 2 | HTTP Status code: 200
Request number: 3 | HTTP Status code: 200
Request number: 4 | HTTP Status code: 200
Request number: 5 | HTTP Status code: 200
Request number: 6 | HTTP Status code: 200
Request number: 7 | HTTP Status code: 200
Request number: 8 | HTTP Status code: 200
Request number: 9 | HTTP Status code: 200
Request number: 10 | HTTP Status code: 200
Request number: 11 | HTTP Status code: 200
Request number: 12 | HTTP Status code: 200
Request number: 13 | HTTP Status code: 200
Request number: 14 | HTTP Status code: 200
Request number: 15 | HTTP Status code: 200
Request number: 16 | HTTP Status code: 200
Request number: 17 | HTTP Status code: 200
Request number: 18 | HTTP Status code: 200
Request number: 19 | HTTP Status code: 200
Request number: 20 | HTTP Status code: 200
Request number: 21 | HTTP Status code: 200
Request number: 22 | HTTP Status code: 200
Request number: 23 | HTTP Status code: 200
Request number: 24 | HTTP Status code: 200
Request number: 25 | HTTP Status code: 200
Request number: 26 | HTTP Status code: 200
Request number: 27 | HTTP Status code: 200
Request number: 28 | HTTP Status code: 200
Request number: 29 | HTTP Status code: 200
Request number: 30 | HTTP Status code: 429
En situaciones reales, normalmente no se puede acceder al código fuente de una aplicación, por lo que determinar el límite de velocidad, como el número de solicitudes permitidas por minuto o por cada 10 minutos, requiere prueba y error. Aunque los scripts pueden automatizar este proceso, sigue siendo tedioso.
Ahora que sabemos que el límite de velocidad se activa después de 30 solicitudes, podemos enviar 29 solicitudes, hacer una pausa de 60 segundos, enviar otras 29 solicitudes y repetir este ciclo:
import requests
import time
REQUEST_COUNT = 29
SLEEP_DURATION = 60
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
batch_num = 1
while True:
print(f"Starting batch {batch_num}")
for reqnum in range(REQUEST_COUNT):
response = requests.get(url, cookies=cookies)
print(f"Batch {batch_num} | Request number: {reqnum + 1} | HTTP Status code: {response.status_code}")
print(f"Batch {batch_num} completed. Sleeping for {SLEEP_DURATION} seconds...")
time.sleep(SLEEP_DURATION)
batch_num += 1
Salida:
-> % python3 rate_limit_test.py
Starting batch 1
Batch 1 | Request number: 1 | HTTP Status code: 200
Batch 1 | Request number: 2 | HTTP Status code: 200
Batch 1 | Request number: 3 | HTTP Status code: 200
Batch 1 | Request number: 4 | HTTP Status code: 200
Batch 1 | Request number: 5 | HTTP Status code: 200
Batch 1 | Request number: 6 | HTTP Status code: 200
Batch 1 | Request number: 7 | HTTP Status code: 200
Batch 1 | Request number: 8 | HTTP Status code: 200
Batch 1 | Request number: 9 | HTTP Status code: 200
Batch 1 | Request number: 10 | HTTP Status code: 200
Batch 1 | Request number: 11 | HTTP Status code: 200
Batch 1 | Request number: 12 | HTTP Status code: 200
Batch 1 | Request number: 13 | HTTP Status code: 200
Batch 1 | Request number: 14 | HTTP Status code: 200
Batch 1 | Request number: 15 | HTTP Status code: 200
Batch 1 | Request number: 16 | HTTP Status code: 200
Batch 1 | Request number: 17 | HTTP Status code: 200
Batch 1 | Request number: 18 | HTTP Status code: 200
Batch 1 | Request number: 19 | HTTP Status code: 200
Batch 1 | Request number: 20 | HTTP Status code: 200
Batch 1 | Request number: 21 | HTTP Status code: 200
Batch 1 | Request number: 22 | HTTP Status code: 200
Batch 1 | Request number: 23 | HTTP Status code: 200
Batch 1 | Request number: 24 | HTTP Status code: 200
Batch 1 | Request number: 25 | HTTP Status code: 200
Batch 1 | Request number: 26 | HTTP Status code: 200
Batch 1 | Request number: 27 | HTTP Status code: 200
Batch 1 | Request number: 28 | HTTP Status code: 200
Batch 1 | Request number: 29 | HTTP Status code: 200
Batch 1 completed. Sleeping for 60 seconds...
Starting batch 2
Batch 2 | Request number: 1 | HTTP Status code: 200
Batch 2 | Request number: 2 | HTTP Status code: 200
Batch 2 | Request number: 3 | HTTP Status code: 200
Batch 2 | Request number: 4 | HTTP Status code: 200
Batch 2 | Request number: 5 | HTTP Status code: 200
Batch 2 | Request number: 6 | HTTP Status code: 200
Batch 2 | Request number: 7 | HTTP Status code: 200
Batch 2 | Request number: 8 | HTTP Status code: 200
Batch 2 | Request number: 9 | HTTP Status code: 200
Batch 2 | Request number: 10 | HTTP Status code: 200
Batch 2 | Request number: 11 | HTTP Status code: 200
Batch 2 | Request number: 12 | HTTP Status code: 200
Batch 2 | Request number: 13 | HTTP Status code: 200
Batch 2 | Request number: 14 | HTTP Status code: 200
Batch 2 | Request number: 15 | HTTP Status code: 200
Batch 2 | Request number: 16 | HTTP Status code: 200
Batch 2 | Request number: 17 | HTTP Status code: 200
Batch 2 | Request number: 18 | HTTP Status code: 200
Batch 2 | Request number: 19 | HTTP Status code: 200
Batch 2 | Request number: 20 | HTTP Status code: 200
Batch 2 | Request number: 21 | HTTP Status code: 200
Batch 2 | Request number: 22 | HTTP Status code: 200
Batch 2 | Request number: 23 | HTTP Status code: 200
Batch 2 | Request number: 24 | HTTP Status code: 200
Batch 2 | Request number: 25 | HTTP Status code: 200
Batch 2 | Request number: 26 | HTTP Status code: 200
Batch 2 | Request number: 27 | HTTP Status code: 200
Batch 2 | Request number: 28 | HTTP Status code: 200
Batch 2 | Request number: 29 | HTTP Status code: 200
Batch 2 completed. Sleeping for 60 seconds...
Recuerda que aquí solo estamos enviando solicitudes a una URL, pero en el mundo real estarás enumerando cientos de publicaciones, aunque el proceso es el mismo.
Bloqueos de IP
Los bloqueos de IP eran comunes en el pasado, pero ahora son menos frecuentes y se limitan principalmente a determinados sistemas de gestión de contenidos. No los he encontrado en sitios web dedicados a la ciberdelincuencia, pero este curso te enseñará a eludirlos para que estés preparado para cualquier situación.
En los sitios web típicos, una IP prohibida se puede eludir utilizando una VPN o un proxy. Sin embargo, el scraping web a gran escala requiere rotar a través de cientos de proxies, como proxies residenciales o de centros de datos.
Mi sitio preferido para comprar proxies es: https://decodo.com
Es una plataforma de confianza que he utilizado para la búsqueda de errores, con un servicio de atención al cliente muy receptivo. A fecha de 11 de julio de 2025, el coste de 100 proxies es de 3,80 dólares:
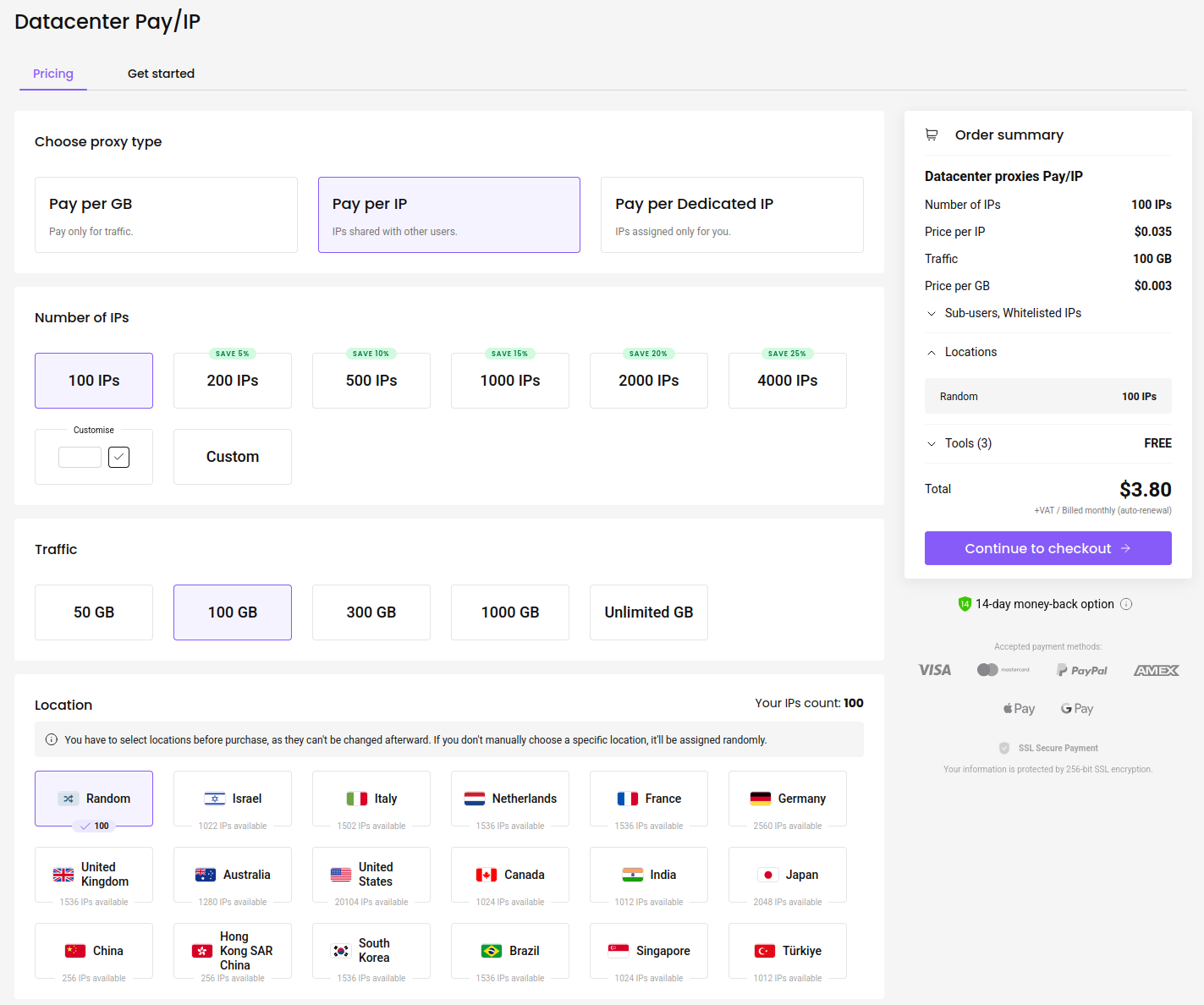
Es bastante barato. Una vez que hayas comprado los proxies, así es como puedes utilizarlos:
import requests
REQUEST_COUNT = 29
PROXY_CHANGE_INTERVAL = 5
proxies_list = [
"http://sp96rgc8yz:[email protected]:10001",
"http://sp96rgc8yz:[email protected]:10002",
"http://sp96rgc8yz:[email protected]:10003",
"http://sp96rgc8yz:[email protected]:10004",
"http://sp96rgc8yz:[email protected]:10005",
"http://sp96rgc8yz:[email protected]:10006"
]
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
proxy_index = 0
request_count = 0
while True:
current_proxy = proxies_list[proxy_index % len(proxies_list)]
proxies = {
"http": current_proxy,
"https": current_proxy
}
response = requests.get(url, cookies=cookies, proxies=proxies)
print(f"Request number: {request_count + 1} | Proxy: {current_proxy} | HTTP Status code: {response.status_code}")
request_count += 1
# Change proxy every 5 requests
if request_count % PROXY_CHANGE_INTERVAL == 0:
proxy_index += 1
El programa funciona en un bucle infinito «while True», seleccionando un proxy de la lista mediante una operación modular («proxy_index % len(proxies_list)») para volver al primer proxy después del último. Aplica el proxy seleccionado a los protocolos HTTP y HTTPS. Después de cada cinco solicitudes, incrementa «proxy_index» para cambiar al siguiente proxy, reiniciando desde el primer proxy cuando se alcanza el final de «proxies_list».
Omisión de captchas
Los captchas son probablemente el tema más interesante de este módulo y seguramente la razón por la que muchos de vosotros estáis aquí. Al igual que analizamos las páginas web antes de extraerlas, podemos estudiar cómo funcionan los CAPTCHA antes de omitirlos.
Para comprender los CAPTCHA, visita la página de inicio de sesión donde suelen aparecer:
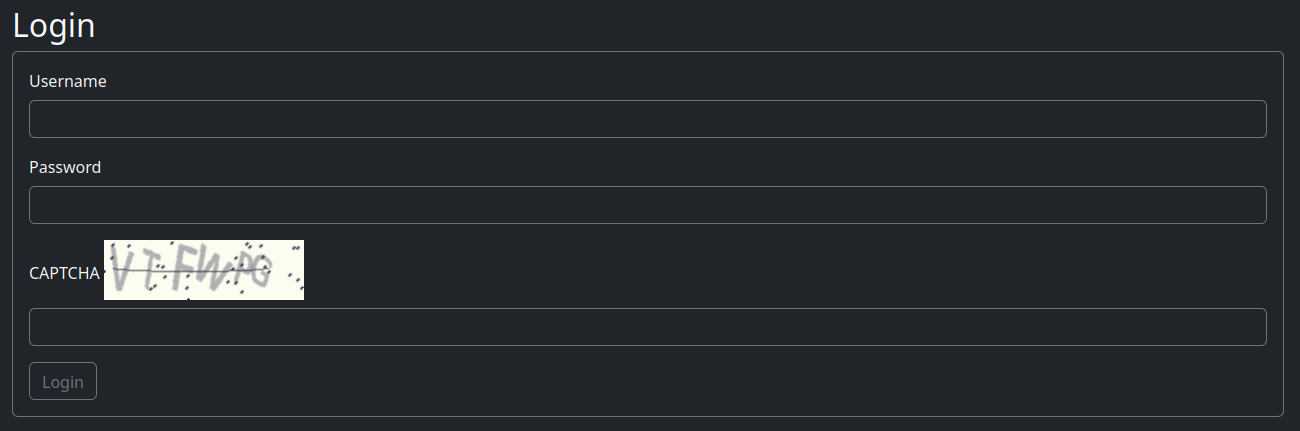
Vuelve a cargar la página varias veces para observar:
-
¿Cuántos caracteres utiliza cada CAPTCHA? 6 caracteres
-
¿Qué tipos de caracteres se utilizan (minúsculas, mayúsculas, mixtos, números)? Todas las letras mayúsculas y números
-
¿Cuál es el tamaño de la imagen del CAPTCHA? Descárgala, ábrela en Chrome y toma nota de que tiene 200 píxeles de ancho por 60 píxeles de alto
-
¿Cuál es la resolución máxima al cambiar el tamaño de la imagen del CAPTCHA? Cambiar el tamaño mejora la legibilidad de los caracteres
Aquí hay una versión redimensionada del CAPTCHA de inicio de sesión:

¿No es más claro y fácil de leer?
Así es como le pido a ChatGPT o3 que extraiga el texto con precisión:
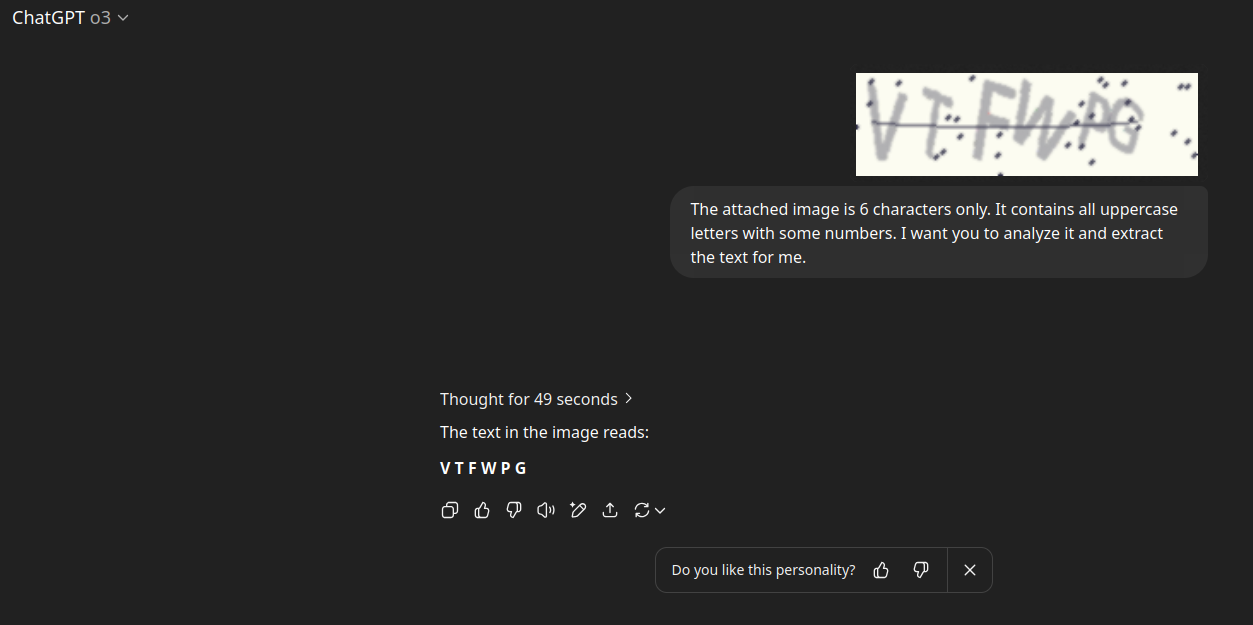
Este proceso puede llevar tiempo, a veces 49 segundos o hasta un minuto, pero el OCR de ChatGPT o3 es minucioso, aunque en ocasiones inconsistente. Opcionalmente, puedes analizar el CAPTCHA varias veces y seleccionar el resultado con la puntuación de confianza más alta.
Afortunadamente, los CAPTCHA solo se utilizan normalmente en las páginas de inicio de sesión y registro de la mayoría de los foros, por lo que no siempre es necesario sortearlos de forma exhaustiva. En nuestro sitio web principal de scraping, cuando se añade una cuenta de bot, iniciamos sesión automáticamente, sorteamos el CAPTCHA y creamos una sesión. Si la sesión caduca, volvemos a iniciar sesión con las credenciales. Si el inicio de sesión falla debido a un CAPTCHA incorrecto, lo intentamos hasta que se realiza correctamente.
Una limitación del uso de o3 es que su modelo API OpenAI no admite el procesamiento de imágenes. En secciones posteriores exploraremos modelos con soporte de imágenes y acceso a API.
En las próximas secciones, aprenderás cómo utilizamos el modelo gpt-4.1 para realizar intentos de inicio de sesión continuos, que normalmente tienen éxito después de cinco intentos consecutivos, como descubrirás más adelante.
Bloqueo de cuentas
Los bloqueos o prohibiciones de cuentas suelen ser manuales, pero a veces pueden automatizarse. Muchos foros de ciberdelincuencia combaten a los estafadores incluyendo en listas negras los nombres de usuario específicos. Por ejemplo, publicar un nombre de usuario de Telegram como @BluePig puede provocar una prohibición automática.
He observado esto con frecuencia, por lo que cambiar entre varias cuentas no siempre resuelve el problema. Sin embargo, si te encuentras con bloqueos automáticos, rotar entre cuentas es una estrategia viable.
Algunos sitios emplean sistemas de registro automatizados que alertan a los administradores de actividades sospechosas, como solicitudes excesivas o comportamientos potencialmente maliciosos.
En nuestro rastreador web principal, implementaremos la rotación de cuentas utilizando varias cuentas de bot para evitar bloqueos. Aunque los sitios de prueba de este curso carecen de mecanismos de bloqueo de cuentas, te enseñaremos cómo eludir estas protecciones para prepararte para situaciones reales.
El siguiente código Python muestra cómo cambiar entre dos cuentas e imprimir la página de perfil de cada cuenta como prueba de concepto de la rotación de cuentas.
Cuando se inicia sesión como «DarkHacker», la página de perfil muestra «Has iniciado sesión como DarkHacker». Este mensaje no aparece al visitar las páginas de perfil de otros usuarios, lo que confirma tu estado de inicio de sesión. A continuación se muestra cómo verificamos esto mediante programación cambiando entre cuentas:
import requests
# JSON structure for profiles
profiles = {
"url": "http://127.0.0.1:5000/profile/",
"users": {
"CyberGhost": {
"cookie": "session=.eJwtzrkRwjAQAMBeFBNIJ-keN-PRfWNSG0cMvUPAVrDvsucZ11G213nHo-xPL1uBabksGWtPVu-1CgCBKzZhnzEU3ZQRuSG2aYvSCCVpVfAqg5S7-gAMmTJGl-k5slVzRgBvJKa0IJPDa8zRsmnajFTI3knKL3Jfcf435fMFvlsvkA.aHFScA.HYZ0jgZ5eb06WP5SzPnnf6pISJo"
},
"DarkHacker": {
"cookie": "session=.eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHFR-A.mcu8L_CTLdZrz2254OEzZhsqpbQ"
}
}
}
# Function to fetch profile and check for login string
def fetch_profile(username, cookie):
url = f"{profiles['url']}{username}"
headers = {'Cookie': cookie}
try:
response = requests.get(url, headers=headers)
# Check for the login confirmation string
login_string = f"You are logged in as {username}"
if login_string in response.text:
print(f"Confirmation: '{login_string}' found in the response for user: {username}.")
else:
print(f"Confirmation: '{login_string}' NOT found in the response.")
except requests.RequestException as e:
print(f"Error fetching profile for {username}: {e}")
# Fetch profiles for both users
for username, data in profiles['users'].items():
fetch_profile(username, data['cookie'])
Salida:
-> % python3 profile_rotation.py
Confirmation: 'You are logged in as CyberGhost' found in the response for user: CyberGhost.
Confirmation: 'You are logged in as DarkHacker' found in the response for user: DarkHacker.
Puedes mejorar la experiencia de aprendizaje enumerando las publicaciones de cada cuenta, pero el enfoque actual es suficiente. Cambiar de cuenta es una estrategia eficaz para evitar ser marcado por actividad sospechosa, ya que todas las solicitudes enviadas al sitio web se registran.