En esta sección, explicaré cómo supervisar continuamente las amenazas durante un periodo prolongado sin intervención manual. El objetivo es sencillo: crear objetivos con prioridades específicas, definiendo el tipo de datos que se van a recopilar y la frecuencia de la supervisión.
Este módulo es lo más parecido a enseñar técnicas de vigilancia que puedo hacer legalmente. Mi intención no es promover la vigilancia; sin embargo, la supervisión es una práctica habitual en la inteligencia sobre amenazas. Muchas suites de inteligencia sobre amenazas para las fuerzas del orden incluyen la supervisión multiplataforma en múltiples foros y sitios web para rastrear la actividad de los usuarios, pero aquí no exploraremos ese nivel de complejidad.
Los temas de esta sección incluyen lo siguiente:
- Componentes del rastreador de perfiles
- Modelos de bases de datos
- Backend de la lista de vigilancia
- Plantilla para crear listas de vigilancia
- Plantilla para mostrar los resultados de la lista de vigilancia
- Pruebas
Componentes del rastreador de perfiles
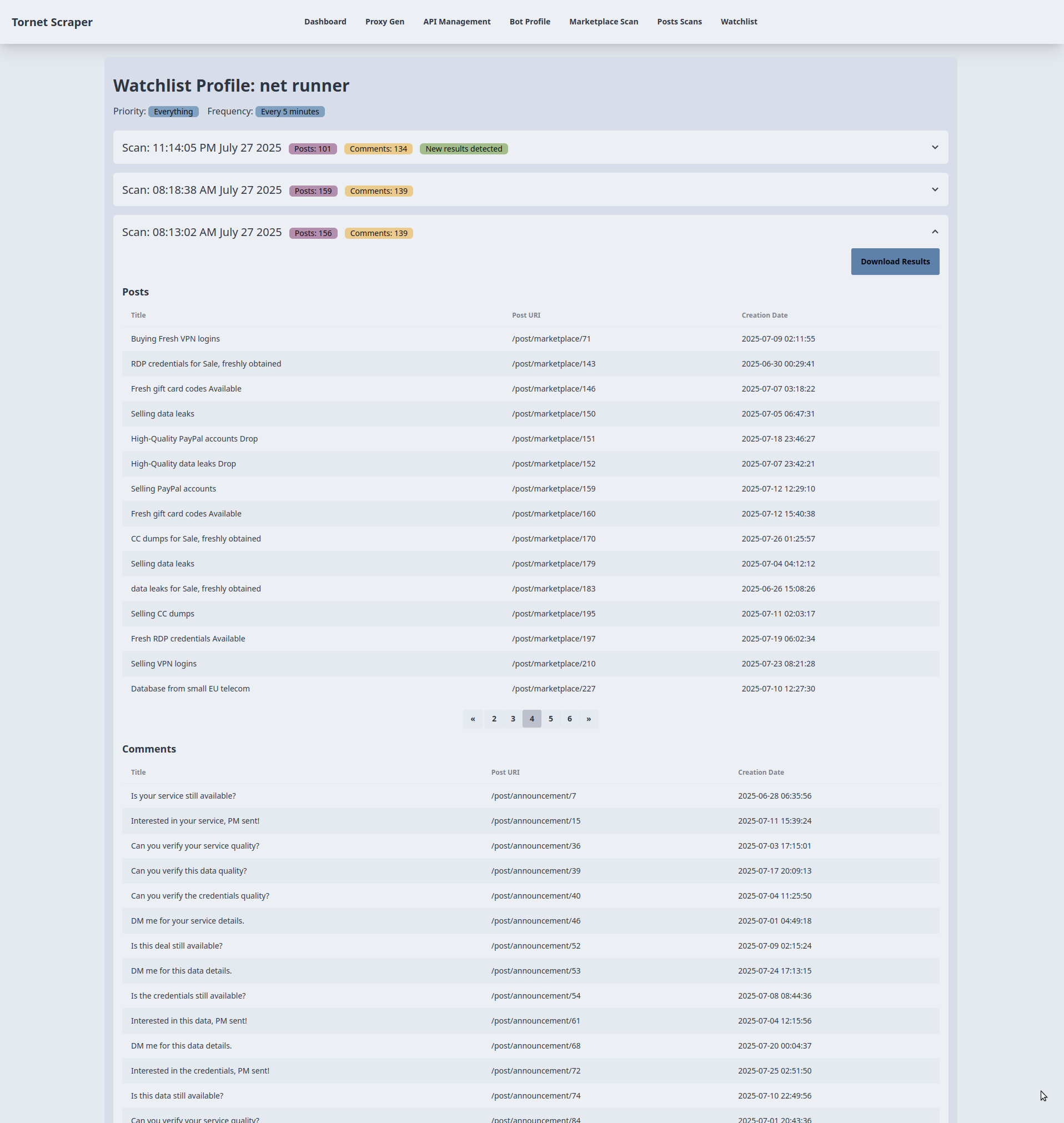
En el tornet_forum, los perfiles de los usuarios muestran los comentarios y las publicaciones en una tabla, lo que nos permite ver toda la actividad de los usuarios y acceder a los enlaces de las publicaciones que han comentado o creado.
Aquí hay un ejemplo de una página de perfil:

En app/scrapers/profile_scraper.py, la función scrape_profile acepta un parámetro llamado scrape_option, que define la prioridad de raspado: everything (todo), comments (solo comentarios) o posts (solo publicaciones).
Los datos del perfil se extraen según la frecuencia especificada, por ejemplo, cada 5 minutos, cada hora o cada 24 horas.
1. scrape_profile:
- Finalidad: extrae los detalles del perfil, las publicaciones y los comentarios de una URL de perfil especificada mediante el rastreo web con BeautifulSoup.
- Parámetros clave:
url: URL de la página de perfil que se va a extraer.session_cookie: Cookie de autenticación para acceder a la página.user_agent: Cadena de agente de usuario para los encabezados de solicitud HTTP.tor_proxy: Dirección proxy para el enrutamiento Tor.scrape_option: Especifica qué extraer: «comments», «posts» o «everything» (por defecto).
- Devuelve: Diccionario serializable en JSON con los detalles del perfil, las publicaciones, los comentarios y su recuento, o un diccionario de errores si falla el rastreo.
- Parámetros clave:
Más adelante, utilizaremos esta función para rastrear los datos del perfil. Ten en cuenta que nos centramos en extraer los títulos de las publicaciones, las URL y las marcas de tiempo, no el contenido completo de las publicaciones o los comentarios.
Modelos de base de datos
Necesitamos dos tablas: una para gestionar todos los objetivos y otra para almacenar los datos de cada objetivo.
Puedes encontrar estas tablas definidas en app/database/models.py:
class Watchlist(Base):
__tablename__ = "watchlists"
id = Column(Integer, primary_key=True, index=True)
target_name = Column(String, unique=True, index=True)
profile_link = Column(String)
priority = Column(String)
frequency = Column(String)
timestamp = Column(DateTime, default=datetime.utcnow)
class WatchlistProfileScan(Base):
__tablename__ = "watchlist_profile_scans"
id = Column(Integer, primary_key=True, index=True)
watchlist_id = Column(Integer, ForeignKey("watchlists.id"), nullable=False)
scan_timestamp = Column(DateTime, default=datetime.utcnow)
profile_data = Column(JSON)
Almacenamos todos los datos del perfil de usuario como una única cadena JSON completa.
Backend de la lista de seguimiento
El código del backend se encuentra en app/routes/watchlist.py. Aunque el código es extenso y complejo, céntrate en los dos diccionarios clave siguientes:
# Map stored frequency values to labels
FREQUENCY_TO_LABEL = {
"every 5 minutes": "critical",
"every 1 hour": "very high",
"every 6 hours": "high",
"every 12 hours": "medium",
"every 24 hours": "low"
}
# Map frequency labels to intervals (in seconds)
FREQUENCY_MAP = {
"critical": 5 * 60,
"very high": 60 * 60,
"high": 6 * 60 * 60,
"medium": 12 * 60 * 60,
"low": 24 * 60 * 60
}
La frecuencia determina la periodicidad con la que se recopilan los perfiles. Una prioridad crítica activa escaneos cada 5 minutos, mientras que una prioridad baja indica un objetivo menos urgente, con perfiles recopilados cada 24 horas.
Funciones principales en watchlist.py
-
schedule_all_tasks(db: Session):- Propósito: programa las tareas de rastreo para todos los elementos de la lista de seguimiento durante el inicio de la aplicación.
- Funcionalidad: consulta todos los elementos de
Watchlistde la base de datos y llama aschedule_taskpara cada elemento con el fin de configurar tareas de rastreo periódicas. - Parámetros clave:
db: sesión de la base de datos SQLAlchemy.
- Devuelve: Ninguno. Registra el número de tareas programadas o errores.
- Notas: Gestiona las excepciones para evitar fallos de inicio y registra los errores para su depuración.
-
schedule_task(db: Session, watchlist_item: Watchlist):- Propósito: Programa una tarea de scraping recurrente para un elemento específico de la lista de seguimiento.
- Funcionalidad: Asigna la frecuencia del elemento a un intervalo (por ejemplo, «cada 24 horas» a 86 400 segundos) y programa una tarea utilizando APScheduler para ejecutar
scrape_and_saveen el intervalo especificado. - Parámetros clave:
db: Sesión de la base de datos SQLAlchemy.watchlist_item: objetoWatchlistque contiene los detalles del elemento.
- Devuelve: Ninguno. Registra los detalles de la programación (por ejemplo, ID del elemento, intervalo).
- Notas: Utiliza
FREQUENCY_TO_LABELyFREQUENCY_MAPpara la asignación de frecuencias a intervalos.
-
scrape_and_save(watchlist_id: int, db: Session = None):- Propósito: Realiza una única operación de scraping para un elemento de la lista de seguimiento y guarda los resultados.
- Funcionalidad: Recupera el elemento de la lista de seguimiento y un bot aleatorio con el propósito
SCRAPE_PROFILEde la base de datos, llama ascrape_profilecon las credenciales del bot y almacena el resultado enWatchlistProfileScan. Crea una nueva sesión de base de datos si no se proporciona ninguna. - Parámetros clave:
watchlist_id: ID del elemento de la lista de seguimiento que se va a extraer.db: Sesión de base de datos SQLAlchemy opcional.
- Devuelve: Ninguno. Registra el éxito, los errores o los resultados vacíos y envía los datos a la base de datos.
- Notas: Gestiona el análisis de las cookies de sesión, valida los resultados del rastreo y garantiza la limpieza adecuada de la sesión.
-
get_watchlist(db: Session):- Propósito: Recupera todos los elementos de la lista de seguimiento.
- Funcionalidad: Consulta la tabla
Watchlisty devuelve todos los elementos como una lista de objetosWatchlistResponse. - Parámetros clave:
db: Sesión de la base de datos SQLAlchemy (a través deDepends(get_db)).
- Devuelve: Lista de objetos
WatchlistResponse. - Notas: Genera un error HTTP 500 con registro si la consulta falla.
-
get_watchlist_item(item_id: int, db: Session):- Propósito: Recupera un único elemento de la lista de seguimiento por ID.
- Funcionalidad: Consulta la tabla
Watchlisten busca delitem_idespecificado y devuelve el elemento como un objetoWatchlistResponse. - Parámetros clave:
item_id: ID del elemento de la lista de seguimiento.db: Sesión de la base de datos SQLAlchemy.
- Devuelve: objeto
WatchlistResponseo genera un error HTTP 404 si no se encuentra. - Notas: registra los errores y genera un error HTTP 500 si se producen problemas inesperados.
-
create_watchlist_item(item: WatchlistCreate, db: Session):- Propósito: crea un nuevo elemento de la lista de seguimiento y programa su tarea de scraping.
- Funcionalidad: Valida que el
target_namesea único, crea una entradaWatchlist, ejecuta un escaneo inmediato si no existen escaneos y programa escaneos futuros utilizandoschedule_task. - Parámetros clave:
item: Modelo PydanticWatchlistCreatecon detalles del elemento.db: Sesión de base de datos SQLAlchemy.
- Devuelve: Objeto
WatchlistResponsepara el elemento creado. - Notas: Genera un error HTTP 400 si
target_nameexiste, y un error HTTP 500 para otros errores.
-
update_watchlist_item(item_id: int, item: WatchlistUpdate, db: Session):- Propósito: Actualiza un elemento de la lista de seguimiento existente y reprograma su tarea de scraping.
- Funcionalidad: verifica que el elemento existe y que
target_namees único (excluyendo el elemento actual), actualiza los campos y llama aschedule_taskpara ajustar la programación del rastreo. - Parámetros clave:
item_id: ID del elemento de la lista de seguimiento.item: modeloWatchlistUpdatede Pydantic con los detalles actualizados.db: Sesión de la base de datos SQLAlchemy.
- Devuelve: Objeto
WatchlistResponseactualizado. - Notas: Genera un error HTTP 404 si no se encuentra el elemento, HTTP 400 si hay un
target_nameduplicado o HTTP 500 si se produce un error.
-
delete_watchlist_item(item_id: int, db: Session):- Propósito: Elimina un elemento de la lista de seguimiento y sus exploraciones asociadas.
- Funcionalidad: Elimina el elemento de
Watchlist, sus exploraciones deWatchlistProfileScany la tarea APScheduler correspondiente. - Parámetros clave:
item_id: ID del elemento de la lista de seguimiento.db: Sesión de la base de datos SQLAlchemy.
- Devuelve: respuesta JSON con mensaje de éxito.
- Notas: genera un error HTTP 404 si no se encuentra el elemento y un error HTTP 500 si se produce un error. Ignora los trabajos del programador que faltan.
-
get_profile_scans(watchlist_id: int, db: Session):- Finalidad: recupera todos los resultados de escaneo de un elemento de la lista de seguimiento.
- Funcionalidad: Consulta
WatchlistProfileScanen busca de escaneos que coincidan conwatchlist_id, ordenados por marca de tiempo (descendente), y los devuelve como objetosWatchlistProfileScanResponse. - Parámetros clave:
watchlist_id: ID del elemento de la lista de seguimiento.db: sesión de la base de datos SQLAlchemy.
- Devuelve: lista de objetos
WatchlistProfileScanResponse. - Notas: genera un error HTTP 500 si se producen errores en la consulta.
-
download_scan(scan_id: int, db: Session):- Finalidad: descarga los datos del perfil de un escaneo como un archivo JSON.
- Funcionalidad: recupera el escaneo por
scan_id, escribe suprofile_dataen un archivo JSON temporal y lo devuelve como unFileResponse. - Parámetros clave:
scan_id: ID del escaneo que se va a descargar.db: sesión de la base de datos SQLAlchemy.
- Devuelve:
FileResponsecon el archivo JSON. - Notas: Genera un error HTTP 404 si no se encuentra el escaneo, y un error HTTP 500 si se produce un error.
-
startup_event():- Propósito: Inicializa APScheduler al iniciar la aplicación.
- Funcionalidad: comprueba si el programador no se está ejecutando, crea una sesión de base de datos, llama a
schedule_all_taskspara programar todos los elementos de la lista de seguimiento e inicia el programador. - Parámetros clave: ninguno.
- Devuelve: ninguno. Registra el estado del programador.
- Notas: Asegura que el programador se inicia solo una vez para evitar trabajos duplicados.
Si no estás satisfecho con las frecuencias predeterminadas, puedes modificarlas en watchlist.py. Para mantener la coherencia, también tendrás que actualizar las plantillas en consecuencia. Sin embargo, si estás ajustando las frecuencias con fines de depuración, puedes modificarlas únicamente en watchlist.py sin alterar las plantillas.
Plantilla para crear listas de seguimiento
La plantilla que utilizaremos es una tabla CRUD sencilla, para que sea simple y funcional. Puede revisarla abriendo app/templates/watchlist.html.
-
Creación de elementos de la lista de seguimiento:
- Propósito: Añade un nuevo elemento a la lista de seguimiento para supervisar un perfil de destino.
- Interacción con el backend:
- El botón «Nueva amenaza» abre un modal (
newThreatModal) con campos para el nombre del objetivo, el enlace del perfil (URL), la prioridad (todo,publicaciones,comentarios) y la frecuencia (cada 24 horas,cada 12 horas, etc.).. - El envío del formulario (
newThreatForm) valida el enlace del perfil y envía una solicitud AJAX POST a/api/watchlist-api/items(gestionada porwatchlist_api_router) con los datos del formulario. - El backend crea un registro «Watchlist», lo guarda en la base de datos y devuelve una respuesta de éxito. Si se realiza correctamente, se cierra el modal, se restablece el formulario y «loadWatchlist()» actualiza la tabla. Los errores activan una alerta.
- El botón «Nueva amenaza» abre un modal (
-
Listado y actualización de elementos de la lista de seguimiento:
- Objetivo: muestra y actualiza una tabla con los elementos de la lista de seguimiento.
- Interacción con el backend:
- La función
loadWatchlist(), llamada al cargar la página y al pulsar el botón «Actualizar tabla», envía una solicitud AJAX GET a/api/watchlist-api/items(gestionada porwatchlist_api_router). - El backend devuelve una lista de registros
Watchlist(ID, nombre del objetivo, enlace al perfil, prioridad, frecuencia, marca de tiempo). La tabla se rellena con estos detalles y muestra «No se han encontrado elementos» si está vacía. Los errores activan una alerta y muestran un mensaje de error en la tabla.
- La función
-
Edición de elementos de la lista de seguimiento:
- Finalidad: Actualiza un elemento existente de la lista de seguimiento.
- Interacción con el backend:
- El botón «Editar» de cada fila de la tabla recupera los datos del elemento mediante una solicitud AJAX GET a
/api/watchlist-api/items/{id}(gestionada porwatchlist_api_router) y rellena eleditThreatModalcon los valores actuales. - El envío del formulario (
editThreatForm) valida el enlace del perfil y envía una solicitud AJAX PUT a/api/watchlist-api/items/{id}con los datos actualizados. - El backend actualiza el registro
Watchlist. Si se realiza correctamente, se cierra el modal yloadWatchlist()actualiza la tabla. Los errores activan una alerta.
- El botón «Editar» de cada fila de la tabla recupera los datos del elemento mediante una solicitud AJAX GET a
-
Eliminación de elementos de la lista de seguimiento:
- Objetivo: Elimina un elemento de la lista de seguimiento.
- Interacción con el backend:
- El botón «Eliminar» de cada fila de la tabla solicita confirmación y envía una solicitud AJAX DELETE a
/api/watchlist-api/items/{id}(gestionada porwatchlist_api_router). - El backend elimina el registro
Watchlist. Si se realiza correctamente,loadWatchlist()actualiza la tabla. Los errores activan una alerta.
- El botón «Eliminar» de cada fila de la tabla solicita confirmación y envía una solicitud AJAX DELETE a
-
Visualización de los resultados de la lista de seguimiento:
- Finalidad: Redirige a una página de resultados para el perfil de un elemento de la lista de seguimiento.
- Interacción con el backend:
- El botón «Ver resultados» de cada fila de la tabla enlaza con
/watchlist-profile/{id}(gestionado pormain.py::watchlist_profile). - El backend renderiza una plantilla con los resultados de los datos de monitorización del elemento de la
lista de seguimiento(por ejemplo, publicaciones o comentarios). No se realiza ninguna llamada AJAX directa, pero la redirección depende de la recuperación de datos del backend.
- El botón «Ver resultados» de cada fila de la tabla enlaza con
Plantilla para mostrar los resultados de la lista de seguimiento
Necesitamos una plantilla específica para mostrar los resultados de cada objetivo, ya que manejamos un gran volumen de datos que deben organizarse por fecha para mayor claridad.
-
Visualización de los resultados del escaneo:
- Finalidad: muestra los resultados del escaneo de un elemento de la lista de seguimiento en secciones de acordeón.
- Interacción con el backend:
- La plantilla recibe
watchlist_item(nombre del objetivo, prioridad, frecuencia) yscans(lista de datos del escaneo conprofile_dataque contiene publicaciones y comentarios) demain.py::watchlist_profile. - Cada acordeón representa un escaneo y muestra la marca de tiempo del escaneo, el recuento de publicaciones y el recuento de comentarios (de «profile_data»). Aparece una insignia «Se han detectado nuevos resultados» si el recuento de publicaciones o comentarios del último escaneo difiere del escaneo anterior. Los datos se representan utilizando Jinja2 sin llamadas API adicionales.
- La plantilla recibe
-
Tablas de publicaciones y comentarios:
- Finalidad: muestra hasta 15 publicaciones y comentarios por escaneo en tablas separadas.
- Interacción con el backend:
- Para cada escaneo, las publicaciones (
profile_data.posts) y los comentarios (profile_data.comments) se representan en tablas con columnas para el título, la URL y la fecha de creación (o el texto del comentario en el caso de los comentarios). Si no hay datos, se muestra el mensaje «No se han encontrado publicaciones/comentarios». - Los datos se precargan desde el backend a través de
main.py::watchlist_profile, por lo que no se necesitan más solicitudes API para renderizar las tablas.
- Para cada escaneo, las publicaciones (
-
Paginación para conjuntos de datos grandes:
- Finalidad: Gestiona la paginación de los escaneos con más de 15 publicaciones o comentarios.
- Interacción con el backend:
- Para las tablas que superan los 15 elementos, se renderiza un grupo de botones de paginación con hasta 5 botones de página, utilizando
data-items(publicaciones/comentarios codificados en JSON) ydata-total-pagesdeprofile_data.post_countocomment_count. - La función
changePage()gestiona la paginación del lado del cliente, dividiendo los datos JSON para mostrar 15 elementos por página sin llamadas adicionales al backend. Actualiza dinámicamente los botones de página y el contenido de la tabla en función de la navegación del usuario (clics en anterior/siguiente o en el número de página).
- Para las tablas que superan los 15 elementos, se renderiza un grupo de botones de paginación con hasta 5 botones de página, utilizando
-
Descarga de los resultados del escaneo:
- Objetivo: exportar los resultados del escaneo como un archivo.
- Interacción con el backend:
- Cada acordeón de escaneo incluye un botón «Descargar resultados» que enlaza con
/api/watchlist-api/download-scan/{scan.id}(gestionado porwatchlist_api_router). - El backend genera un archivo descargable (por ejemplo, JSON o CSV) que contiene los
profile_datadel escaneo (publicaciones y comentarios). El enlace activa una descarga directa sin AJAX, basándose en el procesamiento del backend.
- Cada acordeón de escaneo incluye un botón «Descargar resultados» que enlaza con
He elegido los acordeones para organizar los resultados del escaneo por marca de tiempo, ya que creo que es el enfoque más eficaz para gestionar grandes conjuntos de datos. Aunque es posible que prefieras otro método, el formato de acordeón ofrece una visualización clara y eficaz.
No es necesario modificar la plantilla, ya que puedes exportar los datos como JSON y visualizarlos en cualquier formato fuera de tornet_scraper.
Pruebas
Para comenzar las pruebas, configura los siguientes componentes:
- Configura una API para resolver CAPTCHA.
- Cree un perfil de bot con el propósito establecido en
scrape_profilee inicie sesión para obtener una sesión. - Cree una lista de seguimiento utilizando la página
/watchlist.
Para crear una lista de seguimiento para supervisar una amenaza, proporcione lo siguiente:
- Nombre del objetivo: cualquier identificador de la amenaza.
- Enlace del perfil: en el formato «http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/profile/N3tRunn3r».
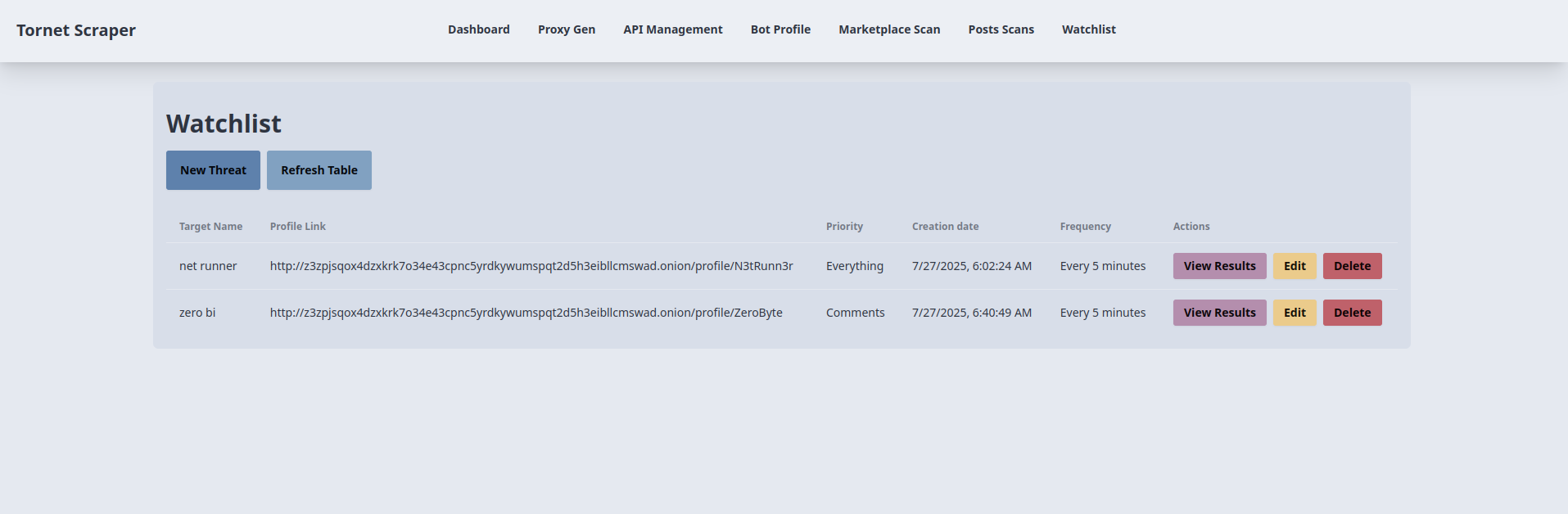
Vaya al menú «Lista de vigilancia», haga clic en «Nueva amenaza» e introduzca los detalles. Al añadir un objetivo por primera vez, es posible que la ventana modal se detenga brevemente mientras el backend inicia un análisis inicial. Este análisis inicial al crear un objetivo no es el comportamiento predeterminado del programador de tareas en «watchlist.py», sino una función personalizada que he implementado.
Así es como se muestran los objetivos:
A continuación se muestran los resultados de la supervisión. Para realizar la prueba, ajusté la frecuencia de programación crítica de cada 5 minutos a cada 1 minuto:
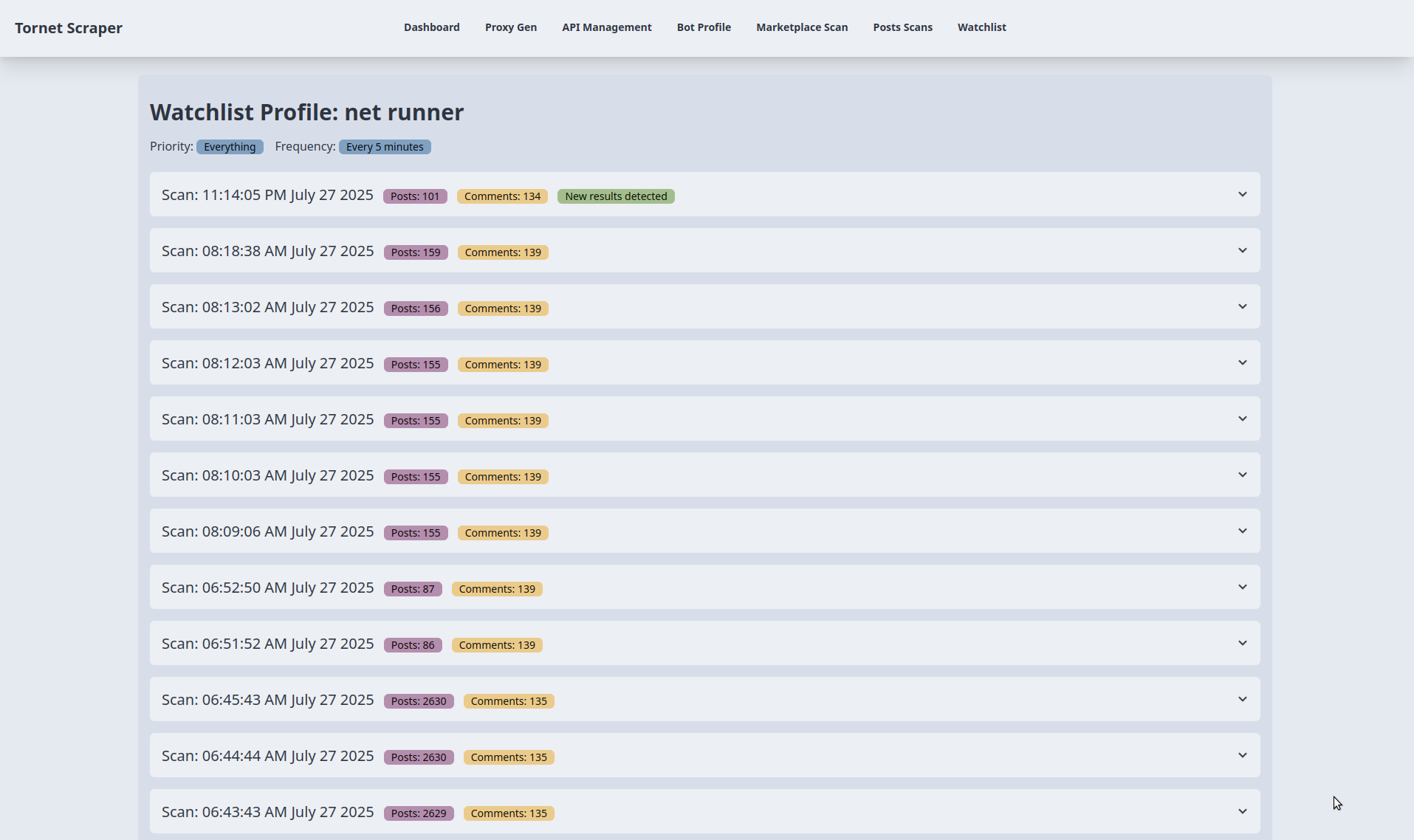
Puedes expandir cualquier acordeón para ver los resultados y descargarlos en formato JSON: