En esta sección, crearemos la funcionalidad principal del rastreador de datos para recopilar publicaciones.
La mayoría de los foros sobre ciberdelincuencia ofrecen acceso gratuito a todos los usuarios, con acceso de pago que desbloquea funciones como publicar en categorías específicas o realizar acciones adicionales. Cuando se utilizan cuentas gratuitas para el rastreo web, los foros suelen limitar el contenido que se puede ver o comentar en un periodo de 24 horas. Para solucionar esto, debes limitar las solicitudes y distribuir las tareas entre varias cuentas.
El tornet_forum incluye una categoría de mercado con contenido paginado. Cada página muestra una tabla con 10 filas, que representan 10 publicaciones. Si hay cientos de páginas, esto da como resultado un gran volumen de contenido que hay que recopilar a fondo sin perder ningún dato.
Aquí hay un ejemplo de la paginación del mercado:
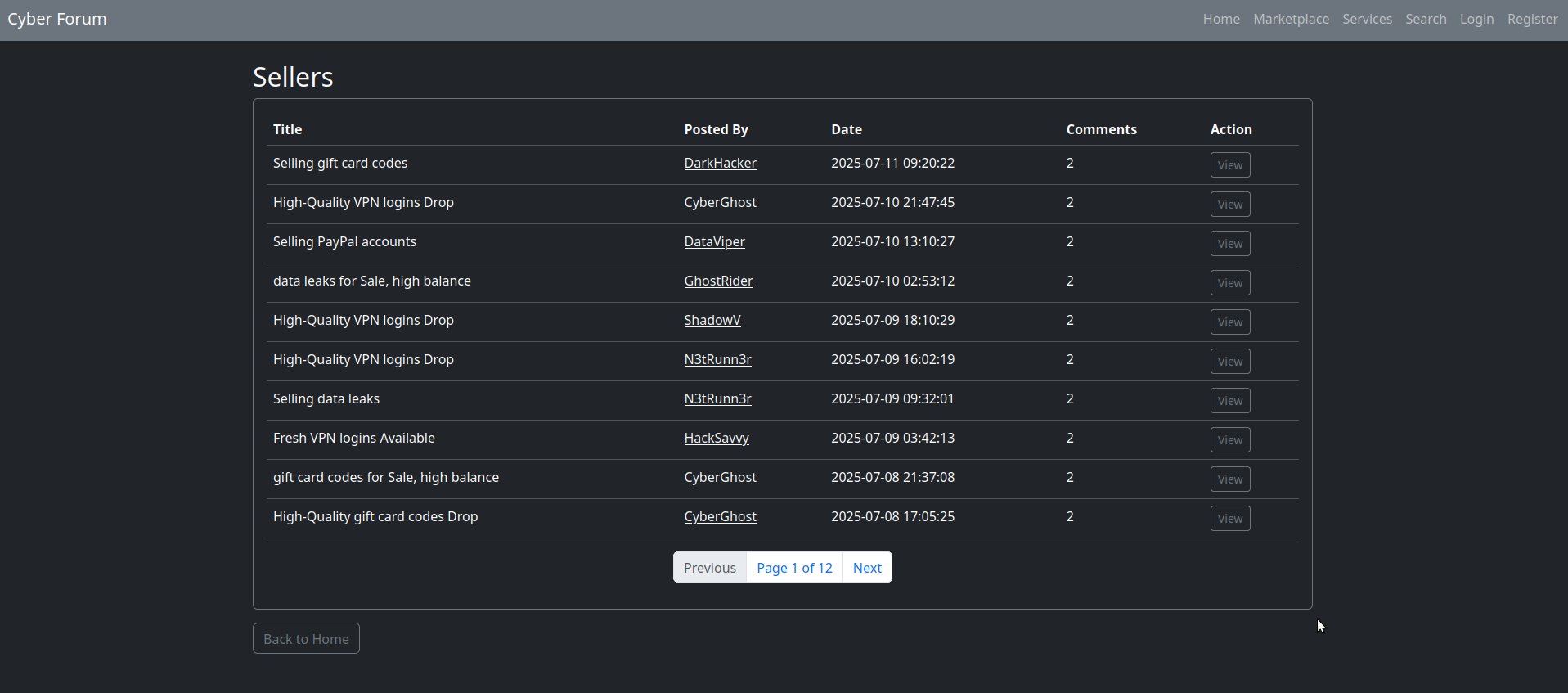
Mi enfoque consiste en crear un script que tome como entradas una URL de paginación y el número máximo de paginación. A continuación, genera una lista de URL de paginación, dividiéndolas en lotes de 10. Por ejemplo, si hay 12 páginas de paginación, el script crea dos lotes: uno con 10 URL de paginación y otro con 2. Dado que cada página contiene 10 publicaciones, cada bot extraerá 100 enlaces de publicaciones por lote de 10 páginas.
Aquí hay un ejemplo de una estructura de lotes:
http://127.0.0.1:5000/category/marketplace/Sellers?page=1
http://127.0.0.1:5000/category/marketplace/Sellers?page=2
http://127.0.0.1:5000/category/marketplace/Sellers?page=3
...
http://127.0.0.1:5000/category/marketplace/Sellers?page=10