Nesta secção, iremos construir a funcionalidade principal do scraper de dados para recolher publicações.
A maioria dos fóruns de cibercrime oferece acesso gratuito a todos os utilizadores, com acesso pago a funcionalidades como publicar em categorias específicas ou realizar ações adicionais. Ao utilizar contas gratuitas para web scraping, os fóruns limitam frequentemente o conteúdo que pode visualizar ou comentar num período de 24 horas. Para contornar isso, deve limitar as solicitações e distribuir as tarefas por várias contas.
O tornet_forum inclui uma categoria de mercado com conteúdo paginado. Cada página exibe uma tabela com 10 linhas, representando 10 publicações. Se houver centenas de páginas, isso resulta em um grande volume de conteúdo para raspar completamente sem perder nenhum dado.
Aqui está um exemplo da paginação do marketplace:
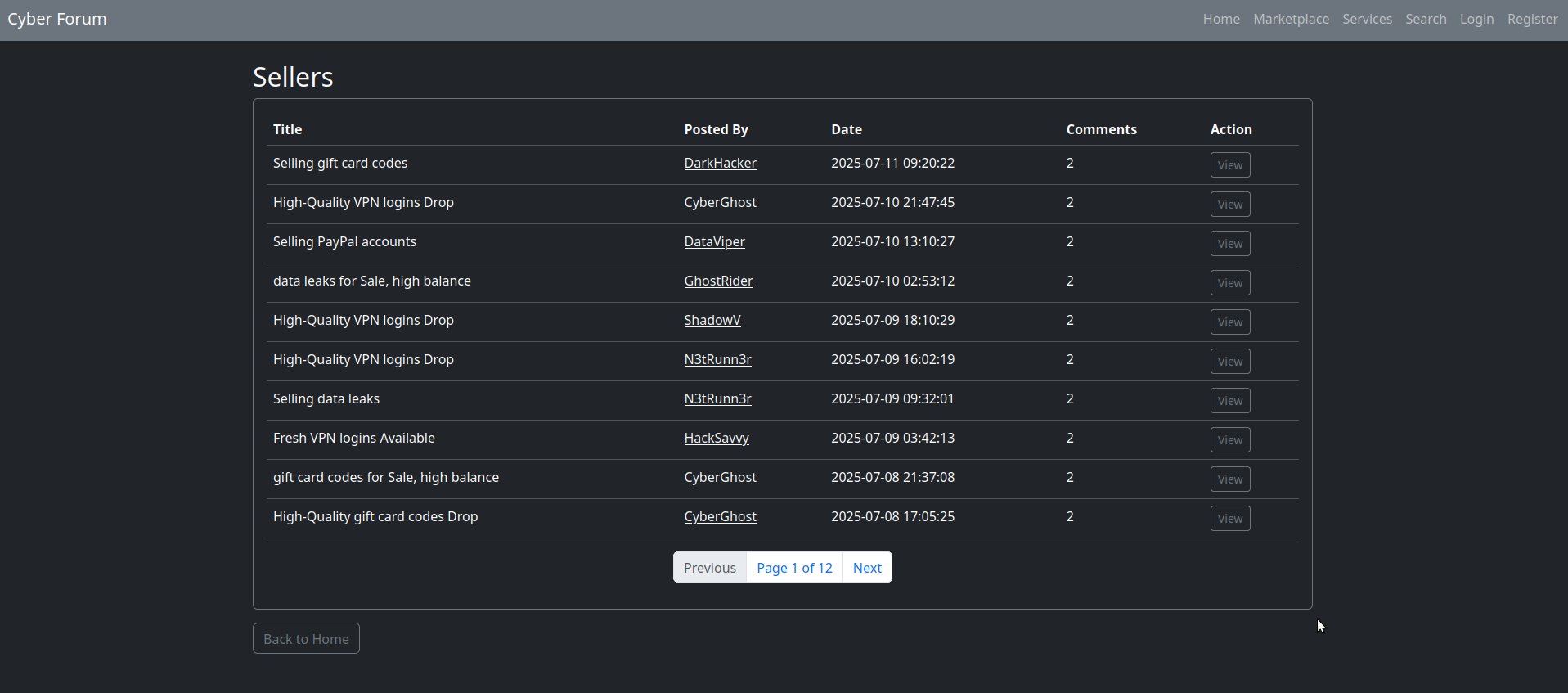
A minha abordagem é criar um script que receba uma URL de paginação e o número máximo de paginações como entradas. Em seguida, ele gera uma lista de URLs de paginação, dividindo-as em lotes de 10. Por exemplo, se houver 12 páginas de paginação, o script cria dois lotes: um com 10 URLs de paginação e outro com 2. Como cada página contém 10 publicações, cada bot irá extrair 100 links de publicações por lote de 10 páginas.
Aqui está um exemplo de uma estrutura de lote:
http://127.0.0.1:5000/category/marketplace/Sellers?page=1
http://127.0.0.1:5000/category/marketplace/Sellers?page=2
http://127.0.0.1:5000/category/marketplace/Sellers?page=3
...
http://127.0.0.1:5000/category/marketplace/Sellers?page=10