Nesta secção, explicarei como monitorizar continuamente ameaças durante um longo período sem intervenção manual. O objetivo é simples: criar alvos com prioridades específicas, definindo o tipo de dados a recolher e a frequência da monitorização.
Este módulo é o mais próximo que posso chegar legalmente de ensinar técnicas de vigilância. A minha intenção não é promover a vigilância; no entanto, o monitoramento é uma prática padrão em inteligência de ameaças. Muitos pacotes de inteligência de ameaças para aplicação da lei incluem monitoramento entre plataformas em vários fóruns e sites para rastrear a atividade do utilizador, mas não exploraremos esse nível de complexidade aqui.
Os tópicos desta seção incluem o seguinte:
- Componentes do scraper de perfis
- Modelos de banco de dados
- Back-end da lista de observação
- Modelo para criar listas de observação
- Modelo para exibir resultados da lista de observação
- Testes
Componentes do scraper de perfis
No tornet_forum, os perfis dos utilizadores exibem comentários e publicações numa tabela, permitindo-nos ver todas as atividades dos utilizadores e aceder a links para publicações que eles comentaram ou criaram.
Aqui está um exemplo de uma página de perfil:

Em app/scrapers/profile_scraper.py, a função scrape_profile aceita um parâmetro chamado scrape_option, que define a prioridade de raspagem: everything, comments apenas ou posts apenas.
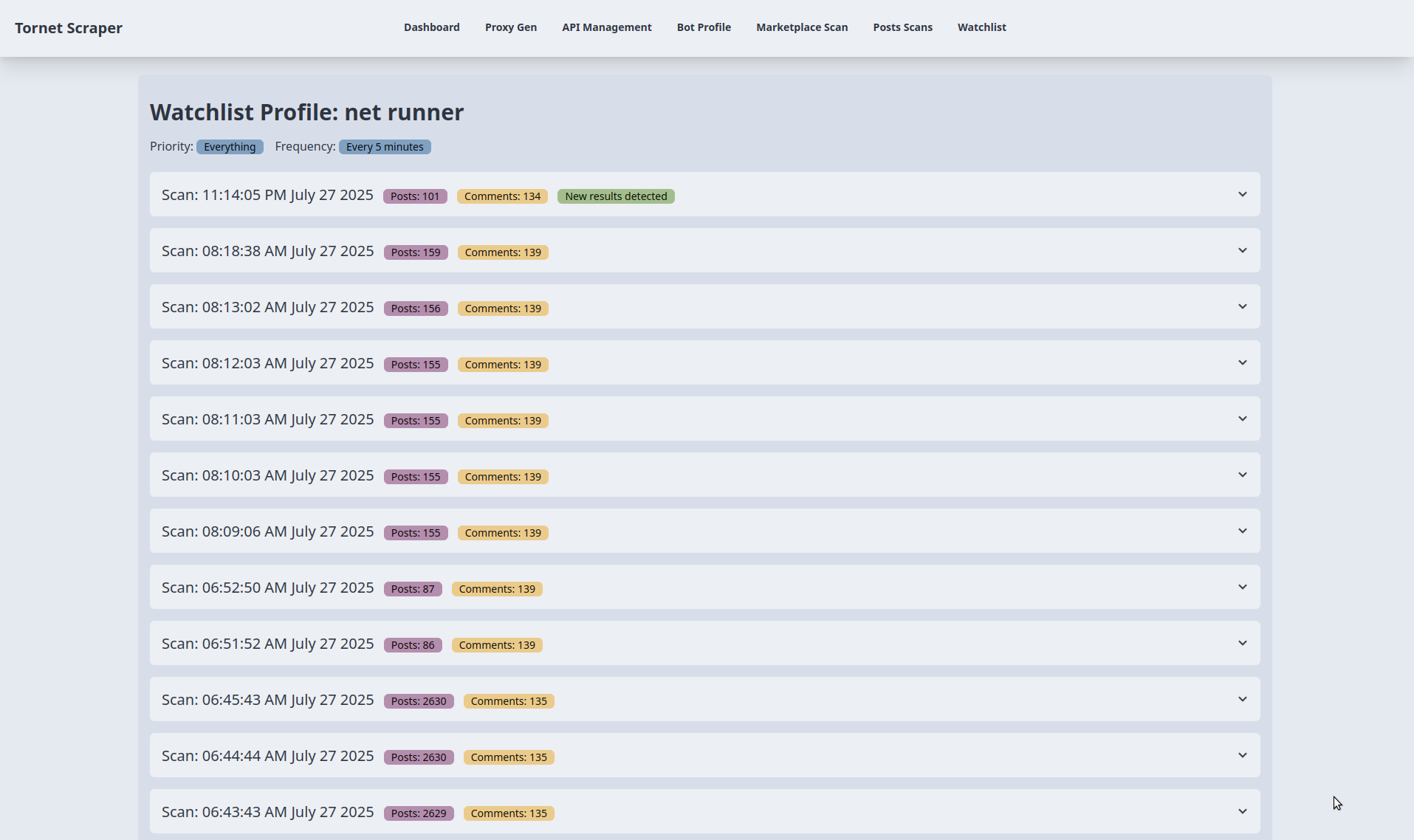
Os dados do perfil são extraídos com base em frequências especificadas, como a cada 5 minutos, 1 hora ou 24 horas.
1. scrape_profile:
- Objetivo: Extraia detalhes do perfil, publicações e comentários de um URL de perfil especificado usando web scraping com BeautifulSoup.
- Parâmetros-chave:
url: URL da página do perfil a ser extraída.session_cookie: Cookie de autenticação para aceder à página.user_agent: String do agente do utilizador para cabeçalhos de solicitação HTTP.tor_proxy: Endereço proxy para roteamento Tor.scrape_option: Especifica o que extrair: ‘comentários’, ‘publicações’ ou ‘tudo’ (padrão).- Retorna: Dicionário serializável em JSON com detalhes do perfil, publicações, comentários e suas contagens, ou um dicionário de erros se a extração falhar.
Mais tarde, usaremos esta função para extrair dados do perfil. Observe que nos concentramos em extrair títulos de publicações, URLs e carimbos de data/hora, não o conteúdo completo das publicações ou comentários.
Modelos de banco de dados
Precisamos de duas tabelas: uma para gerenciar todos os alvos e outra para armazenar dados para cada alvo.
Você pode encontrar essas tabelas definidas em app/database/models.py:
class Watchlist(Base):
__tablename__ = "watchlists"
id = Column(Integer, primary_key=True, index=True)
target_name = Column(String, unique=True, index=True)
profile_link = Column(String)
priority = Column(String)
frequency = Column(String)
timestamp = Column(DateTime, default=datetime.utcnow)
class WatchlistProfileScan(Base):
__tablename__ = "watchlist_profile_scans"
id = Column(Integer, primary_key=True, index=True)
watchlist_id = Column(Integer, ForeignKey("watchlists.id"), nullable=False)
scan_timestamp = Column(DateTime, default=datetime.utcnow)
profile_data = Column(JSON)
Armazenamos todos os dados do perfil do utilizador como uma única string JSON abrangente.
Backend da lista de observação
O código do backend está localizado em app/routes/watchlist.py. Embora o código seja substancial e complexo, concentre-se nos dois dicionários principais a seguir:
# Map stored frequency values to labels
FREQUENCY_TO_LABEL = {
"every 5 minutes": "critical",
"every 1 hour": "very high",
"every 6 hours": "high",
"every 12 hours": "medium",
"every 24 hours": "low"
}
# Map frequency labels to intervals (in seconds)
FREQUENCY_MAP = {
"critical": 5 * 60,
"very high": 60 * 60,
"high": 6 * 60 * 60,
"medium": 12 * 60 * 60,
"low": 24 * 60 * 60
}
A frequência determina a periodicidade com que os perfis são recolhidos. Uma prioridade crítica aciona varreduras a cada 5 minutos, enquanto uma prioridade baixa indica um alvo menos urgente, com perfis recolhidos a cada 24 horas.
Funções principais em watchlist.py
-
schedule_all_tasks(db: Session):- Objetivo: Agenda tarefas de recolha para todos os itens da lista de observação durante o arranque da aplicação.
- Funcionalidade: Consulta todos os itens da
Watchlistna base de dados e chamaschedule_taskpara cada item para configurar tarefas de recolha periódicas. - Parâmetros principais:
db: sessão da base de dados SQLAlchemy.
- Retorna: Nenhum. Regista o número de tarefas agendadas ou erros.
- Notas: trata exceções para evitar falhas de inicialização e regista erros para depuração.
-
schedule_task(db: Session, watchlist_item: Watchlist):- Objetivo: Agenda uma tarefa de scraping recorrente para um item específico da lista de observação.
- Funcionalidade: Mapeia a frequência do item para um intervalo (por exemplo, “a cada 24 horas” para 86.400 segundos) e agenda uma tarefa usando o APScheduler para executar
scrape_and_saveno intervalo especificado. - Parâmetros-chave:
db: sessão da base de dados SQLAlchemy.watchlist_item: objetoWatchlistcontendo detalhes do item.
- Retorna: Nenhum. Regista detalhes da programação (por exemplo, ID do item, intervalo).
- Notas: Utiliza
FREQUENCY_TO_LABELeFREQUENCY_MAPpara o mapeamento de frequência para intervalo.
-
scrape_and_save(watchlist_id: int, db: Session = None):- Objetivo: Executa uma única operação de scraping para um item da lista de observação e guarda os resultados.
- Funcionalidade: Recupera o item da lista de observação e um bot aleatório com a finalidade
SCRAPE_PROFILEda base de dados, chamascrape_profilecom as credenciais do bot e armazena o resultado emWatchlistProfileScan. Cria uma nova sessão da base de dados, se nenhuma for fornecida. - Parâmetros-chave:
watchlist_id: ID do item da lista de observação a ser raspado.db: Sessão de base de dados SQLAlchemy opcional.
- Retorna: Nenhum. Regista o sucesso, erros ou resultados vazios e envia os dados para a base de dados.
- Notas: Lida com a análise de cookies de sessão, valida os resultados da recolha e garante a limpeza adequada da sessão.
-
get_watchlist(db: Session):- Objetivo: Recupera todos os itens da lista de observação.
- Funcionalidade: Consulta a tabela
Watchliste retorna todos os itens como uma lista de objetosWatchlistResponse. - Parâmetros principais:
db: Sessão do banco de dados SQLAlchemy (viaDepends(get_db)).
- Retorna: Lista de objetos
WatchlistResponse. - Notas: Gera um erro HTTP 500 com registo se a consulta falhar.
-
get_watchlist_item(item_id: int, db: Session):- Objetivo: Recupera um único item da lista de observação pelo ID.
- Funcionalidade: Consulta a tabela
Watchlistpeloitem_idespecificado e retorna o item como um objetoWatchlistResponse. - Parâmetros-chave:
item_id: ID do item da lista de observação.db: Sessão do banco de dados SQLAlchemy.
- Retorna: Objeto
WatchlistResponseou gera um HTTP 404 se não for encontrado. - Notas: Regista erros e gera HTTP 500 para problemas inesperados.
-
create_watchlist_item(item: WatchlistCreate, db: Session):- Objetivo: Cria um novo item da lista de observação e agenda a sua tarefa de recolha.
- Funcionalidade: Valida se o
target_nameé único, cria uma entradaWatchlist, executa uma verificação imediata se não houver verificações e agenda verificações futuras usandoschedule_task. - Parâmetros principais:
item: Modelo PydanticWatchlistCreatecom detalhes do item.db: Sessão do banco de dados SQLAlchemy.
- Retorna: Objeto
WatchlistResponsepara o item criado. - Notas: Gera HTTP 400 se
target_nameexistir, HTTP 500 para outros erros.
-
update_watchlist_item(item_id: int, item: WatchlistUpdate, db: Session):- Objetivo: Atualiza um item da lista de observação existente e reagenda a sua tarefa de scraping.
- Funcionalidade: Verifica se o item existe e se
target_nameé único (excluindo o item atual), atualiza os campos e chamaschedule_taskpara ajustar a programação da recolha. - Parâmetros-chave:
item_id: ID do item da lista de observação.item: Modelo PydanticWatchlistUpdatecom detalhes atualizados.db: Sessão da base de dados SQLAlchemy.
- Retorna: Objeto
WatchlistResponseatualizado. - Notas: Gera HTTP 404 se o item não for encontrado, HTTP 400 para
target_nameduplicado ou HTTP 500 para erros.
-
delete_watchlist_item(item_id: int, db: Session):- Objetivo: Elimina um item da lista de observação e as suas digitalizações associadas.
- Funcionalidade: Remove o item da
Watchlist, as suas digitalizações daWatchlistProfileScane a tarefa APScheduler correspondente. - Parâmetros-chave:
item_id: ID do item da lista de observação.db: Sessão da base de dados SQLAlchemy.
- Retorna: resposta JSON com mensagem de sucesso.
- Observações: gera HTTP 404 se o item não for encontrado, HTTP 500 para erros. Ignora tarefas do agendador ausentes.
-
get_profile_scans(watchlist_id: int, db: Session):- Objetivo: recupera todos os resultados de varredura para um item da lista de observação.
- Funcionalidade: Consulta
WatchlistProfileScanpara varreduras que correspondem awatchlist_id, ordenadas por data e hora (descendente) e as retorna como objetosWatchlistProfileScanResponse. - Parâmetros principais:
watchlist_id: ID do item da lista de observação.db: Sessão da base de dados SQLAlchemy.
- Retorna: Lista de objetos
WatchlistProfileScanResponse. - Notas: Gera um erro HTTP 500 para erros de consulta.
-
download_scan(scan_id: int, db: Session):- Objetivo: Faz o download dos dados do perfil de uma verificação como um ficheiro JSON.
- Funcionalidade: Recupera a verificação por
scan_id, grava os seusprofile_datanum ficheiro JSON temporário e devolve-os como umFileResponse. - Parâmetros-chave:
scan_id: ID da verificação a descarregar.db: Sessão da base de dados SQLAlchemy.
- Retorna:
FileResponsecom o ficheiro JSON. - Notas: Apresenta HTTP 404 se a verificação não for encontrada, HTTP 500 para erros.
-
startup_event():- Objetivo: Inicializa o APScheduler no arranque da aplicação.
- Funcionalidade: Verifica se o programador não está em execução, cria uma sessão de base de dados, chama
schedule_all_taskspara programar todos os itens da lista de observação e inicia o programador. - Parâmetros principais: Nenhum.
- Retorna: Nenhum. Regista o estado do programador.
- Notas: garante que o agendador seja iniciado apenas uma vez para evitar tarefas duplicadas.
Se não estiver satisfeito com as frequências padrão, pode modificá-las em watchlist.py. Para manter a consistência, também será necessário atualizar os modelos de acordo. No entanto, se estiver a ajustar as frequências para fins de depuração, pode modificá-las apenas em watchlist.py sem alterar os modelos.
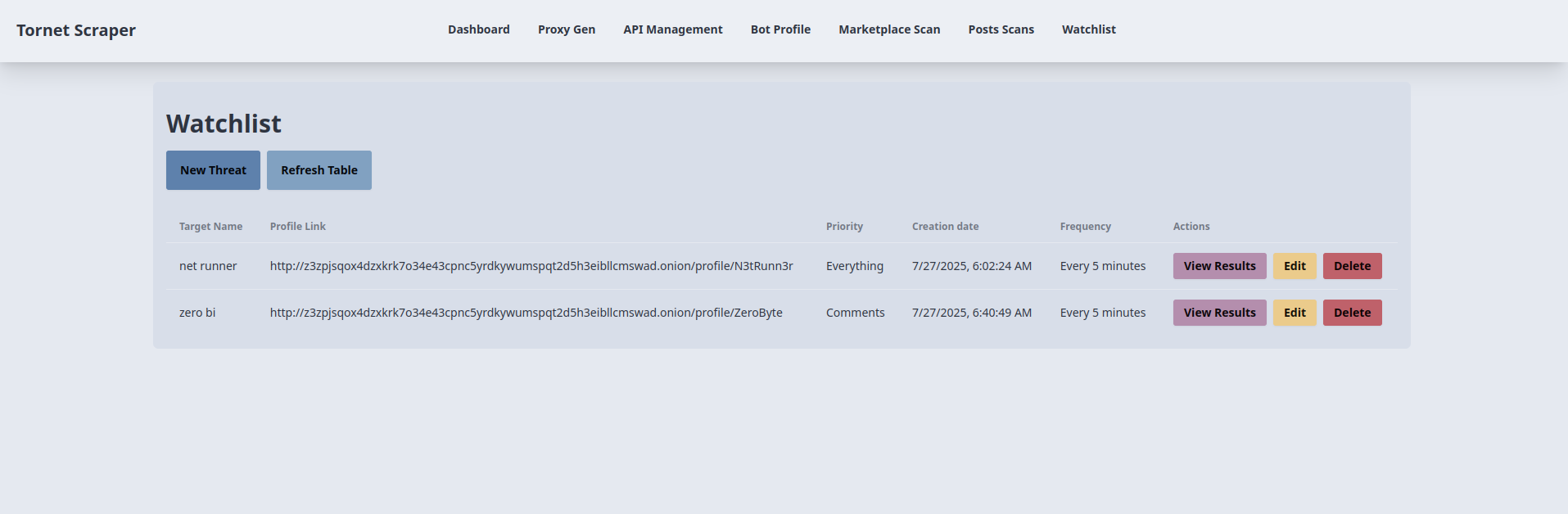
Modelo para criar listas de observação
O modelo que utilizaremos é uma tabela CRUD simples, mantendo-a simples e funcional. Pode revê-la abrindo app/templates/watchlist.html.
-
Criação de item da lista de observação:
- Objetivo: Adiciona um novo item à lista de observação para monitorizar um perfil de destino.
- Interação com o backend:
- O botão «Nova ameaça» abre um modal (
newThreatModal) com campos para o nome do alvo, link do perfil (URL), prioridade (tudo,publicações,comentários) e frequência (a cada 24 horas,a cada 12 horas, etc.). - O envio do formulário (
newThreatForm) valida o link do perfil e envia uma solicitação AJAX POST para/api/watchlist-api/items(tratada porwatchlist_api_router) com os dados do formulário. - O backend cria um registo
Watchlist, guarda-o na base de dados e retorna uma resposta de sucesso. Em caso de sucesso, o modal fecha, o formulário é reiniciado eloadWatchlist()atualiza a tabela. Os erros acionam um alerta.
- O botão «Nova ameaça» abre um modal (
-
Listagem e atualização de itens da lista de observação:
- Objetivo: Exibe e atualiza uma tabela de itens da lista de observação.
- Interação com o backend:
- A função
loadWatchlist(), chamada ao carregar a página e pelo botão “Atualizar tabela”, envia uma solicitação AJAX GET para/api/watchlist-api/items(gerenciada porwatchlist_api_router). - O backend retorna uma lista de registos
Watchlist(ID, nome do alvo, link do perfil, prioridade, frequência, carimbo de data/hora). A tabela é preenchida com esses detalhes, mostrando “Nenhum item encontrado” se estiver vazia. Erros acionam um alerta e exibem uma mensagem de falha na tabela.
- A função
-
Edição de itens da lista de observação:
- Objetivo: Atualiza um item existente da lista de observação.
- Interação do backend:
- O botão «Editar» de cada linha da tabela busca os dados do item por meio de uma solicitação AJAX GET para
/api/watchlist-api/items/{id}(gerenciada porwatchlist_api_router) e preenche oeditThreatModalcom os valores atuais. - O envio do formulário (
editThreatForm) valida o link do perfil e envia uma solicitação AJAX PUT para/api/watchlist-api/items/{id}com os dados atualizados. - O backend atualiza o registro
Watchlist. Se for bem-sucedido, o modal fecha eloadWatchlist()atualiza a tabela. Erros acionam um alerta.
- O botão «Editar» de cada linha da tabela busca os dados do item por meio de uma solicitação AJAX GET para
-
Eliminação de itens da lista de observação:
- Objetivo: elimina um item da lista de observação.
- Interação com o backend:
- O botão «Eliminar» de cada linha da tabela solicita confirmação e envia uma solicitação AJAX DELETE para
/api/watchlist-api/items/{id}(tratada porwatchlist_api_router). - O backend remove o registo
Watchlist. Se for bem-sucedido,loadWatchlist()atualiza a tabela. Os erros acionam um alerta.
- O botão «Eliminar» de cada linha da tabela solicita confirmação e envia uma solicitação AJAX DELETE para
-
Visualização dos resultados da lista de observação:
- Objetivo: Redireciona para uma página de resultados do perfil de um item da lista de observação.
- Interação com o backend:
- O botão «Ver resultados» de cada linha da tabela direciona para
/watchlist-profile/{id}(gerido pormain.py::watchlist_profile). - O backend renderiza um modelo com os resultados dos dados de monitorização do item da
Watchlist(por exemplo, publicações ou comentários). Não é feita nenhuma chamada AJAX direta, mas o redirecionamento depende da recuperação de dados do backend.
- O botão «Ver resultados» de cada linha da tabela direciona para
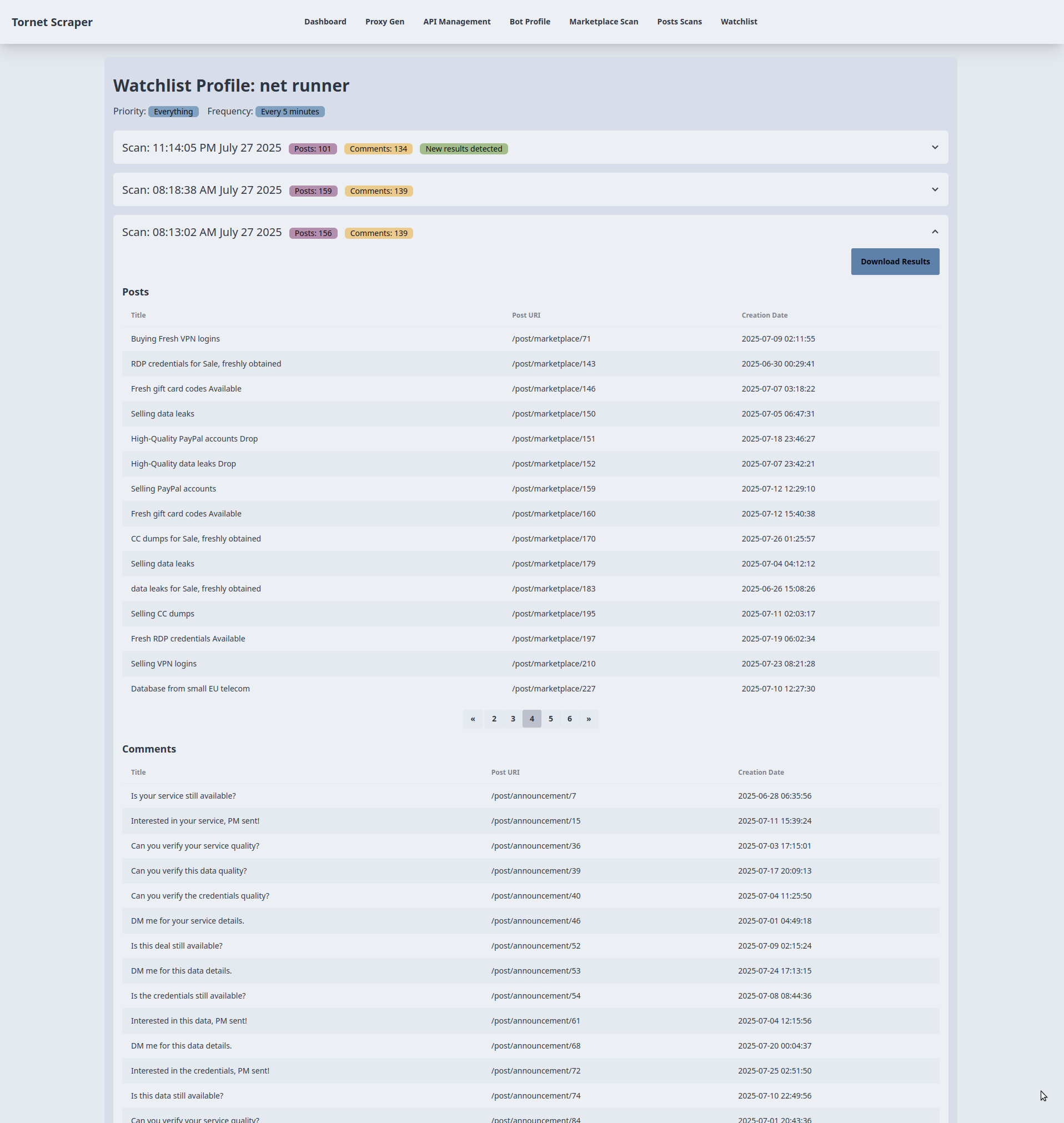
Modelo para exibir resultados da lista de observação
Precisamos de um modelo dedicado para exibir os resultados de cada alvo, pois lidamos com um grande volume de dados que precisam ser organizados por data para maior clareza.
-
Exibição dos resultados da verificação:
- Objetivo: mostra os resultados da verificação de um item da lista de observação em seções em acordeão.
- Interação com o backend:
- O modelo recebe
watchlist_item(nome do alvo, prioridade, frequência) escans(lista de dados de verificação comprofile_datacontendo publicações e comentários) demain.py::watchlist_profile. - Cada acordeão representa uma verificação, exibindo a data e hora da verificação, a contagem de publicações e a contagem de comentários (de
profile_data). Um selo «Novos resultados detectados» aparece se a contagem de publicações ou comentários da última verificação for diferente da verificação anterior. Os dados são renderizados usando Jinja2 sem chamadas de API adicionais.
- O modelo recebe
-
Tabelas de publicações e comentários:
- Objetivo: Exibe até 15 publicações e comentários por verificação em tabelas separadas.
- Interação com o backend:
- Para cada verificação, as publicações (
profile_data.posts) e os comentários (profile_data.comments) são renderizados em tabelas com colunas para título, URL e data de criação (ou texto do comentário para comentários). Se não existirem dados, é apresentada a mensagem «Nenhuma publicação/comentário encontrado». - Os dados são pré-carregados do backend através de
main.py::watchlist_profile, não sendo necessárias mais solicitações de API para a renderização da tabela.
- Para cada verificação, as publicações (
-
Paginação para grandes conjuntos de dados:
- Objetivo: Lida com a paginação para varreduras com mais de 15 publicações ou comentários.
- Interação com o backend:
- Para tabelas com mais de 15 itens, um grupo de botões de paginação é renderizado com até 5 botões de página, usando
data-items(publicações/comentários codificados em JSON) edata-total-pagesdeprofile_data.post_countoucomment_count. - A função
changePage()gere a paginação do lado do cliente, dividindo os dados JSON para exibir 15 itens por página sem chamadas adicionais ao backend. Atualiza dinamicamente os botões da página e o conteúdo da tabela com base na navegação do utilizador (cliques em anterior/seguinte ou número da página).
- Para tabelas com mais de 15 itens, um grupo de botões de paginação é renderizado com até 5 botões de página, usando
-
Transferência dos resultados da digitalização:
- Objetivo: Exporta os resultados da digitalização como um ficheiro.
- Interação com o backend:
- Cada acordeão de digitalização inclui um botão «Download Results» (Transferir resultados) com uma ligação para
/api/watchlist-api/download-scan/{scan.id}(gerido porwatchlist_api_router). - O backend gera um ficheiro transferível (por exemplo, JSON ou CSV) contendo os
profile_datada digitalização (publicações e comentários). O link aciona uma transferência direta sem AJAX, dependendo do processamento do backend.
- Cada acordeão de digitalização inclui um botão «Download Results» (Transferir resultados) com uma ligação para
Optei por acordeões para organizar os resultados da verificação por data e hora, pois acredito que esta é a abordagem mais eficaz para gerir grandes conjuntos de dados. Embora possa preferir um método diferente, o formato de acordeão proporciona uma visualização clara e eficiente.
Não é necessário modificar o modelo, pois pode exportar os dados como JSON e visualizá-los em qualquer formato fora do tornet_scraper.
Testes
Para começar os testes, configure os seguintes componentes:
- Configure uma API para resolução de CAPTCHA.
- Crie um perfil de bot com a finalidade definida como
scrape_profilee faça login para obter uma sessão. - Crie uma lista de observação usando a página
/watchlist.
Para criar uma lista de observação para monitorar uma ameaça, forneça o seguinte:
- Nome do alvo: qualquer identificador para a ameaça.
- Link do perfil: no formato
http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/profile/N3tRunn3r.
Navegue até o menu Watchlist, clique em New Threat e insira os detalhes. Ao adicionar um alvo pela primeira vez, o modal pode pausar brevemente enquanto o backend inicia uma verificação inicial. Essa verificação inicial na criação do alvo não é o comportamento padrão do agendador de tarefas em watchlist.py, mas é um recurso personalizado que implementei.
Veja como os alvos são exibidos:
A seguir, são apresentados os resultados da monitorização. Para testes, ajustei a frequência crítica de agendamento de 5 minutos para 1 minuto:
Pode expandir qualquer acordeão para ver os resultados e descarregá-los como JSON: