Nesta secção, aprenderemos como extrair publicações do mercado dos vendedores e distribuir as tarefas de extração por vários bots para serem executadas simultaneamente.
O objetivo é dividir as tarefas entre os bots porque a maioria dos fóruns impõe limites de taxa ao número de pedidos que pode enviar. Em tornet_forum, não há limitação de taxa para navegar na paginação e pode mover-se entre páginas sem estar conectado.
No entanto, para nos prepararmos para vários mecanismos de proteção, usaremos bots com sessões ativas para extrair. Embora não seja necessário para tornet_forum, sessões iniciadas podem ser necessárias para outros sites de destino que encontrar. Tendo extraído dados desses sites, compreendo os desafios que poderá enfrentar, e esta abordagem prepara-o para qualquer cenário.
Os tópicos desta secção incluem o seguinte:
- Modelos de base de dados
- Módulos de scraping do marketplace
- Rotas de backend do marketplace
- Modelo de frontend do marketplace
- Testes
Modelos de base de dados
Os seus modelos estão localizados em app/database/models.py. Precisa de 4 modelos para organizar corretamente os dados:
class MarketplacePaginationScan(Base):
__tablename__ = "marketplace_pagination_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False)
pagination_url = Column(String, nullable=False)
max_page = Column(Integer, nullable=False)
batches = Column(Text, nullable=True)
timestamp = Column(DateTime, default=datetime.utcnow)
class ScanStatus(enum.Enum):
RUNNING = "running"
COMPLETED = "completed"
STOPPED = "stopped"
class MarketplacePostScan(Base):
__tablename__ = "marketplace_post_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False, unique=True)
pagination_scan_name = Column(String, ForeignKey("marketplace_pagination_scans.scan_name"), nullable=False)
start_date = Column(DateTime(timezone=True), default=datetime.utcnow)
completion_date = Column(DateTime(timezone=True), nullable=True)
status = Column(Enum(ScanStatus), default=ScanStatus.STOPPED, nullable=False)
timestamp = Column(DateTime, default=datetime.utcnow)
class MarketplacePost(Base):
__tablename__ = "marketplace_posts"
id = Column(Integer, primary_key=True, index=True)
scan_id = Column(Integer, ForeignKey("marketplace_post_scans.id"), nullable=False)
timestamp = Column(String, nullable=False)
title = Column(String, nullable=False)
author = Column(String, nullable=False)
link = Column(String, nullable=False)
__table_args__ = (UniqueConstraint('scan_id', 'timestamp', name='uix_scan_timestamp'),)
Para esta funcionalidade, precisamos de vários modelos para fazer tudo o seguinte:
MarketplacePaginationScan:- Objetivo: Representa uma configuração de varredura de paginação para extrair dados de um marketplace. Armazena detalhes sobre uma varredura que enumera as páginas de um marketplace, como a URL base e o número máximo de páginas a serem varridas.
- Campos-chave:
id: Identificador único para a varredura.scan_name: Nome único para a varredura de paginação.pagination_url: A URL base usada para paginação.max_page: O número máximo de páginas a serem varridas.batches: Armazena dados em lote serializados (por exemplo, JSON) para processamento de páginas.
timestamp: Regista quando a verificação foi criada.
-
ScanStatus (Enum):- Finalidade: Define os estados possíveis de uma verificação pós-verificação, usado para rastrear o estado de um
MarketplacePostScan. - Valores:
RUNNING: A verificação está em curso.COMPLETED: A verificação foi concluída com sucesso.STOPPED: A verificação não está em execução (padrão ou interrompida manualmente).
- Finalidade: Define os estados possíveis de uma verificação pós-verificação, usado para rastrear o estado de um
-
MarketplacePostScan:- Objetivo: Representa uma verificação que recolhe publicações de um marketplace, vinculada a uma verificação de paginação específica. Rastreia os metadados e o estado da verificação.
- Campos-chave:
id: Identificador único para a verificação de publicação.scan_name: Nome único para a verificação de publicação.pagination_scan_name: Faz referência aoMarketplacePaginationScanassociado pelo seuscan_name.start_date: Quando a verificação começou.completion_date: Quando a verificação foi concluída (se aplicável).status: Estado atual da verificação (da enumeraçãoScanStatus).timestamp: Regista quando a verificação foi criada.
-
MarketplacePost:- Finalidade: Armazena publicações individuais recolhidas durante uma
MarketplacePostScan. Cada publicação está ligada a uma verificação específica e inclui detalhes sobre a publicação. - Campos-chave:
id: Identificador único da publicação.scan_id: Faz referência aoMarketplacePostScanao qual esta publicação pertence.timestamp: Carimbo de data/hora da publicação (como uma string).title: Título da publicação no marketplace.author: Autor da publicação.link: URL da publicação.__table_args__: garante a exclusividade das publicações com base emscan_idetimestamppara evitar duplicatas.
- Finalidade: Armazena publicações individuais recolhidas durante uma
Módulos do scraper do marketplace
Para ver um exemplo de como o scraper do marketplace funciona, abra app/scrapers/marketplace_scraper.py.
import json
import requests
from bs4 import BeautifulSoup
import logging
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def create_pagination_batches(url_template, max_page):
"""
Given a web URL with max pagination number, this function returns batches of 10 pagination ranges.
"""
if max_page < 1:
return json.dumps({})
all_urls = [url_template.format(page=page) for page in range(max_page, 0, -1)]
batch_size = 10
batches = {f"{i//batch_size + 1}": all_urls[i:i + batch_size] for i in range(0, len(all_urls), batch_size)}
return json.dumps(batches)
def scrape_posts(session, proxy, useragent, pagination_range, timeout=30):
"""
Given a list of web pages, it scraps all post details from every pagination page.
"""
posts = {}
headers = {'User-Agent': useragent}
proxies = {'http': proxy, 'https': proxy} if proxy else None
for url in pagination_range:
logger.info(f"Scraping URL: {url}")
try:
response = session.get(url, headers=headers, proxies=proxies, timeout=timeout)
logger.info(f"Response status code: {response.status_code}")
response.raise_for_status()
# Log response size and snippet
logger.debug(f"Response size: {len(response.text)} bytes")
logger.debug(f"Response snippet: {response.text[:200]}...")
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.select_one('table.table-dark tbody')
if not table:
logger.error(f"No table found on {url}")
continue
table_rows = table.select('tr')
logger.info(f"Found {len(table_rows)} table rows on {url}")
for row in table_rows[:10]:
try:
title = row.select_one('td:nth-child(1)').text.strip()
author = row.select_one('td:nth-child(2) a').text.strip()
timestamp = row.select_one('td:nth-child(3)').text.strip()
link = row.select_one('td:nth-child(5) a')['href']
logger.info(f"Extracted post: timestamp={timestamp}, title={title}, author={author}, link={link}")
posts[timestamp] = {
'title': title,
'author': author,
'link': link
}
except AttributeError as e:
logger.error(f"Error parsing row on {url}: {e}")
continue
except requests.RequestException as e:
logger.error(f"Error scraping {url}: {e}")
continue
logger.info(f"Total posts scraped: {len(posts)}")
return json.dumps(posts)
if __name__ == "__main__":
# Create a proper requests.Session and set the cookie
session = requests.Session()
session.cookies.set('session', '.eJwlzsENwzAIAMBd_O4DbINNlokAg9Jv0ryq7t5KvQnuXfY84zrK9jrveJT9ucpWbA0xIs5aZ8VM5EnhwqNNbblWVlmzMUEH9MkDmwZQTwkFDlqhkgounTm9Q7U0nYQsw6MlmtKYqBgUpAMkuJpnuEMsYxtQfpH7ivO_wfL5AtYwMDs.aH1ifQ.uRrB1FnMt3U_apyiWitI9LDnrGE')
proxy = "socks5h://127.0.0.1:49075"
useragent = "Mozilla/5.0 (Windows NT 11.0; Win64; x64; rv:140.0) Gecko/20100101 Firefox/140.0"
pagination_range = [
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=1",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=2",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=3"
]
timeout = 30
result = scrape_posts(session, proxy, useragent, pagination_range, timeout)
print(result)
Precisamos de duas funções individuais para realizar essas tarefas:
- create_pagination_batches(url_template, max_page)
- Gera lotes de URLs para paginação, criando grupos de 10 URLs de páginas a partir de um modelo de URL fornecido e um número máximo de páginas, retornando-os como uma string JSON.
- scrape_posts(session, proxy, useragent, pagination_range, timeout)
- Extraia detalhes da publicação (título, autor, carimbo de data/hora, link) de uma lista de URLs de páginas da Web usando uma sessão de solicitações, proxy e agente do utilizador, analisando HTML com
BeautifulSoupe retorne os dados recolhidos como uma string JSON.
- Extraia detalhes da publicação (título, autor, carimbo de data/hora, link) de uma lista de URLs de páginas da Web usando uma sessão de solicitações, proxy e agente do utilizador, analisando HTML com
Limitamos os lotes de paginação a 10 páginas porque esse é o limite que definimos. Pode ajustar esse limite, mas se os seus bots acederem a 50 páginas de paginação em apenas alguns segundos, isso poderá acionar o bloqueio da conta.
Mais tarde, usaremos a função scrape_posts para processar intervalos de lotes de paginação, permitindo a extração de publicações de todos os lotes.
Criando o backend do marketplace
O backend pode parecer mais assustador do que as tarefas anteriores. Você pode encontrar o código do backend em app/routes/marketplace.py.
Essa complexidade surge da concorrência, que nos permite distribuir tarefas de scraping de dados por todos os bots disponíveis, aumentando a eficiência, mas adicionando complexidade. Observe que todas as varreduras são executadas em segundo plano, portanto, continuam mesmo se você navegar entre as páginas.
Embora as funcionalidades possam parecer complexas, isso é uma parte natural do processo de aprendizagem. O nosso objetivo é construir um scraper web avançado para a recolha de dados a longo prazo, uma tarefa que é inerentemente sofisticada.
get_pagination_scans
- Ponto final:
GET /api/marketplace-scan/list - Objetivo: Recupera todas as varreduras de paginação do banco de dados.
- Funcionalidade:
- Consulta a tabela
MarketplacePaginationScanpara buscar todos os registos. - Regista o número de varreduras buscadas.
- Formata cada varredura em um dicionário compatível com JSON contendo
id,scan_name,pagination_url,max_page,batchesetimestamp. - Retorna um
JSONResponsecom a lista de varreduras e um código de status 200. - Lida com exceções registrando erros e gerando uma
HTTPExceptioncom um código de status 500 se ocorrer um erro.
- Consulta a tabela
enumerate_pages
- Ponto de extremidade:
POST /api/marketplace-scan/enumerate - Objetivo: Cria uma nova digitalização de paginação para enumerar páginas para extração.
- Funcionalidade:
- Valida se o
scan_namefornecido já existe no banco de dados. - Chama
create_pagination_batchespara gerar lotes de URLs com base nopagination_urlemax_pagefornecidos. - Cria um novo registo
MarketplacePaginationScancom os detalhes da verificação e armazena os lotes como JSON. - Envia o registo para a base de dados e regista a criação.
- Armazena uma mensagem de sucesso na sessão e retorna um
JSONResponsecom um código de estado 201. - Lida com nomes de varredura duplicados (400), erros de banco de dados (500, com reversão) e outras exceções registrando e levantando
HTTPExceptions apropriados.
- Valida se o
delete_pagination_scan
- Ponto final:
DELETE /api/marketplace-scan/{scan_id} - Objetivo: exclui uma digitalização de paginação pelo seu ID.
- Funcionalidade:
- Consulta a tabela
MarketplacePaginationScanpara a digitalização com oscan_idespecificado. - Se a varredura não for encontrada, registra um aviso e gera uma
HTTPException404. - Exclui a varredura do banco de dados e confirma a transação.
- Registra a exclusão e armazena uma mensagem de sucesso na sessão.
- Retorna uma
JSONResponsecom um código de status 200. - Lida com erros registrando-os, revertendo a transação e gerando uma
HTTPException500.
- Consulta a tabela
get_post_scans
- Ponto final:
GET /api/marketplace-scan/posts/list - Objetivo: Recupera todas as digitalizações de publicações da base de dados.
- Funcionalidade:
- Consulta a tabela
MarketplacePostScanpara obter todos os registos. - Regista o número de digitalizações obtidas.
- Formata cada digitalização num dicionário compatível com JSON com
id,scan_name,pagination_scan_name,start_date,completion_date,statusetimestamp. - Retorna uma
JSONResponsecom a lista de digitalizações e um código de estado 200. - Lida com exceções registrando e gerando uma
HTTPException500.
- Consulta a tabela
get_post_scan_status
- Ponto de extremidade:
GET /api/marketplace-scan/posts/{scan_id}/status - Objetivo: Recupera o estado de uma verificação de publicação específica pelo seu ID.
- Funcionalidade:
- Consulta a tabela
MarketplacePostScanpara a verificação com oscan_idespecificado. - Se a verificação não for encontrada, regista um aviso e gera uma
HTTPException404. - Regista o estado e retorna uma
JSONResponsecom oid,scan_nameestatus(como um valor de string) da verificação com um código de estado 200. - Trata as exceções registando-as e gerando uma
HTTPException500.
- Consulta a tabela
enumerate_posts
- Ponto de extremidade:
POST /api/marketplace-scan/posts/enumerate - Objetivo: Cria uma nova verificação de publicação associada a uma verificação de paginação.
- Funcionalidade:
- Valida se o
scan_namefornecido já existe. - Verifica se o
pagination_scan_namereferenciado existe na tabelaMarketplacePaginationScan. - Garante que existem bots ativos com a finalidade
SCRAPE_MARKETPLACEe sessões válidas. - Cria um novo registo
MarketplacePostScancom oscan_name,pagination_scan_namee o estado inicialSTOPPEDfornecidos. - Envia o registo para a base de dados e regista a criação.
- Armazena uma mensagem de sucesso na sessão e retorna uma
JSONResponsecom um código de estado 201. - Lida com erros para nomes de varredura duplicados (400), varreduras de paginação ausentes (404), nenhum bot ativo (400) ou outros problemas (500, com reversão).
- Valida se o
start_post_scan
- Ponto final:
POST /api/marketplace-scan/posts/{scan_id}/start - Objetivo: Inicia uma pós-varredura processando lotes de URLs usando bots disponíveis.
- Funcionalidade:
- Recupera o
MarketplacePostScanporscan_ide verifica se ele existe. - Garante que a verificação ainda não está em execução (gera 400 se estiver).
- Verifica a disponibilidade de bots com a finalidade
SCRAPE_MARKETPLACE. - Recupera o
MarketplacePaginationScanassociado e seus lotes. - Atualiza o status da verificação para
RUNNING, define astart_datee limpa acompletion_date. - Executa uma tarefa
scrape_batchesassíncrona para processar lotes simultaneamente: - Atribui lotes aos bots disponíveis usando um
ThreadPoolExecutor. - Cada bot raspa um lote de URLs usando a função
scrape_posts, com cookies de sessão e proxy Tor. - Lida com erros de análise JSON sanitizando os dados (normalizando Unicode, removendo caracteres de controlo).
- Guarda publicações únicas na tabela
MarketplacePost, evitando duplicados. - Regista o progresso e os erros de cada lote.
- Marca a verificação como
COMPLETEDem caso de sucesso ouSTOPPEDem caso de falha. - Armazena uma mensagem de sucesso na sessão e devolve uma
JSONResponsecom um código de estado 200. - Lida com erros para varreduras ausentes (404), varreduras em execução (400), sem bots (400), lotes ausentes (400) ou outros problemas (500, com reversão).
- Recupera o
delete_post_scan
- Ponto final:
DELETE /api/marketplace-scan/posts/{scan_id} - Objetivo: Elimina uma verificação de publicação pelo seu ID.
- Funcionalidade:
- Consulta a tabela
MarketplacePostScanpara a verificação com oscan_idespecificado. - Se a verificação não for encontrada, regista um aviso e gera uma
HTTPException404. - Elimina a verificação da base de dados e confirma a transação.
- Regista a eliminação e armazena uma mensagem de sucesso na sessão.
- Retorna uma
JSONResponsecom um código de estado 200. - Trata os erros registando-os, revertendo a transação e gerando uma
HTTPException500.
- Consulta a tabela
get_scan_posts
- Ponto de extremidade:
GET /api/marketplace-scan/posts/{scan_id}/posts - Objetivo: Recupera todas as publicações associadas a uma verificação de publicação específica.
- Funcionalidade:
- Consulta a tabela
MarketplacePostScanpara verificar se a verificação existe. - Se a verificação não for encontrada, regista um aviso e gera uma
HTTPException404. - Consulta a tabela
MarketplacePostpara todas as publicações ligadas aoscan_id. - Regista o número de publicações recuperadas.
- Formata cada publicação num dicionário compatível com JSON com
id,timestamp,title,authorelink. - Retorna um
JSONResponsecom a lista de publicações e um código de estado 200. - Trata exceções registando e gerando uma
HTTPException500.
- Consulta a tabela
Esta funcionalidade requer o início manual da recolha a cada poucas horas para verificar se há novas atividades no fórum. A automatização deste processo é evitada para conservar recursos, pois a recolha contínua frequentemente recolheria dados duplicados, levando a um consumo ineficiente de recursos. Portanto, executar varreduras no marketplace sem parar não é a abordagem ideal.
Pela minha vasta experiência, implementar varreduras contínuas a cada poucas horas geralmente não é aconselhável devido à significativa demanda de recursos.
No Módulo 5, implementaremos a recolha contínua de dados, mas, como você descobrirá, esse processo geralmente gera dados duplicados.
Modelo de front-end do marketplace
Para o marketplace, precisamos de um modelo com duas guias, que nos permitam alternar entre vários contentores dentro de uma única página. Em vez de criar duas rotas separadas, usaremos uma rota com guias para simplificar o design.
Embora as guias possam, por vezes, complicar uma aplicação web, neste caso, elas simplificam-na, evitando a necessidade de dois modelos separados, o que aumentaria o tamanho da aplicação. À medida que avançamos, exploraremos vários modelos, mas para esta funcionalidade específica, as guias são suficientes.
O modelo está localizado em app/templates/marketplace.html.
-
Navegação por separadores para paginação e digitalizações de publicações:
- Objetivo: Organiza a interface em separadores «Paginação do mercado» e «Publicações do mercado».
- Interação com o backend: A função
openTab()alterna a visibilidade do conteúdo da guia (paginationouposts) sem chamadas diretas ao backend. Os dados iniciais para ambas as guias (pagination_scansepost_scans) são fornecidos pormain.py::marketplacee renderizados usando Jinja2.
-
Enumeração de digitalização de paginação:
- Objetivo: Inicia uma nova digitalização de paginação para enumerar as páginas do marketplace.
- Interação com o backend:
- O botão “Enumerar páginas” abre um modal (
enumerate-modal) com campos para o nome da digitalização, URL de paginação e número máximo de páginas. - O envio do formulário envia uma solicitação AJAX POST para
/api/marketplace-scan/enumerate(tratada pormarketplace_api_router) com os dados do formulário. - O backend cria um registo
MarketplacePaginationScan, processa a paginação e armazena os resultados. Em caso de sucesso, a página é recarregada para exibir a lista de varreduras atualizada. Erros acionam um alerta com a mensagem de erro.
- O botão “Enumerar páginas” abre um modal (
-
Enumeração pós-digitalização:
- Objetivo: Cria uma nova digitalização pós-digitalização com base numa digitalização de paginação existente.
- Interação com o backend:
- O botão «Enumerar publicações» abre um modal (
enumerate-posts-modal) com campos para o nome da digitalização e uma lista suspensa das digitalizações de paginação existentes (preenchida a partir depagination_scans). - O envio do formulário envia uma solicitação AJAX POST para
/api/marketplace-scan/posts/enumerate(tratada pormarketplace_api_router) com o nome da verificação e a verificação de paginação selecionada. - O backend cria um registo
MarketplacePostScanligado à verificação de paginação escolhida. Se for bem-sucedido, a página é recarregada para atualizar a tabela de verificações de publicações. Os erros acionam um alerta.
- O botão «Enumerar publicações» abre um modal (
-
Gestão de verificações de publicações:
- Objetivo: Inicia, visualiza ou elimina verificações de publicações.
- Interação com o backend:
- Iniciar: Cada linha de verificação de publicação (não em execução) tem um botão «Iniciar» que envia uma solicitação AJAX POST para
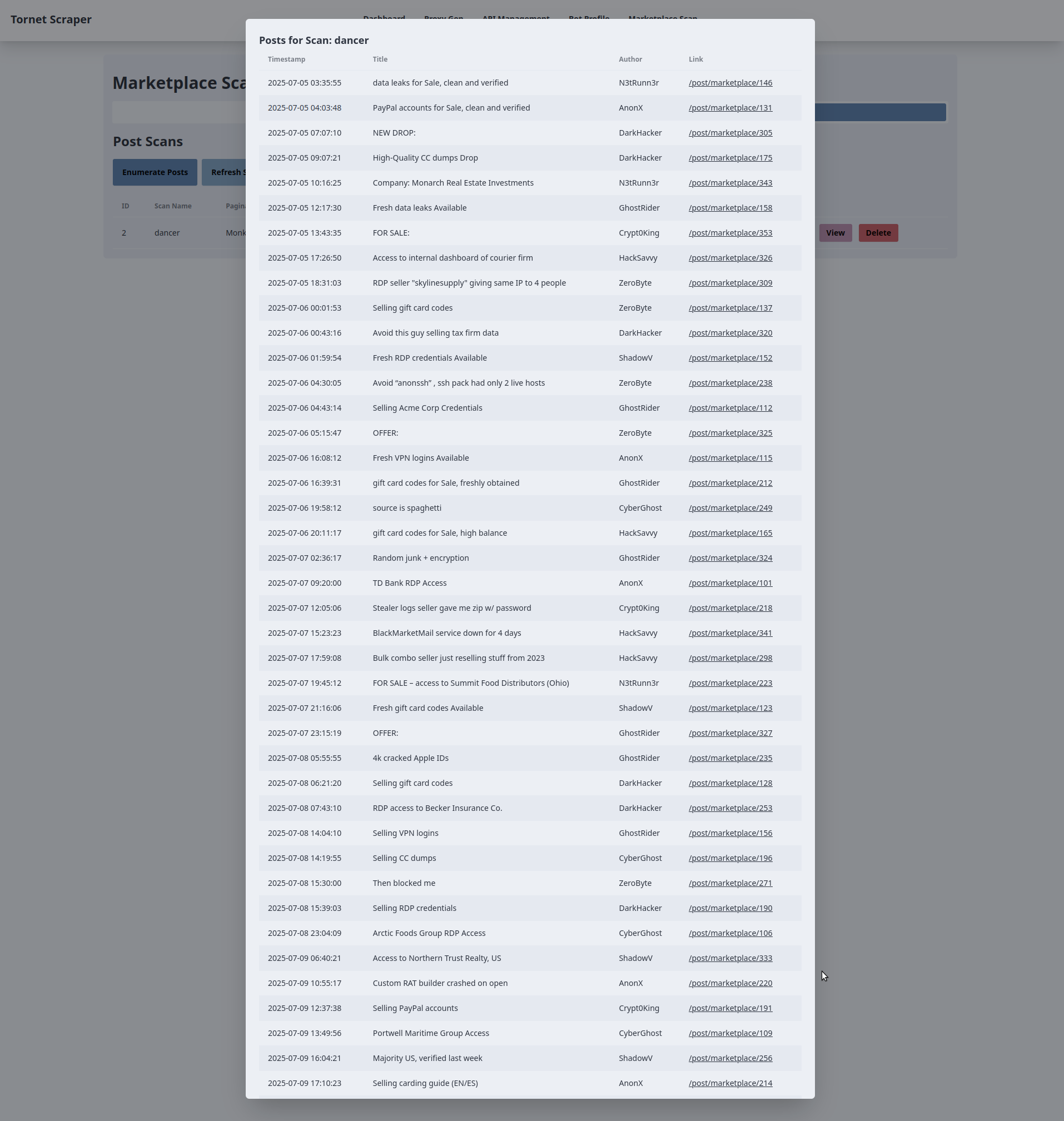
/api/marketplace-scan/posts/{scanId}/start(gerido pormarketplace_api_router) para iniciar a verificação. Em caso de sucesso,refreshScans()atualiza a tabela. - Visualizar: Um botão «Visualizar» abre um modal (
view-posts-modal-{scanId}) que busca os dados da publicação por meio de uma solicitação AJAX GET para/api/marketplace-scan/posts/{scanId}/posts, preenchendo uma tabela com os detalhes da publicação (carimbo de data/hora, título, autor, link). Erros acionam um alerta. - Eliminar: Um botão «Eliminar» solicita confirmação e envia uma solicitação AJAX DELETE para
/api/marketplace-scan/posts/{scanId}para remover a verificação da tabelaMarketplacePostScan. Se for bem-sucedido, a página é recarregada. Os erros acionam um alerta.
- Iniciar: Cada linha de verificação de publicação (não em execução) tem um botão «Iniciar» que envia uma solicitação AJAX POST para
-
Visualização e eliminação da digitalização de paginação:
- Objetivo: Exibe detalhes das digitalizações de paginação e permite a eliminação.
- Interação com o backend:
- Visualizar: Cada linha de digitalização de paginação tem um botão «Visualizar» que abre um modal (
view-modal-{scanId}) com campos somente de leitura para nome da digitalização, URL, página máxima e lotes (formato JSON). Os dados são pré-carregados depagination_scansvia Jinja2, sem necessidade de chamada adicional ao backend. - Eliminar: Um botão «Eliminar» (
deleteScan()) solicita confirmação e envia um pedido AJAX DELETE para/api/marketplace-scan/{scanId}para remover a digitalização da tabelaMarketplacePaginationScan. Se for bem-sucedido, a página é recarregada. Os erros acionam um alerta.
- Objetivo: Exibe detalhes das digitalizações de paginação e permite a eliminação.
-
Atualização da tabela pós-digitalização:
- Objetivo: atualiza a tabela pós-digitalizações para refletir os status atuais.
- Interação com o backend:
- O botão “Atualizar digitalizações” aciona
refreshScans(), enviando uma solicitação AJAX GET para/api/marketplace-scan/posts/list(gerenciada pormarketplace_api_router). - O backend retorna uma lista de registos
MarketplacePostScan(ID, nome da verificação, nome da verificação de paginação, datas de início/conclusão, estado). A tabela é atualizada com ícones de estado (por exemplo, Concluído, Em execução, Parado). Os erros acionam um alerta.
- O botão “Atualizar digitalizações” aciona
Testes
Para iniciar os testes, você precisará configurar os seguintes componentes:
- Adicione e ative uma API CAPTCHA a partir do ponto final
/manage-api. - Crie pelo menos dois perfis de bot e faça login para recuperar as suas sessões a partir do ponto final
/bot-profile. - Obtenha o URL de paginação do marketplace a partir de
tornet_forum, por exemplo:http://site.onion/category/marketplace/Sellers?page=1. - Navegue até
/marketplace-scan, selecione o separadorMarketplace Pagination, clique emEnumerate Pagese preencha os campos da seguinte forma:- Scan Name:
Monkey - Pagination URL:
http://site.onion/category/marketplace/Sellers?page={page} - Número máximo de paginação: 14 (ajuste com base no número total de páginas de paginação disponíveis).
- Scan Name:
Quando a verificação for concluída, clique para ver os resultados e um modal será exibido. Abaixo está um exemplo de como os lotes de paginação podem aparecer no formato JSON:
"{\"1\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=14\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=13\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=12\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=11\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=9\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=8\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=7\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=6\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=5\"], \"2\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=4\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=3\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=2\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=1\"]}"
Para enumerar publicações no marketplace, siga estas etapas:
- Navegue até
/marketplace-scane selecione a guiaPublicações do marketplace. - Clique em
Enumerar publicações, insira um nome para a verificação, selecione a verificação de paginação chamadaMonkeye clique emIniciar verificação. Isso prepara a verificação, mas não a inicia. - Volte para
/marketplace-scan, aceda ao separadorMarketplace Posts, localize a sua verificação e clique no botãoStartpara iniciar a verificação.
Abaixo está um exemplo do resultado da minha configuração:
2025-07-21 19:49:41,140 - INFO - Found 3 active bots for scan ID 6: ['DarkHacker', 'CyberGhost', 'ShadowV']
2025-07-21 19:49:41,141 - INFO - Starting post scan tyron (ID: 6) with 2 batches: ['1', '2']
2025-07-21 19:49:41,148 - INFO - Post scan tyron (ID: 6) status updated to RUNNING
2025-07-21 19:49:41,149 - INFO - Assigning batch 1 to bot DarkHacker (ID: 1)
2025-07-21 19:49:41,150 - INFO - Bot DarkHacker (ID: 1) starting batch 1 (10 URLs)
2025-07-21 19:49:41,150 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:41,151 - INFO - Assigning batch 2 to bot CyberGhost (ID: 2)
2025-07-21 19:49:41,151 - INFO - Bot CyberGhost (ID: 2) starting batch 2 (10 URLs)
2025-07-21 19:49:41,151 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:46,804 - INFO - Extracted post: timestamp=2025-07-19 07:04:10, title=OFFER:, author=DarkHacker, link=/post/marketplace/1901
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 06:33:54, title=Avoid “anonssh” , ssh pack had only 2 live hosts, author=N3tRunn3r, link=/post/marketplace/588
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 05:56:53, title=Access to Northern Trust Realty, US, author=DarkHacker, link=/post/marketplace/1532
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 05:20:53, title=FOR SALE:, author=GhostRider, link=/post/marketplace/2309
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 04:24:04, title=Custom RAT builder crashed on open, author=ShadowV, link=/post/marketplace/968
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:35:29, title=Private obfuscator for Python tools, author=GhostRider, link=/post/marketplace/1845
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:23:21, title="RootedShells" panel has backconnect, author=ZeroByte, link=/post/marketplace/1829
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:09:27, title=RDP seller "skylinesupply" giving same IP to 4 people, author=N3tRunn3r, link=/post/marketplace/1710
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:39:40, title=FOR SALE: DA access into Lakewood Public Services, author=ShadowV, link=/post/marketplace/972
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:37:10, title=4k cracked Apple IDs, author=DarkHacker, link=/post/marketplace/1154
2025-07-21 19:49:46,807 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=19
2025-07-21 19:49:46,995 - INFO - Response status code: 200
--- snip ---
--- snip ---
--- snip ---
2025-07-21 19:49:56,643 - INFO - Total posts scraped: 100
2025-07-21 19:49:56,643 - INFO - Bot CyberGhost completed batch 2, found 100 posts
2025-07-21 19:49:56,696 - INFO - Bot DarkHacker saved batch 1 posts to database for scan ID 6
2025-07-21 19:49:56,704 - INFO - Bot CyberGhost saved batch 2 posts to database for scan ID 6
2025-07-21 19:49:56,710 - INFO - Post scan tyron (ID: 6) completed successfully
Quando a digitalização começar, observe que é possível alternar entre páginas, e a digitalização continuará a ser executada em segundo plano:
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on
As digitalizações não serão retomadas após reiniciar o sistema ou se sair da aplicação.
Aqui está como o resultado de uma digitalização pode aparecer no seu ecrã: