Nesta secção, explicarei como podemos realizar uma postagem em grande escala contra as postagens recolhidas. O trabalho básico já foi feito para nós, os detalhes das postagens foram recolhidos, mas o seu conteúdo não está na fase final, recolhemos o conteúdo e realizamos a tradução, se necessário.
Esta é a fase mais interessante, porque estamos a chegar ao fim do curso. Identificar as vendas da IAB foi o nosso objetivo inicial, é para isso que estão aqui, mas esta secção pode ser a mais complicada de todas, pelo menos à primeira vista.
É complexo porque estamos a construir uma solução para a digitalização de dados em grande escala, o que obviamente será complicado, com muitas partes móveis, mas é a realidade da monitorização de ameaças em grande escala.
Os tópicos desta secção incluem o seguinte:
- Componentes do scraper de dados
- Modelos de base de dados
- Modelos para gerir e exibir digitalizações
- Modelo para exibir o resultado de cada digitalização
- Rotas de back-end
- Testes
Componentes do scraper de dados
O nosso scraper de dados é composto por vários componentes, incluindo módulos projetados para tarefas como extrair detalhes de publicações, traduzir conteúdo quando necessário e classificar dados.
Os principais componentes estão localizados em app/scrapers/post_scraper.py.
-
scrape_post_details:- Objetivo: Raspa detalhes (título, carimbo de data/hora, autor, conteúdo) de uma URL de publicação especificada usando técnicas de raspa de web.
- Parâmetros principais:
post_link: URL da publicação a ser raspada.session_cookie: Cookie de autenticação para aceder à publicação.tor_proxy: Endereço proxy opcional para roteamento Tor.user_agent: String do agente do utilizador para cabeçalhos de solicitação.timeout: Duração do tempo limite da solicitação (padrão: 30 segundos).
- Retorna: String JSON contendo detalhes da publicação extraídos ou informações de erro se a solicitação falhar.
-
translate_string:- Objetivo: Deteta o idioma de uma string de entrada e traduz para inglês (ou idioma de destino especificado) usando a API DeepL, se ainda não estiver em inglês.
- Parâmetros-chave:
input_string: Texto a ser analisado e potencialmente traduzido.auth_key: Chave de autenticação da API DeepL.target_lang: Idioma de destino para tradução (padrão: EN-US).
- Retorna: String JSON com o texto original, o idioma detectado e o texto traduzido (se aplicável) ou detalhes do erro.
-
iab_classify:- Objetivo: Classifica uma publicação usando o modelo Claude da Anthropic para determinar se ela discute a venda de acesso inicial, itens não relacionados ou avisos/reclamações.
- Parâmetros principais:
api_key: Chave API da Anthropic para autenticação.model_name: Nome do modelo Claude a ser usado (por exemplo, ‘claude-3-5-sonnet-20241022’).prompt: Prompt de texto contendo a publicação a ser classificada.max_tokens: Número máximo de tokens de saída (padrão: 100).
- Retorna: String JSON com o resultado da classificação, pontuações ou informações de erro se a classificação falhar.
Função scrape_post_details
O fórum Tornet requer uma sessão iniciada para ler as publicações, o que é um comportamento típico da maioria dos fóruns. Para resolver isso, desenvolvi uma função que recebe um link da publicação e recupera os seus dados.
Esta abordagem é lógica porque a tabela marketplace_posts armazena todos os detalhes e links das publicações. Ao carregar esses dados, podemos passar cada link de publicação para uma função como scrape_post_details para extrair as informações necessárias.
Função translate_string
Na função translate_string, utilizamos o DeepL para traduzir os dados. No entanto, em app/routes/posts.py, primeiro empregamos a biblioteca langdetect para identificar o idioma de uma publicação. Se a deteção do idioma falhar ou o idioma detetado não for inglês, passamos a publicação para a função translate_string.
Uma vantagem importante é que, se fornecer uma string contendo novas linhas:
Venta de acceso a Horizon Logistics\nIngresos: 1200 millones de dólares\nAcceso: RDP con DA\nPrecio: 0,8 BTC\nDM para más detalles
A função mantém-nos na saída traduzida:
Sale of access to Horizon Logistics\nRevenue: $1.2 billion\nAccess: RDP with DA\nPrice: 0.8 BTC\nDM for more details
Função iab_classify
Em iab_classify, a nossa temperatura está definida como padrão em 0,1, mas pode alterá-la se desejar.
Em interações de IA ou LLM, a temperatura é um hiperparâmetro que controla a aleatoriedade ou criatividade da saída do modelo:
- Objetivo: Ajusta a distribuição de probabilidade sobre as possíveis saídas do modelo (por exemplo, palavras ou tokens) durante a geração.
- Como funciona:
- Baixa temperatura (por exemplo, 0,1): Torna o modelo mais determinístico, favorecendo saídas de alta probabilidade. Resulta em respostas mais focadas, previsíveis e conservadoras.
- Temperatura alta (por exemplo, 1,0 ou superior): aumenta a aleatoriedade, dando mais chances às saídas de menor probabilidade. Leva a respostas mais criativas, diversificadas ou inesperadas.
- Exemplo em código: na função
iab_classifyfornecida,temperature=0,1é usado para tornar a saída de classificação do modelo Claude mais consistente e menos aleatória. - Intervalo: Normalmente entre 0 e 1, embora alguns modelos permitam valores mais altos para aleatoriedade extrema.
Modelos de base de dados
Para extrair publicações, tamanho do lote de publicações e armazenamento de dados, precisamos de duas tabelas. Aqui está como são os seus modelos:
class PostDetailScan(Base):
__tablename__ = "post_detail_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False, unique=True)
source_scan_name = Column(String, ForeignKey("marketplace_post_scans.scan_name"), nullable=False)
start_date = Column(DateTime(timezone=True), default=datetime.utcnow)
completion_date = Column(DateTime(timezone=True), nullable=True)
status = Column(Enum(ScanStatus), default=ScanStatus.STOPPED, nullable=False)
batch_size = Column(Integer, nullable=False)
site_url = Column(String, nullable=False)
timestamp = Column(DateTime(timezone=True), default=datetime.utcnow)
class MarketplacePostDetails(Base):
__tablename__ = "marketplace_post_details"
id = Column(Integer, primary_key=True, index=True)
scan_id = Column(Integer, ForeignKey("post_detail_scans.id"), nullable=False)
batch_name = Column(String, nullable=False)
title = Column(String, nullable=False)
content = Column(Text, nullable=False)
timestamp = Column(String, nullable=False)
author = Column(String, nullable=False)
link = Column(String, nullable=False)
original_language = Column(String, nullable=True)
original_text = Column(Text, nullable=True)
translated_language = Column(String, nullable=True)
translated_text = Column(Text, nullable=True)
is_translated = Column(Boolean, default=False)
sentiment = Column(String, nullable=True)
positive_score = Column(Float, nullable=True)
negative_score = Column(Float, nullable=True)
neutral_score = Column(Float, nullable=True)
timestamp_added = Column(DateTime(timezone=True), default=datetime.utcnow)
__table_args__ = (UniqueConstraint('scan_id', 'timestamp', 'batch_name', name='uix_scan_timestamp_batch'),)
post_detail_scans
A tabela post_detail_scans é usada para criar varreduras que recuperam dados da tabela marketplace_post_scans. Ela também armazena o tamanho do lote, já que muitos sites impõem limites de taxa, como restrições ao número de publicações que podem ser lidas em 24 horas. Para gerir isso, dividimos as publicações em lotes de 10 ou 20 e atribuímos esses lotes a bots configurados com a finalidade scrape_post.
A tabela marketplace_post_scans armazena metadados das publicações, incluindo título, link, carimbo de data/hora e autor, mas exclui o conteúdo detalhado.
marketplace_post_details
Esta tabela armazena os resultados de cada varredura. Iniciamos as digitalizações em post_detail_scans, carregamo-las no scraper e começamos a recolher dados. Depois de recolhidos, os dados são guardados na tabela marketplace_post_details.
Acompanhamos detalhes abrangentes, incluindo texto original, idioma original, texto traduzido, sentimento, pontuações de confiança, autor, carimbo de data/hora e muito mais.
Modelos para gerir e exibir digitalizações
Precisamos de dois modelos: um para gerir as digitalizações e outro para exibir os resultados de cada digitalização. O modelo para gerir as digitalizações é posts_scans.html. Aqui está uma pré-visualização da sua interface:
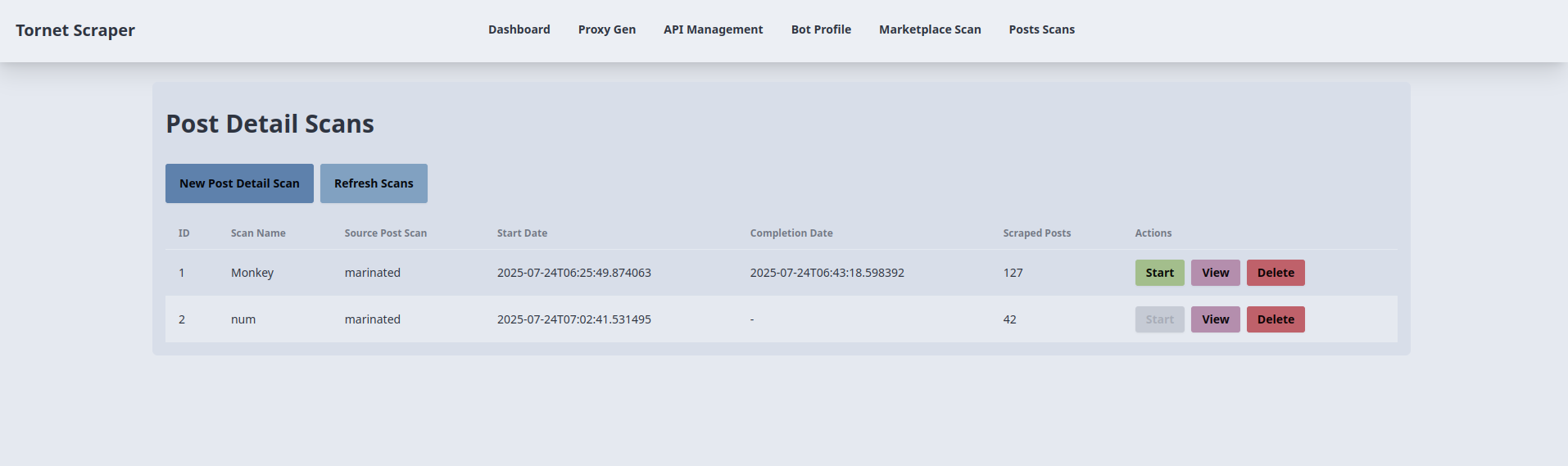
O código correspondente está localizado em app/templates/posts_scans.html.
-
Criação e início da digitalização de detalhes da publicação:
- Objetivo: Cria e inicia uma nova digitalização de detalhes da publicação.
- Interação com o back-end:
- O botão “Nova digitalização de detalhes da publicação” abre um modal (
newScanModal) com campos para o nome da digitalização, digitalização da publicação de origem (menu suspenso de digitalizações concluídas), tamanho do lote e URL do site. - O envio do formulário aciona uma solicitação AJAX POST para
/api/posts-scanner/create(gerenciada porposts_api_router) com os dados do formulário, seguida por uma POST para/api/posts-scanner/{id}/startpara iniciar a digitalização. - O backend cria um registo
PostDetailScan, liga-o a umMarketplacePostScane inicia a recolha. Os dados do formulário são armazenados emsessionStoragepara reutilização emstartScan(). Se for bem-sucedido, é apresentado um alerta de sucesso, o modal fecha-se erefreshScans()atualiza a tabela. Os erros acionam um alerta com a mensagem de erro.
- O botão “Nova digitalização de detalhes da publicação” abre um modal (
-
Listagem e atualização da varredura de detalhes da publicação:
- Objetivo: exibe e atualiza uma tabela de varreduras de detalhes da publicação.
- Interação com o back-end:
- A função
refreshScans(), chamada ao carregar a página e pelo botão “Atualizar varreduras”, envia uma solicitação AJAX GET para/api/posts-scanner/list(gerido porposts_api_router). - O backend retorna uma lista de registos
PostDetailScan(ID, nome da verificação, nome da verificação de origem, datas de início/conclusão, publicações extraídas, estado). A tabela é preenchida com ícones de status (por exemplo,badge-successpara concluído). Se não houver digitalizações, é exibida a mensagem “Nenhuma digitalização disponível”. Erros acionam um alerta.
- A função
-
Iniciando uma digitalização detalhada de publicação:
- Objetivo: Inicia uma digitalização detalhada de publicação existente.
- Interação com o backend:
- O botão «Iniciar» de cada linha da tabela (desativado para digitalizações em execução) chama
startScan(scanId), enviando uma solicitação AJAX POST para/api/posts-scanner/{scanId}/start(tratada porposts_api_router) combatch_sizeesite_urldesessionStorage. - O backend inicia a verificação, atualizando o status
PostDetailScan. Se for bem-sucedido, um alerta de sucesso é exibido erefreshScans()atualiza a tabela. Erros acionam um alerta.
- O botão «Iniciar» de cada linha da tabela (desativado para digitalizações em execução) chama
-
Visualização dos resultados da verificação:
- Objetivo: Redireciona para uma página de resultados de uma verificação específica.
- Interação do backend:
- O botão “Ver” de cada linha da tabela chama
viewResults(scanId, scanName), redirecionando para/posts-scan-result/{scanId}?name={scanName}(gerido pormain.py::posts_scan_result). - O backend renderiza um modelo com detalhes da verificação, buscando os registos
MarketplacePostDetailsassociados. Nenhuma chamada AJAX direta ocorre aqui, mas o redirecionamento depende dos dados do backend.
- O botão “Ver” de cada linha da tabela chama
-
Excluindo uma verificação de detalhes da publicação:
- Objetivo: exclui uma verificação de detalhes da publicação.
- Interação com o backend:
- O botão «Eliminar» de cada linha da tabela chama
deleteScan(scanId)após a confirmação do utilizador, enviando um pedido AJAX DELETE para/api/posts-scanner/{scanId}(gerido porposts_api_router). - O backend remove o registo
PostDetailScan. Se for bem-sucedido, é apresentado um alerta de sucesso erefreshScans()atualiza a tabela. Os erros acionam um alerta.
- O botão «Eliminar» de cada linha da tabela chama
-
Preenchimento do menu suspenso de digitalização de publicações de origem:
- Objetivo: Preenche o menu suspenso de digitalização de origem com digitalizações de publicações concluídas.
- Interação do backend:
- Ao carregar a página, uma solicitação AJAX GET para
/api/posts-scanner/completed-post-scans(tratada porposts_api_router) busca uma lista de nomesMarketplacePostScanconcluídos. - O backend retorna os nomes da verificação, que são adicionados como opções ao menu suspenso no modal de nova verificação. Os erros são registados no console.
- Ao carregar a página, uma solicitação AJAX GET para
Modelo para exibir o resultado de cada digitalização
Ao exibir o resultado de cada digitalização do marketplace, usamos modais para exibi-los. Mas aqui, como há muitas informações, pesquisa e filtragem envolvidas, precisamos de um modelo diferente apenas para mostrar os resultados.
Veja como estou usando a pesquisa e a classificação de sentimentos para filtrar resultados positivos que discutem IAB e têm a palavra-chave “shell” no título:
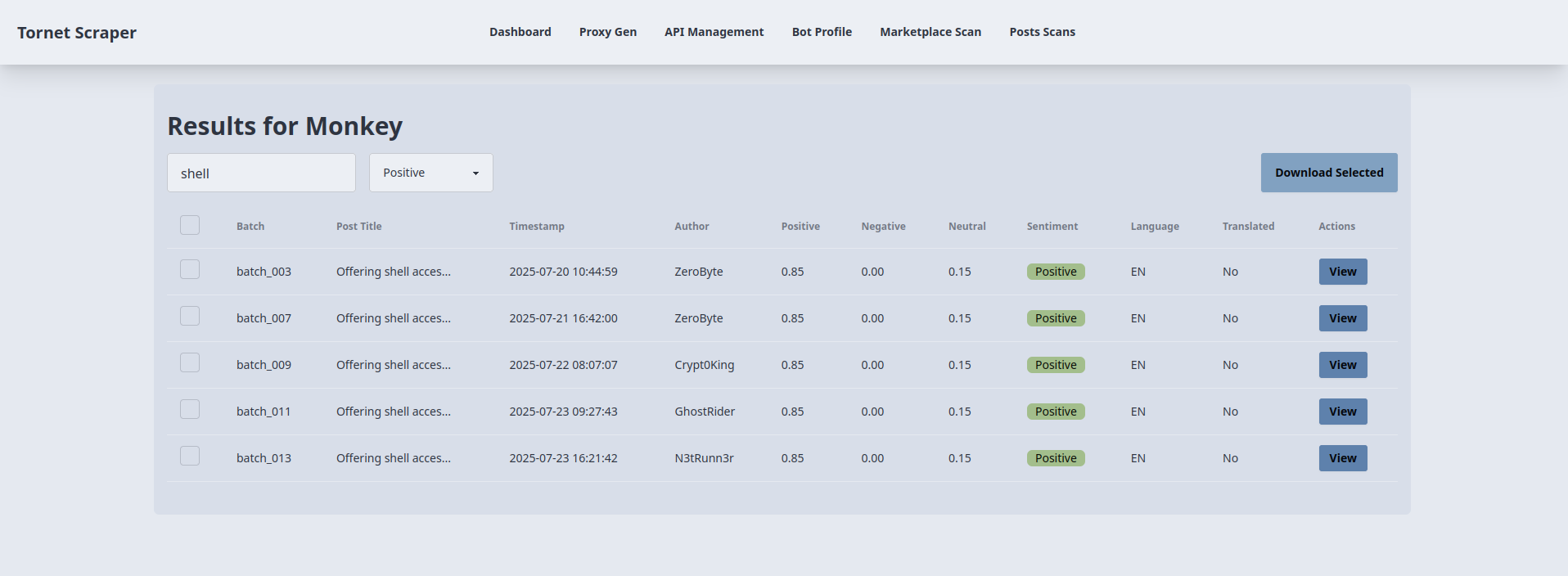
Como analista, algo assim é extremamente útil para si, pois pode filtrar os resultados, visualizar apenas o que considera crítico na sua investigação e descarregá-los como JSON.
O modelo usado para exibir o resultado de cada verificação está em: app/templates/posts_scan_result.html.
-
Carregando resultados da verificação:
- Objetivo: exibe os resultados de uma verificação detalhada de uma publicação específica em uma tabela.
- Interação com o back-end:
- Ao carregar a página, a função
loadResults()extrai oscanIdda URL e envia uma solicitação AJAX GET para/api/posts-scanner/{scanId}/results(gerido porposts_api_router). - O backend consulta a tabela
MarketplacePostDetailspara obter os resultados da verificação (ID, título, carimbo de data/hora, autor, nome do lote, pontuações de sentimento, idioma, texto traduzido) e devolve-os como JSON. - A tabela é preenchida com linhas, cada uma mostrando uma caixa de seleção, nome do lote, título truncado, carimbo de data/hora, autor, pontuações de sentimento (positivo, negativo, neutro), sentimento dominante (calculado no lado do cliente como a pontuação mais alta), idioma e status da tradução. Erros acionam um alerta.
- Ao carregar a página, a função
-
Pesquisa e filtragem de sentimentos:
- Objetivo: Filtra a tabela de resultados por título da publicação e sentimento.
- Interação com o backend:
- A função
filterTable(), acionada por keyup em#searchInpute alteração em#sentimentFilter, filtra as linhas da tabela no lado do cliente com base no termo de pesquisa (título) e no sentimento selecionado (all,positive,negative,neutral). - Não são feitas chamadas diretas ao backend; a filtragem usa o atributo
data-sentimentdefinido duranteloadResults(). As linhas são mostradas ou ocultadas com base nas correspondências, garantindo atualizações dinâmicas sem solicitações adicionais.
- A função
-
Visualização dos detalhes da publicação:
- Objetivo: exibe informações detalhadas sobre uma publicação selecionada em um modal.
- Interação com o backend:
- O botão «Ver» de cada linha da tabela preenche o
viewModalcom os dados armazenados nos atributosdata-*do botão (título, carimbo de data/hora, autor, lote, pontuações de sentimento, sentimento, idioma, estado da tradução, link, conteúdo original/traduzido) da resposta inicialloadResults(). - Não é necessária nenhuma chamada adicional ao backend; o modal exibe campos e áreas de texto somente para leitura. O botão “Fechar” oculta o modal sem interação com o backend.
- O botão «Ver» de cada linha da tabela preenche o
-
Download dos resultados selecionados:
- Objetivo: exporta os resultados das publicações selecionadas como um ficheiro JSON.
- Interação com o backend:
- O botão «Transferir selecionados» (
#downloadSelected) recolhe os IDs das linhas marcadas (filtradas por visibilidade) e envia um pedido AJAX POST para/api/posts-scanner/{scanId}/download(tratado porposts_api_router) com a matrizpost_ids. - O backend recupera os registos
MarketplacePostDetailscorrespondentes e devolve-os como JSON. O cliente cria um ficheiro JSON transferível (scan_{scanId}_results.json) utilizando umBlob. Se não forem selecionadas linhas ou se ocorrer um erro, é apresentado um alerta.
- O botão «Transferir selecionados» (
Rotas do backend
O código do backend está localizado em app/routes/posts.py. A seguir, apresentamos uma explicação das principais funções.
get_post_scans:
- Objetivo: recupera todas as digitalizações de detalhes de publicações da base de dados, incluindo detalhes como ID da digitalização, nome, nome da digitalização de origem, datas de início/conclusão, estado e a contagem de publicações extraídas.
- Principais funcionalidades:
- Consulta
PostDetailScane une comMarketplacePostDetailspara contar as publicações recolhidas. - Retorna uma resposta JSON com detalhes da digitalização.
- Lida com erros com um código de estado 500 se a consulta falhar.
- Consulta
get_completed_post_scans:
- Objetivo: Busca os nomes das varreduras
MarketplacePostScanconcluídas para uso em um menu suspenso. - Principais recursos:
- Filtra varreduras com status
COMPLETEDe data de conclusão diferente de nula. - Retorna uma lista JSON de nomes de varreduras.
- Gera um erro 500 se a consulta falhar.
- Filtra varreduras com status
create_post_scan:
- Objetivo: Cria uma nova verificação de detalhes da publicação com base em uma configuração fornecida.
- Principais recursos:
- Valida se o nome da verificação é único e se a verificação de origem foi concluída.
- Cria um registo
PostDetailScancom o estadoSTOPPEDe armazena o tamanho do lote e o URL do site. - Retorna uma resposta JSON com o ID da verificação e uma mensagem de sucesso.
- Lida com nomes de verificação duplicados (400) ou verificações de origem ausentes (404).
start_post_scan:
- Objetivo: Inicia uma verificação detalhada de publicações, processando publicações de uma verificação de origem em lotes usando vários bots.
- Principais recursos:
- Verifica se a verificação existe, não está em execução e possui as APIs necessárias (tradução e IAB) e bots ativos.
- Divide as publicações em lotes e atribui-as a bots para raspagem, tradução e classificação simultâneas.
- Utiliza
scrape_post_details,translate_stringeiab_classifypara processar publicações. - Guarda os resultados em
MarketplacePostDetailse atualiza o estado da verificação paraRUNNINGouCOMPLETED/STOPPEDcom base no sucesso. - Trata os erros com códigos de estado HTTP apropriados (404, 400, 500).
delete_post_scan:
- Objetivo: exclui uma verificação de detalhes de publicação especificada do banco de dados.
- Principais recursos:
- Verifica se a verificação existe antes da exclusão.
- Remove o registo
PostDetailScane confirma a alteração. - Retorna uma mensagem de sucesso JSON ou um erro 404 se a verificação não for encontrada.
- Lida com erros inesperados com um código de status 500.
get_scan_results:
- Objetivo: Recupera resultados detalhados de uma verificação de detalhes de uma publicação específica.
- Principais funcionalidades:
- Consulta
MarketplacePostDetailspara um determinado ID de verificação. - Retorna uma resposta JSON com detalhes como título, conteúdo, autor, carimbo de data/hora, dados de tradução e pontuações de classificação.
- Apresenta um erro 500 se a consulta falhar.
- Consulta
download_post_results:
- Objetivo: Faz o download de detalhes específicos de uma publicação para um determinado ID de verificação com base nos IDs de publicação fornecidos.
- Principais funcionalidades:
- Verifica se a verificação existe e se os IDs de publicação solicitados são válidos.
- Retorna uma resposta JSON com detalhes da publicação selecionada, incluindo título, carimbo de data/hora, autor, pontuações de sentimento e dados de tradução.
- Gera um erro 404 se a digitalização ou as publicações não forem encontradas ou um erro 500 para outros problemas.
Utilizamos a função detect da biblioteca langdetect dentro de scrape_post_batches. Se desejar, pode modificar a função translate_string em post_scraper.py para incorporar também langdetect. Embora essa seja uma opção, prefiro a abordagem atual por sua eficiência.
Teste
Para testar esta funcionalidade, configure os seguintes componentes:
- Recolha os detalhes das publicações do marketplace usando a página
/marketplace-scan. - Configure uma API de IA para contornar o CAPTCHA.
- Crie pelo menos dois perfis de bot com o objetivo definido como
scrape_poste faça login para obter cookies de sessão. - Configure a API DeepL para tradução.
- Configure a API IAB para identificar Initial Access Brokers.
Para a API IAB, você precisará do seguinte prompt:
Does this post discuss selling initial access to a company (e.g., RDP, VPN, admin access), selling unrelated items (e.g., accounts, tools), or warnings/complaints? Classify it as:
- Positive Posts: direct sale of unauthorized access to a company, this usually include the target's name.
- Neutral Posts: general offers for tools, exploits or malware without naming a specific target.
- Negative Posts: off-topic or unrelated services such as hosting, spam tools or generic VPS sales.
The content must be specifically about selling access to a company or business whose name is mentioned in the post.
Return **only** a JSON object with:
- `classification`: "Positive", "Neutral", or "Negative".
- `scores`: Probabilities for `positive`, `neutral`, `negative` (summing to 1).
Wrap the JSON in ```json
{
...
}
``` to ensure proper formatting. Do not include any reasoning or extra text.
Post:
```markdown
TARGET-POST-PLACEHOLDER
```
Pode modificar o prompt e experimentar por conta própria.