In diesem Abschnitt lernen wir, wie man Beiträge aus dem Marktplatz der Verkäufer scrapt und die Scraping-Aufgaben auf mehrere Bots verteilt, damit sie gleichzeitig ausgeführt werden können.
Das Ziel ist es, die Aufgaben auf die Bots aufzuteilen, da die meisten Foren eine Begrenzung der Anzahl der Anfragen, die Sie senden können, vorgeben. In „tornet_forum“ gibt es keine Begrenzung für die Navigation zwischen den Seiten, und Sie können zwischen den Seiten wechseln, ohne angemeldet zu sein.
Um jedoch auf verschiedene Schutzmechanismen vorbereitet zu sein, verwenden wir Bots mit aktiven Sitzungen für das Scraping. Obwohl dies für „tornet_forum“ nicht erforderlich ist, können angemeldete Sitzungen für andere Zielseiten, auf die Sie stoßen, notwendig sein. Da ich selbst schon Daten von solchen Seiten gescrapt habe, verstehe ich die Herausforderungen, denen Sie begegnen könnten, und dieser Ansatz rüstet Sie für jedes Szenario.
Die Themen dieses Abschnitts umfassen Folgendes:
- Datenbankmodelle
- Marktplatz-Scraper-Module
- Marktplatz-Backend-Routen
- Marktplatz-Frontend-Vorlage
- Testen
Datenbankmodelle
Ihre Modelle befinden sich in app/database/models.py. Sie benötigen 4 Modelle, um die Daten ordnungsgemäß zu organisieren:
class MarketplacePaginationScan(Base):
__tablename__ = "marketplace_pagination_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False)
pagination_url = Column(String, nullable=False)
max_page = Column(Integer, nullable=False)
batches = Column(Text, nullable=True)
timestamp = Column(DateTime, default=datetime.utcnow)
class ScanStatus(enum.Enum):
RUNNING = "running"
COMPLETED = "completed"
STOPPED = "stopped"
class MarketplacePostScan(Base):
__tablename__ = "marketplace_post_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False, unique=True)
pagination_scan_name = Column(String, ForeignKey("marketplace_pagination_scans.scan_name"), nullable=False)
start_date = Column(DateTime(timezone=True), default=datetime.utcnow)
completion_date = Column(DateTime(timezone=True), nullable=True)
status = Column(Enum(ScanStatus), default=ScanStatus.STOPPED, nullable=False)
timestamp = Column(DateTime, default=datetime.utcnow)
class MarketplacePost(Base):
__tablename__ = "marketplace_posts"
id = Column(Integer, primary_key=True, index=True)
scan_id = Column(Integer, ForeignKey("marketplace_post_scans.id"), nullable=False)
timestamp = Column(String, nullable=False)
title = Column(String, nullable=False)
author = Column(String, nullable=False)
link = Column(String, nullable=False)
__table_args__ = (UniqueConstraint('scan_id', 'timestamp', name='uix_scan_timestamp'),)
Für diese Funktionalität benötigen wir mehrere Modelle, um alle folgenden Aufgaben auszuführen:
-
MarketplacePaginationScan:- Zweck: Stellt eine Paginierungsscan-Konfiguration zum Scraping eines Marktplatzes dar. Es speichert Details zu einem Scan, der die Seiten eines Marktplatzes auflistet, wie z. B. die Basis-URL und die maximale Anzahl der zu scannenden Seiten.
- Schlüsselfelder:
id: Eindeutige Kennung für den Scan.scan_name: Eindeutiger Name für den Paginierungsscan.pagination_url: Die Basis-URL, die für die Paginierung verwendet wird.max_page: Die maximale Anzahl der zu scannenden Seiten.batches: Speichert serialisierte Batch-Daten (z. B. JSON) für die Verarbeitung von Seiten.timestamp: Zeichnet auf, wann der Scan erstellt wurde.
-
ScanStatus (Enum):- Zweck: Definiert die möglichen Zustände eines Post-Scans, die zur Verfolgung des Status eines
MarketplacePostScanverwendet werden. - Werte:
RUNNING: Der Scan wird derzeit ausgeführt.COMPLETED: Der Scan wurde erfolgreich abgeschlossen.STOPPED: Der Scan wird nicht ausgeführt (Standard oder manuell angehalten).
- Zweck: Definiert die möglichen Zustände eines Post-Scans, die zur Verfolgung des Status eines
-
MarketplacePostScan:- Zweck: Stellt einen Scan dar, der Beiträge aus einem Marktplatz sammelt und mit einem bestimmten Paginierungsscan verknüpft ist. Er verfolgt die Metadaten und den Status des Scans.
- Schlüsselfelder:
id: Eindeutige Kennung für den Post-Scan.scan_name: Eindeutiger Name für den Post-Scan.pagination_scan_name: Verweist anhand desscan_nameauf den zugehörigenMarketplacePaginationScan.start_date: Zeitpunkt, zu dem der Scan gestartet wurde.completion_date: Zeitpunkt, zu dem der Scan abgeschlossen wurde (falls zutreffend).status: Aktueller Status des Scans (aus der AufzählungScanStatus).timestamp: Zeichnet auf, wann der Scan erstellt wurde.
-
MarketplacePost:- Zweck: Speichert einzelne Beiträge, die während eines
MarketplacePostScangesammelt wurden. Jeder Beitrag ist mit einem bestimmten Scan verknüpft und enthält Details zum Beitrag. - Schlüsselfelder:
id: Eindeutige Kennung für den Beitrag.scan_id: Verweist auf denMarketplacePostScan, zu dem dieser Beitrag gehört.timestamp: Zeitstempel des Beitrags (als Zeichenfolge).title: Titel des Marktplatzbeitrags.author: Autor des Beitrags.link: URL zum Beitrag.__table_args__: Stellt die Eindeutigkeit der Beiträge anhand vonscan_idundtimestampsicher, um Duplikate zu vermeiden.
- Zweck: Speichert einzelne Beiträge, die während eines
Marktplatz-Scraper-Module
Um ein Beispiel für die Funktionsweise des Marktplatz-Scrapers zu sehen, öffnen Sie app/scrapers/marketplace_scraper.py.
import json
import requests
from bs4 import BeautifulSoup
import logging
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def create_pagination_batches(url_template, max_page):
"""
Given a web URL with max pagination number, this function returns batches of 10 pagination ranges.
"""
if max_page < 1:
return json.dumps({})
all_urls = [url_template.format(page=page) for page in range(max_page, 0, -1)]
batch_size = 10
batches = {f"{i//batch_size + 1}": all_urls[i:i + batch_size] for i in range(0, len(all_urls), batch_size)}
return json.dumps(batches)
def scrape_posts(session, proxy, useragent, pagination_range, timeout=30):
"""
Given a list of web pages, it scraps all post details from every pagination page.
"""
posts = {}
headers = {'User-Agent': useragent}
proxies = {'http': proxy, 'https': proxy} if proxy else None
for url in pagination_range:
logger.info(f"Scraping URL: {url}")
try:
response = session.get(url, headers=headers, proxies=proxies, timeout=timeout)
logger.info(f"Response status code: {response.status_code}")
response.raise_for_status()
# Log response size and snippet
logger.debug(f"Response size: {len(response.text)} bytes")
logger.debug(f"Response snippet: {response.text[:200]}...")
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.select_one('table.table-dark tbody')
if not table:
logger.error(f"No table found on {url}")
continue
table_rows = table.select('tr')
logger.info(f"Found {len(table_rows)} table rows on {url}")
for row in table_rows[:10]:
try:
title = row.select_one('td:nth-child(1)').text.strip()
author = row.select_one('td:nth-child(2) a').text.strip()
timestamp = row.select_one('td:nth-child(3)').text.strip()
link = row.select_one('td:nth-child(5) a')['href']
logger.info(f"Extracted post: timestamp={timestamp}, title={title}, author={author}, link={link}")
posts[timestamp] = {
'title': title,
'author': author,
'link': link
}
except AttributeError as e:
logger.error(f"Error parsing row on {url}: {e}")
continue
except requests.RequestException as e:
logger.error(f"Error scraping {url}: {e}")
continue
logger.info(f"Total posts scraped: {len(posts)}")
return json.dumps(posts)
if __name__ == "__main__":
# Create a proper requests.Session and set the cookie
session = requests.Session()
session.cookies.set('session', '.eJwlzsENwzAIAMBd_O4DbINNlokAg9Jv0ryq7t5KvQnuXfY84zrK9jrveJT9ucpWbA0xIs5aZ8VM5EnhwqNNbblWVlmzMUEH9MkDmwZQTwkFDlqhkgounTm9Q7U0nYQsw6MlmtKYqBgUpAMkuJpnuEMsYxtQfpH7ivO_wfL5AtYwMDs.aH1ifQ.uRrB1FnMt3U_apyiWitI9LDnrGE')
proxy = "socks5h://127.0.0.1:49075"
useragent = "Mozilla/5.0 (Windows NT 11.0; Win64; x64; rv:140.0) Gecko/20100101 Firefox/140.0"
pagination_range = [
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=1",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=2",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=3"
]
timeout = 30
result = scrape_posts(session, proxy, useragent, pagination_range, timeout)
print(result)
Wir benötigen zwei separate Funktionen, um diese Aufgaben auszuführen:
- create_pagination_batches(url_template, max_page)
- Generiert Batches von URLs für die Paginierung, indem aus einer vorgegebenen URL-Vorlage und einer maximalen Seitenanzahl Gruppen von 10 Seiten-URLs erstellt und als JSON-Zeichenkette zurückgegeben werden.
- scrape_posts(session, proxy, useragent, pagination_range, timeout)
- Kratzt Post-Details (Titel, Autor, Zeitstempel, Link) aus einer Liste von Webseiten-URLs unter Verwendung einer Requests-Sitzung, eines Proxys und eines User-Agents, parst HTML mit
BeautifulSoupund gibt die gesammelten Daten als JSON-Zeichenkette zurück.
- Kratzt Post-Details (Titel, Autor, Zeitstempel, Link) aus einer Liste von Webseiten-URLs unter Verwendung einer Requests-Sitzung, eines Proxys und eines User-Agents, parst HTML mit
Wir beschränken die Paginierungs-Batches auf 10 Seiten, da dies der von uns festgelegte Schwellenwert ist. Sie können diese Grenze anpassen, aber wenn Ihre Bots in wenigen Sekunden auf 50 Paginierungsseiten zugreifen, kann dies zu einer Sperrung des Kontos führen.
Später werden wir die Funktion scrape_posts verwenden, um Bereiche von Paginierungs-Batches zu verarbeiten, wodurch das Scraping von Beiträgen aus allen Batches ermöglicht wird.
Erstellen des Marktplatz-Backends
Das Backend mag auf den ersten Blick schwieriger erscheinen als unsere bisherigen Aufgaben. Den Backend-Code finden Sie in app/routes/marketplace.py.
Diese Komplexität ergibt sich aus der Parallelität, die es uns ermöglicht, die Daten-Scraping-Aufgaben auf alle verfügbaren Bots zu verteilen, was die Effizienz erhöht, aber auch die Komplexität erhöht. Beachten Sie, dass alle Scans im Hintergrund ausgeführt werden, sodass sie auch dann fortgesetzt werden, wenn Sie zwischen den Seiten navigieren.
Die Funktionen mögen komplex erscheinen, aber das ist ein natürlicher Teil des Lernprozesses. Unser Ziel ist es, einen fortschrittlichen Web-Scraper für die langfristige Datenerfassung zu entwickeln, eine Aufgabe, die von Natur aus anspruchsvoll ist.
get_pagination_scans
- Endpunkt:
GET /api/marketplace-scan/list - Zweck: Ruft alle Paginierungsscans aus der Datenbank ab.
- Funktionalität:
- Abfrage der Tabelle
MarketplacePaginationScan, um alle Datensätze abzurufen. - Protokollierung der Anzahl der abgerufenen Scans.
- Formatierung jedes Scans in ein JSON-kompatibles Wörterbuch mit den Feldern
id,scan_name,pagination_url,max_page,batchesundtimestampenthält. - Gibt eine
JSONResponsemit der Liste der Scans und einem Statuscode 200 zurück. - Behandelt Ausnahmen, indem Fehler protokolliert und bei Auftreten eines Fehlers eine
HTTPExceptionmit dem Statuscode 500 ausgelöst wird.
- Abfrage der Tabelle
enumerate_pages
- Endpunkt:
POST /api/marketplace-scan/enumerate - Zweck: Erstellt einen neuen Paginierungsscan, um Seiten für das Scraping aufzulisten.
- Funktionalität:
- Überprüft, ob der angegebene
scan_namebereits in der Datenbank vorhanden ist. - Ruft
create_pagination_batchesauf, um basierend auf der angegebenenpagination_urlundmax_pageBatches von URLs zu generieren. - Erstellt einen neuen
MarketplacePaginationScanmit den Scan-Details und speichert die Batches als JSON. - Überträgt den Datensatz in die Datenbank und protokolliert die Erstellung.
- Speichert eine Erfolgsmeldung in der Sitzung und gibt eine
JSONResponsemit dem Statuscode 201 zurück. - Behandelt doppelte Scan-Namen (400), Datenbankfehler (500, mit Rollback) und andere Ausnahmen durch Protokollierung und Auslösen entsprechender
HTTPExceptions.
- Überprüft, ob der angegebene
delete_pagination_scan
- Endpunkt:
DELETE /api/marketplace-scan/{scan_id} - Zweck: Löscht einen Paginierungsscan anhand seiner ID.
- Funktionalität:
- Fragt die Tabelle
MarketplacePaginationScannach dem Scan mit der angegebenenscan_idab. - Wenn der Scan nicht gefunden wird, protokolliert sie eine Warnung und löst eine 404
HTTPExceptionaus. - Löscht den Scan aus der Datenbank und führt die Transaktion aus.
- Protokolliert die Löschung und speichert eine Erfolgsmeldung in der Sitzung.
- Gibt eine
JSONResponsemit dem Statuscode 200 zurück. - Behandelt Fehler durch Protokollierung, Zurücksetzen der Transaktion und Auslösen einer 500
HTTPException.
- Fragt die Tabelle
get_post_scans
- Endpunkt:
GET /api/marketplace-scan/posts/list - Zweck: Ruft alle Post-Scans aus der Datenbank ab.
- Funktionalität:
- Abfrage der Tabelle
MarketplacePostScan, um alle Datensätze abzurufen. - Protokollierung der Anzahl der abgerufenen Scans.
- Formatierung jedes Scans in ein JSON-kompatibles Wörterbuch mit
id,scan_name,pagination_scan_name,start_date,completion_date,statusundtimestamp. - Gibt eine
JSONResponsemit der Liste der Scans und einem Statuscode 200 zurück. - Behandelt Ausnahmen durch Protokollierung und Auslösen einer 500
HTTPException.
- Abfrage der Tabelle
get_post_scan_status
- Endpunkt:
GET /api/marketplace-scan/posts/{scan_id}/status - Zweck: Ruft den Status eines bestimmten Post-Scans anhand seiner ID ab.
- Funktionalität:
- Fragt die Tabelle
MarketplacePostScannach dem Scan mit der angegebenenscan_idab. - Wenn der Scan nicht gefunden wird, protokolliert eine Warnung und löst eine 404
HTTPExceptionaus. - Protokolliert den Status und gibt eine
JSONResponsemit derid, demscan_nameund demstatusdes Scans (als Zeichenfolgenwert) mit einem Statuscode 200 zurück. - Behandelt Ausnahmen durch Protokollierung und Auslösen einer 500
HTTPException.
- Fragt die Tabelle
enumerate_posts
- Endpunkt:
POST /api/marketplace-scan/posts/enumerate - Zweck: Erstellt einen neuen Post-Scan, der mit einem Paginierungs-Scan verknüpft ist.
- Funktionalität:
- Überprüft, ob der angegebene
scan_namebereits existiert. - Überprüft, ob der referenzierte
pagination_scan_namein der TabelleMarketplacePaginationScanexistiert. - Stellt sicher, dass aktive Bots mit dem Zweck
SCRAPE_MARKETPLACEund gültigen Sitzungen vorhanden sind. - Erstellt einen neuen
MarketplacePostScan-Datensatz mit dem angegebenenscan_name,pagination_scan_nameund dem anfänglichen StatusSTOPPED. - Speichert den Datensatz in der Datenbank und protokolliert die Erstellung.
- Speichert eine Erfolgsmeldung in der Sitzung und gibt eine „JSONResponse“ mit dem Statuscode 201 zurück.
- Behandelt Fehler für doppelte Scan-Namen (400), fehlende Paginierungsscans (404), keine aktiven Bots (400) oder andere Probleme (500, mit Rollback).
- Überprüft, ob der angegebene
start_post_scan
- Endpunkt:
POST /api/marketplace-scan/posts/{scan_id}/start - Zweck: Startet einen Post-Scan, indem Batches von URLs mit verfügbaren Bots verarbeitet werden.
- Funktionalität:
- Ruft den
MarketplacePostScananhand derscan_idab und überprüft, ob er vorhanden ist. - Stellt sicher, dass der Scan nicht bereits ausgeführt wird (löst 400 aus, wenn dies der Fall ist).
- Überprüft die Verfügbarkeit von Bots mit dem Zweck
SCRAPE_MARKETPLACE. - Ruft den zugehörigen
MarketplacePaginationScanund seine Stapel ab. - Aktualisiert den Scan-Status auf
RUNNING, legt dasstart_datefest und löscht dascompletion_date. - Führt eine asynchrone
scrape_batches-Aufgabe aus, um Batches gleichzeitig zu verarbeiten: - Weist Batches mithilfe eines
ThreadPoolExecutorverfügbaren Bots zu. - Jeder Bot scrapt einen Batch von URLs mithilfe der Funktion
scrape_posts, mit Sitzungscookies und Tor-Proxy. - Behandelt JSON-Parsing-Fehler durch Bereinigung der Daten (Normalisierung von Unicode, Entfernen von Steuerzeichen).
- Speichert eindeutige Beiträge in der Tabelle „MarketplacePost“, um Duplikate zu vermeiden.
- Protokolliert den Fortschritt und Fehler für jeden Batch.
- Markiert den Scan bei Erfolg als „COMPLETED“ und bei Fehler als „STOPPED“.
- Speichert eine Erfolgsmeldung in der Sitzung und gibt eine „JSONResponse“ mit dem Statuscode 200 zurück.
- Behandelt Fehler für fehlende Scans (404), laufende Scans (400), keine Bots (400), fehlende Stapel (400) oder andere Probleme (500, mit Rollback).
- Ruft den
delete_post_scan
- Endpunkt:
DELETE /api/marketplace-scan/posts/{scan_id} - Zweck: Löscht einen Post-Scan anhand seiner ID.
- Funktionalität:
- Fragt die Tabelle
MarketplacePostScannach dem Scan mit der angegebenenscan_idab. - Wenn der Scan nicht gefunden wird, protokolliert er eine Warnung und löst eine 404
HTTPExceptionaus. - Löscht den Scan aus der Datenbank und führt die Transaktion aus.
- Protokolliert die Löschung und speichert eine Erfolgsmeldung in der Sitzung.
- Gibt eine
JSONResponsemit dem Statuscode 200 zurück. - Behandelt Fehler durch Protokollierung, Zurücksetzen der Transaktion und Auslösen einer 500
HTTPException.
- Fragt die Tabelle
get_scan_posts
- Endpunkt:
GET /api/marketplace-scan/posts/{scan_id}/posts - Zweck: Ruft alle Beiträge ab, die mit einem bestimmten Beitragsscan verknüpft sind.
- Funktionalität:
- Fragt die Tabelle
MarketplacePostScanab, um zu überprüfen, ob der Scan vorhanden ist. - Wenn der Scan nicht gefunden wird, protokolliert sie eine Warnung und löst eine 404
HTTPExceptionaus. - Abfrage der Tabelle
MarketplacePostnach allen Beiträgen, die mit derscan_idverknüpft sind. - Protokollierung der Anzahl der abgerufenen Beiträge.
- Formatierung jedes Beitrags in ein JSON-kompatibles Wörterbuch mit
id,timestamp,title,authorundlink. - Gibt eine „JSONResponse“ mit der Liste der Beiträge und einem Statuscode 200 zurück.
- Behandelt Ausnahmen durch Protokollierung und Auslösen einer 500 „HTTPException“.
- Fragt die Tabelle
Diese Funktion erfordert die manuelle Initiierung des Scrapings alle paar Stunden, um nach neuen Aktivitäten im Forum zu suchen. Eine Automatisierung dieses Prozesses wird vermieden, um Ressourcen zu sparen, da durch kontinuierliches Scraping häufig doppelte Daten erfasst würden, was zu einer ineffizienten Ressourcennutzung führen würde. Daher ist die ununterbrochene Ausführung von Marktplatz-Scans nicht der optimale Ansatz.
Aus meiner umfangreichen Erfahrung ist die Implementierung kontinuierlicher Scans alle paar Stunden aufgrund des erheblichen Ressourcenbedarfs generell nicht zu empfehlen.
In Modul 5 werden wir kontinuierliches Daten-Scraping implementieren, aber wie Sie feststellen werden, erzeugt dieser Prozess oft doppelte Daten.
Marktplatz-Frontend-Vorlage
Für den Marktplatz benötigen wir eine Vorlage mit zwei Registerkarten, mit denen wir innerhalb einer einzigen Seite zwischen mehreren Containern wechseln können. Anstatt zwei separate Routen zu erstellen, verwenden wir eine Route mit Registerkarten, um das Design zu optimieren.
Registerkarten können eine Webanwendung manchmal komplizieren, in diesem Fall vereinfachen sie sie jedoch, da keine zwei separaten Vorlagen erforderlich sind, die die App unnötig aufblähen würden. Im weiteren Verlauf werden wir mehrere Vorlagen untersuchen, aber für diese spezielle Funktionalität sind Registerkarten ausreichend.
Die Vorlage befindet sich unter app/templates/marketplace.html.
-
Registerkarten-Navigation für Paginierung und Post-Scans:
- Zweck: Organisiert die Oberfläche in die Registerkarten „Marketplace Pagination” (Marktplatz-Paginierung) und „Marketplace Posts” (Marktplatz-Beiträge).
- Backend-Interaktion: Die Funktion
openTab()schaltet die Sichtbarkeit des Tab-Inhalts (paginationoderposts) ohne direkte Backend-Aufrufe um. Die Anfangsdaten für beide Tabs (pagination_scansundpost_scans) werden vonmain.py::marketplacebereitgestellt und mit Jinja2 gerendert.
-
Aufzählung der Paginierungsscans:
- Zweck: Startet einen neuen Paginierungsscan, um Marktplatzseiten aufzulisten.
- Backend-Interaktion:
- Die Schaltfläche „Seiten auflisten“ öffnet ein Modal (
enumerate-modal) mit Feldern für den Scan-Namen, die Paginierungs-URL und die maximale Seitenanzahl. - Mit dem Absenden des Formulars wird eine AJAX-POST-Anfrage mit den Formulardaten an
/api/marketplace-scan/enumerate(verarbeitet vonmarketplace_api_router) gesendet. - Das Backend erstellt einen
MarketplacePaginationScan-Datensatz, verarbeitet die Paginierung und speichert die Ergebnisse. Bei Erfolg wird die Seite neu geladen, um die aktualisierte Scanliste anzuzeigen. Fehler lösen eine Warnmeldung mit der Fehlermeldung aus.
- Die Schaltfläche „Seiten auflisten“ öffnet ein Modal (
-
Aufzählung nach dem Scan:
- Zweck: Erstellt einen neuen Post-Scan basierend auf einem vorhandenen Paginierungs-Scan.
- Backend-Interaktion:
- Die Schaltfläche „Beiträge auflisten” öffnet ein Modal (
enumerate-posts-modal) mit Feldern für den Scan-Namen und einer Dropdown-Liste der vorhandenen Paginierungsscans (auspagination_scans). - Mit dem Absenden des Formulars wird eine AJAX-POST-Anfrage an
/api/marketplace-scan/posts/enumerate(verarbeitet vonmarketplace_api_router) mit dem Scan-Namen und dem ausgewählten Paginierungsscan gesendet. - Das Backend erstellt einen
MarketplacePostScan-Datensatz, der mit dem ausgewählten Paginierungsscan verknüpft ist. Bei Erfolg wird die Seite neu geladen, um die Tabelle mit den Post-Scans zu aktualisieren. Fehler lösen eine Warnmeldung aus.
- Die Schaltfläche „Beiträge auflisten” öffnet ein Modal (
-
Post-Scan-Verwaltung:
- Zweck: Startet, zeigt an oder löscht Post-Scans.
- Backend-Interaktion:
- Start: Jede Post-Scan-Zeile (nicht ausgeführt) verfügt über eine Schaltfläche „Start“, die eine AJAX-POST-Anfrage an
/api/marketplace-scan/posts/{scanId}/start(verarbeitet vonmarketplace_api_router) sendet, um den Scan zu starten. Bei Erfolg aktualisiert `refreshScans()“ die Tabelle. - Anzeigen: Eine Schaltfläche „Anzeigen“ öffnet ein Modal (
view-posts-modal-{scanId}), das Post-Daten über eine AJAX-GET-Anfrage an/api/marketplace-scan/posts/{scanId}/postsabruft und eine Tabelle mit Post-Details (Zeitstempel, Titel, Autor, Link) füllt. Fehler lösen eine Warnmeldung aus. - Löschen: Eine Schaltfläche „Löschen“ fordert zur Bestätigung auf und sendet eine AJAX-DELETE-Anfrage an
/api/marketplace-scan/posts/{scanId}, um den Scan aus der TabelleMarketplacePostScanzu entfernen. Bei Erfolg wird die Seite neu geladen. Fehler lösen eine Warnmeldung aus.
- Start: Jede Post-Scan-Zeile (nicht ausgeführt) verfügt über eine Schaltfläche „Start“, die eine AJAX-POST-Anfrage an
-
Anzeigen und Löschen von Paginierungsscans:
- Zweck: Zeigt Details zu Paginierungsscans an und ermöglicht deren Löschung.
- Backend-Interaktion:
- Anzeigen: Jede Zeile eines Paginierungsscans verfügt über eine Schaltfläche „Anzeigen“, die ein Modalfenster (
view-modal-{scanId}) mit schreibgeschützten Feldern für den Scan-Namen, die URL, die maximale Seitenanzahl und die Batches (im JSON-Format). Die Daten werden über Jinja2 auspagination_scansvorab geladen, sodass kein zusätzlicher Backend-Aufruf erforderlich ist. - Löschen: Eine Schaltfläche „Löschen“ (
deleteScan()) fordert zur Bestätigung auf und sendet eine AJAX-DELETE-Anfrage an/api/marketplace-scan/{scanId}, um den Scan aus der TabelleMarketplacePaginationScanzu entfernen. Bei Erfolg wird die Seite neu geladen. Fehler lösen eine Warnmeldung aus.
- Anzeigen: Jede Zeile eines Paginierungsscans verfügt über eine Schaltfläche „Anzeigen“, die ein Modalfenster (
-
Aktualisierung der Post-Scan-Tabelle:
- Zweck: Aktualisiert die Post-Scan-Tabelle, um den aktuellen Status widerzuspiegeln.
- Backend-Interaktion:
- Die Schaltfläche „Scans aktualisieren“ löst
refreshScans()aus und sendet eine AJAX-GET-Anfrage an/api/marketplace-scan/posts/list(verarbeitet vonmarketplace_api_router). - Das Backend gibt eine Liste der
MarketplacePostScan-Datensätze zurück (ID, Scan-Name, Paginierungs-Scan-Name, Start-/Abschlussdatum, Status).. Die Tabelle wird mit Status-Badges aktualisiert (z. B. „Abgeschlossen“, „Läuft“, „Gestoppt“). Fehler lösen eine Warnmeldung aus.
- Die Schaltfläche „Scans aktualisieren“ löst
Testen
Um mit dem Testen zu beginnen, müssen Sie die folgenden Komponenten konfigurieren:
- Fügen Sie eine CAPTCHA-API aus dem Endpunkt
/manage-apihinzu und aktivieren Sie sie. - Erstellen Sie mindestens zwei Bot-Profile und melden Sie sich an, um deren Sitzungen vom Endpunkt „/bot-profile“ abzurufen.
- Rufen Sie die URL für die Marktplatz-Paginierung aus „tornet_forum“ ab, zum Beispiel: „http://site.onion/category/marketplace/Sellers?page=1“.
- Navigieren Sie zu „/marketplace-scan“, wählen Sie die Registerkarte „Marketplace Pagination“ (Marktplatz-Paginierung), klicken Sie auf „Enumerate Pages“ (Seiten auflisten) und füllen Sie die Felder wie folgt aus:
- Scan Name (Scan-Name): „Monkey“
- Pagination URL (Paginierungs-URL): „http://site.onion/category/marketplace/Sellers?page={page}“
- Maximale Anzahl der Seiten: 14 (an die Gesamtzahl der verfügbaren Seiten anpassen).
Sobald der Scan abgeschlossen ist, klicken Sie auf , um die Ergebnisse anzuzeigen. Daraufhin wird ein Modal angezeigt. Nachfolgend finden Sie ein Beispiel dafür, wie Paginierungsstapel im JSON-Format angezeigt werden können:
"{\"1\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=14\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=13\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=12\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=11\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=9\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=8\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=7\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=6\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=5\"], \"2\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=4\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=3\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=2\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=1\"]}"
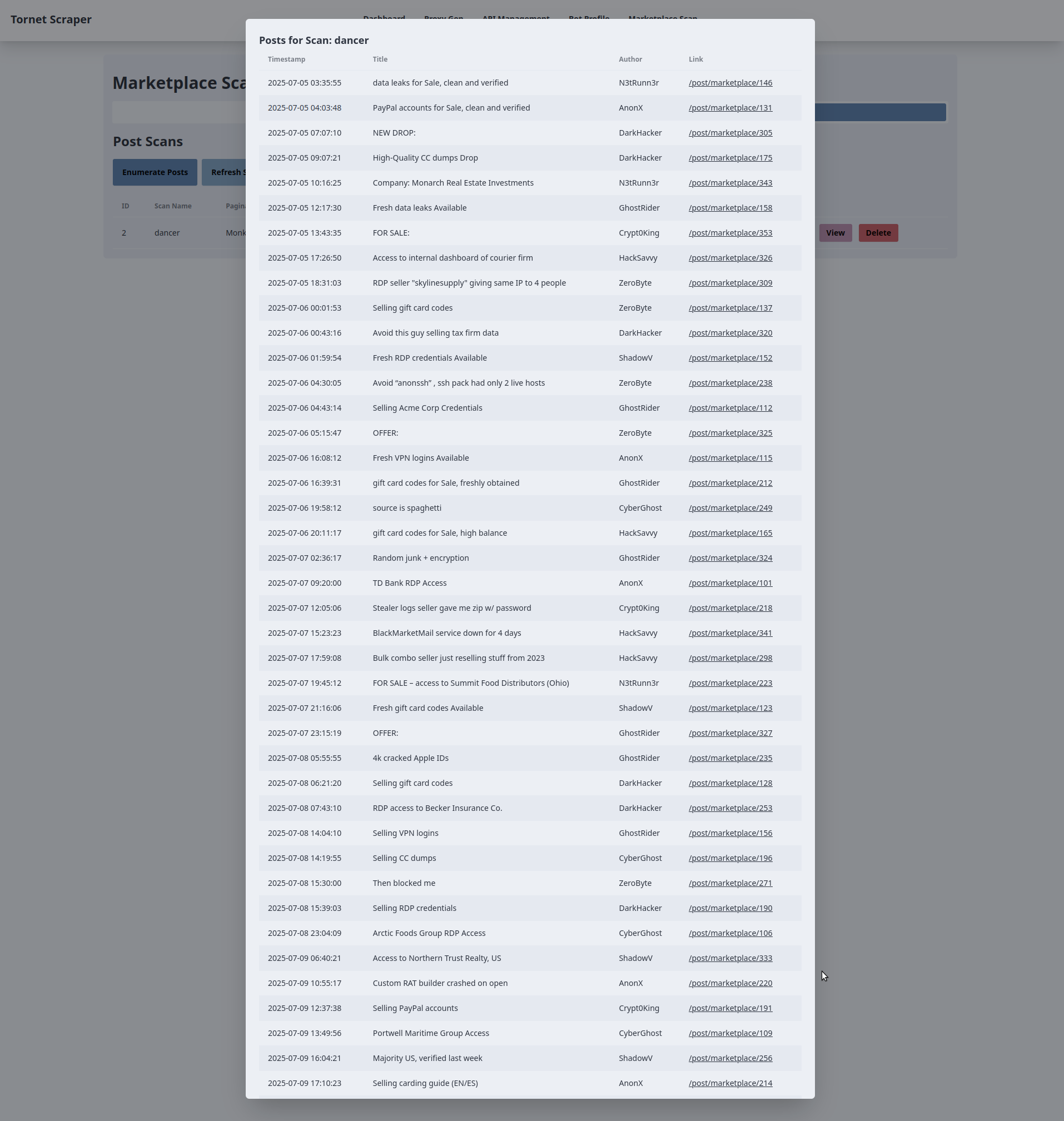
Um Beiträge im Marktplatz aufzulisten, gehen Sie wie folgt vor:
- Navigieren Sie zu
/marketplace-scanund wählen Sie die RegisterkarteMarketplace Posts. - Klicken Sie auf
Enumerate Posts, geben Sie einen Scan-Namen ein, wählen Sie den Paginierungs-Scan mit dem NamenMonkeyund klicken Sie aufStart Scan. Dadurch wird der Scan vorbereitet, aber nicht gestartet. - Kehren Sie zu „/marketplace-scan“ zurück, gehen Sie zur Registerkarte „Marketplace Posts“, suchen Sie Ihren Scan und klicken Sie auf die Schaltfläche „Start“, um den Scan zu starten.
Nachfolgend finden Sie ein Beispiel für die Ausgabe meiner Konfiguration:
2025-07-21 19:49:41,140 - INFO - Found 3 active bots for scan ID 6: ['DarkHacker', 'CyberGhost', 'ShadowV']
2025-07-21 19:49:41,141 - INFO - Starting post scan tyron (ID: 6) with 2 batches: ['1', '2']
2025-07-21 19:49:41,148 - INFO - Post scan tyron (ID: 6) status updated to RUNNING
2025-07-21 19:49:41,149 - INFO - Assigning batch 1 to bot DarkHacker (ID: 1)
2025-07-21 19:49:41,150 - INFO - Bot DarkHacker (ID: 1) starting batch 1 (10 URLs)
2025-07-21 19:49:41,150 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:41,151 - INFO - Assigning batch 2 to bot CyberGhost (ID: 2)
2025-07-21 19:49:41,151 - INFO - Bot CyberGhost (ID: 2) starting batch 2 (10 URLs)
2025-07-21 19:49:41,151 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:46,804 - INFO - Extracted post: timestamp=2025-07-19 07:04:10, title=OFFER:, author=DarkHacker, link=/post/marketplace/1901
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 06:33:54, title=Avoid “anonssh” , ssh pack had only 2 live hosts, author=N3tRunn3r, link=/post/marketplace/588
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 05:56:53, title=Access to Northern Trust Realty, US, author=DarkHacker, link=/post/marketplace/1532
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 05:20:53, title=FOR SALE:, author=GhostRider, link=/post/marketplace/2309
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 04:24:04, title=Custom RAT builder crashed on open, author=ShadowV, link=/post/marketplace/968
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:35:29, title=Private obfuscator for Python tools, author=GhostRider, link=/post/marketplace/1845
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:23:21, title="RootedShells" panel has backconnect, author=ZeroByte, link=/post/marketplace/1829
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:09:27, title=RDP seller "skylinesupply" giving same IP to 4 people, author=N3tRunn3r, link=/post/marketplace/1710
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:39:40, title=FOR SALE: DA access into Lakewood Public Services, author=ShadowV, link=/post/marketplace/972
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:37:10, title=4k cracked Apple IDs, author=DarkHacker, link=/post/marketplace/1154
2025-07-21 19:49:46,807 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=19
2025-07-21 19:49:46,995 - INFO - Response status code: 200
--- snip ---
--- snip ---
--- snip ---
2025-07-21 19:49:56,643 - INFO - Total posts scraped: 100
2025-07-21 19:49:56,643 - INFO - Bot CyberGhost completed batch 2, found 100 posts
2025-07-21 19:49:56,696 - INFO - Bot DarkHacker saved batch 1 posts to database for scan ID 6
2025-07-21 19:49:56,704 - INFO - Bot CyberGhost saved batch 2 posts to database for scan ID 6
2025-07-21 19:49:56,710 - INFO - Post scan tyron (ID: 6) completed successfully
Sobald der Scan gestartet ist, können Sie zwischen den Seiten wechseln, während der Scan im Hintergrund weiterläuft:
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on
Der Scan wird nach einem Neustart des Systems oder beim Beenden der Anwendung nicht fortgesetzt.
So könnte das Ergebnis eines Scans auf Ihrer Seite aussehen: