In diesem Abschnitt werde ich erläutern, wie Sie Bedrohungen über einen längeren Zeitraum ohne manuelles Eingreifen kontinuierlich überwachen können. Das Ziel ist klar: Erstellen Sie Ziele mit bestimmten Prioritäten und legen Sie fest, welche Art von Daten erfasst werden sollen und wie oft die Überwachung erfolgen soll.
Dieses Modul ist das, was ich rechtlich gesehen am ehesten als Vermittlung von Überwachungstechniken bezeichnen kann. Ich möchte damit nicht für Überwachung werben, aber die Überwachung ist eine gängige Praxis in der Bedrohungsanalyse. Viele Bedrohungsanalyse-Suites für Strafverfolgungsbehörden umfassen plattformübergreifende Überwachung mehrerer Foren und Websites, um die Aktivitäten von Benutzern zu verfolgen, aber wir werden hier nicht auf diese Komplexität eingehen.
Dieser Abschnitt umfasst die folgenden Themen:
- Komponenten des Profil-Scrapers
- Datenbankmodelle
- Backend der Beobachtungsliste
- Vorlage zum Erstellen von Beobachtungslisten
- Vorlage zum Anzeigen der Ergebnisse der Beobachtungsliste
- Testen
Komponenten des Profil-Scrapers
Im tornet_forum werden in den Benutzerprofilen Kommentare und Beiträge in einer Tabelle angezeigt, sodass wir alle Benutzeraktivitäten einsehen und auf Links zu Beiträgen zugreifen können, die sie kommentiert oder erstellt haben.
Hier ist ein Beispiel für eine Profilseite:

In „app/scrapers/profile_scraper.py” akzeptiert die Funktion „scrape_profile” einen Parameter namens „scrape_option”, der die Priorität des Scrapings festlegt: „everything” (alles), „comments” (nur Kommentare) oder „posts” (nur Beiträge).
Profil-Daten werden basierend auf festgelegten Intervallen gescrapt, z. B. alle 5 Minuten, 1 Stunde oder 24 Stunden.
1. scrape_profile:
- Zweck: Scrapt Profil-Details, Beiträge und Kommentare von einer bestimmten Profil-URL mithilfe von Web-Scraping mit BeautifulSoup.
- Wichtige Parameter:
url: URL der zu scrapend Profilseite.session_cookie: Authentifizierungs-Cookie für den Zugriff auf die Seite.user_agent: User-Agent-Zeichenfolge für HTTP-Anfrage-Header.tor_proxy: Proxy-Adresse für Tor-Routing.scrape_option: Gibt an, was gescrapt werden soll: „comments“, „posts“ oder „everything“ (Standard).
- Rückgabewerte: JSON-serialisierbares Wörterbuch mit Profildetails, Beiträgen, Kommentaren und deren Anzahl oder ein Fehlerwörterbuch, wenn das Scrapen fehlschlägt.
Später werden wir diese Funktion zum Scrapen von Profildaten verwenden. Beachten Sie, dass wir uns auf die Extraktion von Beitragstiteln, URLs und Zeitstempeln konzentrieren, nicht auf den vollständigen Inhalt von Beiträgen oder Kommentaren.
Datenbankmodelle
Wir benötigen zwei Tabellen: eine zur Verwaltung aller Ziele und eine zur Speicherung der Daten für jedes Ziel.
Diese Tabellen sind in app/database/models.py definiert:
class Watchlist(Base):
__tablename__ = "watchlists"
id = Column(Integer, primary_key=True, index=True)
target_name = Column(String, unique=True, index=True)
profile_link = Column(String)
priority = Column(String)
frequency = Column(String)
timestamp = Column(DateTime, default=datetime.utcnow)
class WatchlistProfileScan(Base):
__tablename__ = "watchlist_profile_scans"
id = Column(Integer, primary_key=True, index=True)
watchlist_id = Column(Integer, ForeignKey("watchlists.id"), nullable=False)
scan_timestamp = Column(DateTime, default=datetime.utcnow)
profile_data = Column(JSON)
Wir speichern alle Benutzerprofildaten als eine einzige, umfassende JSON-Zeichenkette.
Watchlist-Backend
Der Backend-Code befindet sich in app/routes/watchlist.py. Der Code ist umfangreich und komplex, konzentrieren Sie sich jedoch auf die folgenden beiden wichtigen Wörterbücher:
# Map stored frequency values to labels
FREQUENCY_TO_LABEL = {
"every 5 minutes": "critical",
"every 1 hour": "very high",
"every 6 hours": "high",
"every 12 hours": "medium",
"every 24 hours": "low"
}
# Map frequency labels to intervals (in seconds)
FREQUENCY_MAP = {
"critical": 5 * 60,
"very high": 60 * 60,
"high": 6 * 60 * 60,
"medium": 12 * 60 * 60,
"low": 24 * 60 * 60
}
Die Häufigkeit bestimmt, wie oft Profile gescrapt werden. Eine kritische Priorität löst alle 5 Minuten einen Scan aus, während eine niedrige Priorität ein weniger dringendes Ziel anzeigt, bei dem Profile alle 24 Stunden gescrapt werden.
Kernfunktionen in watchlist.py
-
schedule_all_tasks(db: Session):- Zweck: Plant beim Start der Anwendung das Scraping aller Elemente in der Beobachtungsliste.
- Funktionalität: Fragt alle Elemente in der
Watchlistaus der Datenbank ab und ruft für jedes Elementschedule_taskauf, um regelmäßige Scraping-Jobs einzurichten. - Wichtige Parameter:
db: SQLAlchemy-Datenbanksitzung.
- Rückgabewert: Keine. Protokolliert die Anzahl der geplanten Aufgaben oder Fehler.
- Hinweise: Behandelt Ausnahmen, um Startfehler zu vermeiden, und protokolliert Fehler zur Fehlerbehebung.
-
schedule_task(db: Session, watchlist_item: Watchlist):- Zweck: Plant einen wiederkehrenden Scraping-Job für einen bestimmten Watchlist-Eintrag.
- Funktionalität: Ordnet die Häufigkeit des Eintrags einem Intervall zu (z. B. „alle 24 Stunden“ zu 86.400 Sekunden) und plant einen Job mit APScheduler, um
scrape_and_saveim angegebenen Intervall auszuführen. - Wichtige Parameter:
db: SQLAlchemy-Datenbanksitzung.watchlist_item:Watchlist-Objekt mit Elementdetails.
- Rückgabewerte: Keine. Protokolliert Details zur Planung (z. B. Element-ID, Intervall).
- Hinweise: Verwendet
FREQUENCY_TO_LABELundFREQUENCY_MAPfür die Zuordnung von Häufigkeit zu Intervallen.
-
scrape_and_save(watchlist_id: int, db: Session = None):- Zweck: Führt einen einzelnen Scraping-Vorgang für ein Element der Beobachtungsliste durch und speichert die Ergebnisse.
- Funktionalität: Ruft das Element der Beobachtungsliste und einen zufälligen Bot mit dem Zweck „SCRAPE_PROFILE“ aus der Datenbank ab, ruft „scrape_profile“ mit den Bot-Anmeldedaten auf und speichert das Ergebnis in „WatchlistProfileScan“. Erstellt eine neue Datenbanksitzung, falls keine vorhanden ist.
- Wichtige Parameter:
watchlist_id: ID des zu scrapendem Watchlist-Elements.db: Optionale SQLAlchemy-Datenbanksitzung.
- Rückgabewerte: Keine. Protokolliert Erfolge, Fehler oder leere Ergebnisse und überträgt die Daten in die Datenbank.
- Hinweise: Verarbeitet das Parsen von Sitzungscookies, validiert die Scrape-Ergebnisse und sorgt für eine ordnungsgemäße Bereinigung der Sitzung.
-
get_watchlist(db: Session):- Zweck: Ruft alle Watchlist-Elemente ab.
- Funktionalität: Fragt die Tabelle
Watchlistab und gibt alle Elemente als Liste vonWatchlistResponse-Objekten zurück. - Wichtige Parameter:
db: SQLAlchemy-Datenbanksitzung (überDepends(get_db)).
- Rückgabewert: Liste von
WatchlistResponse-Objekten. - Hinweise: Löst einen HTTP-Fehler 500 mit Protokollierung aus, wenn die Abfrage fehlschlägt.
-
get_watchlist_item(item_id: int, db: Session):- Zweck: Ruft einen einzelnen Watchlist-Eintrag anhand seiner ID ab.
- Funktionalität: Fragt die
Watchlist-Tabelle nach der angegebenenitem_idab und gibt den Eintrag alsWatchlistResponse-Objekt zurück. - Wichtige Parameter:
item_id: ID des Watchlist-Eintrags.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewert:
WatchlistResponse-Objekt oder HTTP 404, wenn nicht gefunden. - Hinweise: Protokolliert Fehler und löst HTTP 500 bei unerwarteten Problemen aus.
-
create_watchlist_item(item: WatchlistCreate, db: Session):- Zweck: Erstellt einen neuen Watchlist-Eintrag und plant dessen Scraping-Aufgabe.
- Funktionalität: Überprüft, ob der
target_nameeindeutig ist, erstellt einenWatchlist-Eintrag, führt einen sofortigen Scan durch, wenn keine Scans vorhanden sind, und plant zukünftige Scans mitschedule_task. - Wichtige Parameter:
item: PydanticWatchlistCreate-Modell mit Elementdetails.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewert:
WatchlistResponse-Objekt für das erstellte Element. - Hinweise: Löst HTTP 400 aus, wenn
target_nameexistiert, HTTP 500 für andere Fehler.
-
update_watchlist_item(item_id: int, item: WatchlistUpdate, db: Session):- Zweck: Aktualisiert ein vorhandenes Watchlist-Element und plant dessen Scraping-Aufgabe neu.
- Funktionalität: Überprüft, ob das Element vorhanden ist und
target_nameeindeutig ist (mit Ausnahme des aktuellen Elements), aktualisiert Felder und ruftschedule_taskauf, um den Scraping-Zeitplan anzupassen. - Wichtige Parameter:
item_id: ID des Watchlist-Elements.item: Pydantic-ModellWatchlistUpdatemit aktualisierten Details.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewerte: Aktualisiertes Objekt
WatchlistResponse. - Hinweise: Löst HTTP 404 aus, wenn das Element nicht gefunden wird, HTTP 400 bei doppeltem
target_nameoder HTTP 500 bei Fehlern.
-
delete_watchlist_item(item_id: int, db: Session):- Zweck: Löscht einen Watchlist-Eintrag und die zugehörigen Scans.
- Funktionalität: Entfernt den Eintrag aus
Watchlist, seine Scans ausWatchlistProfileScanund den entsprechenden APScheduler-Job. - Wichtige Parameter:
item_id: ID des Watchlist-Eintrags.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewerte: JSON-Antwort mit Erfolgsmeldung.
- Hinweise: Gibt HTTP 404 zurück, wenn der Eintrag nicht gefunden wurde, HTTP 500 bei Fehlern. Ignoriert fehlende Scheduler-Jobs.
-
get_profile_scans(watchlist_id: int, db: Session):- Zweck: Ruft alle Scan-Ergebnisse für ein Watchlist-Element ab.
- Funktionalität: Fragt
WatchlistProfileScannach Scans, die mitwatchlist_idübereinstimmen, sortiert nach Zeitstempel (absteigend) und gibt sie alsWatchlistProfileScanResponse-Objekte zurück. - Wichtige Parameter:
watchlist_id: ID des Watchlist-Elements.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewerte: Liste von
WatchlistProfileScanResponse-Objekten. - Hinweise: Löst HTTP 500 für Abfragefehler aus.
-
download_scan(scan_id: int, db: Session):- Zweck: Lädt die Profildaten eines Scans als JSON-Datei herunter.
- Funktionalität: Ruft den Scan anhand der
scan_idab, schreibt seineprofile_datain eine temporäre JSON-Datei und gibt sie alsFileResponsezurück. - Wichtige Parameter:
scan_id: ID des herunterzuladenden Scans.db: SQLAlchemy-Datenbanksitzung.
- Rückgabewert:
FileResponsemit der JSON-Datei. - Hinweise: Löst HTTP 404 aus, wenn der Scan nicht gefunden wird, HTTP 500 bei Fehlern.
-
startup_event():- Zweck: Initialisiert den APScheduler beim Start der Anwendung.
- Funktionalität: Überprüft, ob der Scheduler nicht ausgeführt wird, erstellt eine Datenbanksitzung, ruft
schedule_all_tasksauf, um alle Elemente der Beobachtungsliste zu planen, und startet den Scheduler. - Wichtige Parameter: Keine.
- Rückgabewerte: Keine. Protokolliert den Status des Schedulers.
- Hinweise: Stellt sicher, dass der Scheduler nur einmal gestartet wird, um doppelte Jobs zu vermeiden.
Wenn Sie mit den Standardfrequenzen nicht zufrieden sind, können Sie diese in watchlist.py ändern. Aus Gründen der Konsistenz müssen Sie auch die Vorlagen entsprechend aktualisieren. Wenn Sie jedoch die Frequenzen zu Debugging-Zwecken anpassen, können Sie diese ausschließlich in watchlist.py ändern, ohne die Vorlagen zu ändern.
Vorlage zum Erstellen von Beobachtungslisten
Die Vorlage, die wir verwenden werden, ist eine einfache CRUD-Tabelle, die übersichtlich und funktional ist. Sie können sie unter app/templates/watchlist.html einsehen.
-
Erstellen eines Beobachtungslistenelements:
- Zweck: Fügt ein neues Beobachtungslistenelement zum Überwachen eines Zielprofils hinzu.
- Backend-Interaktion:
- Die Schaltfläche „Neue Bedrohung“ öffnet ein Modal (
newThreatModal) mit Feldern für den Namen des Ziels, den Profil-Link (URL), die Priorität (alles,Beiträge,Kommentare) und die Häufigkeit (alle 24 Stunden,alle 12 Stundenusw.). - Die Formularübermittlung (
newThreatForm) validiert den Profil-Link und sendet eine AJAX-POST-Anfrage mit den Formulardaten an/api/watchlist-api/items(verarbeitet vonwatchlist_api_router). - Das Backend erstellt einen
Watchlist-Datensatz, speichert ihn in der Datenbank und gibt eine erfolgreiche Antwort zurück. Bei Erfolg wird das Modal geschlossen, das Formular zurückgesetzt undloadWatchlist()aktualisiert die Tabelle. Fehler lösen eine Warnmeldung aus.
- Die Schaltfläche „Neue Bedrohung“ öffnet ein Modal (
-
Watchlist-Einträge auflisten und aktualisieren:
- Zweck: Zeigt eine Tabelle mit Watchlist-Einträgen an und aktualisiert sie.
- Backend-Interaktion:
- Die Funktion
loadWatchlist(), die beim Laden der Seite und über die Schaltfläche „Tabelle aktualisieren“ aufgerufen wird, sendet eine AJAX-GET-Anfrage an/api/watchlist-api/items(verarbeitet vonwatchlist_api_router). - Das Backend gibt eine Liste mit „Watchlist“-Datensätzen zurück (ID, Zielname, Profil-Link, Priorität, Häufigkeit, Zeitstempel). Die Tabelle wird mit diesen Details gefüllt und zeigt „Keine Elemente gefunden“ an, wenn sie leer ist. Fehler lösen eine Warnmeldung aus und zeigen eine Fehlermeldung in der Tabelle an.
- Die Funktion
-
Bearbeiten von Elementen der Beobachtungsliste:
- Zweck: Aktualisiert ein vorhandenes Element der Beobachtungsliste.
- Backend-Interaktion:
- Die Schaltfläche „Bearbeiten“ in jeder Tabellenzeile ruft über eine AJAX-GET-Anfrage an
/api/watchlist-api/items/{id}(verarbeitet vonwatchlist_api_router) die Elementdaten ab und füllt daseditThreatModalmit den aktuellen Werten. - Die Formularübermittlung (
editThreatForm) validiert den Profil-Link und sendet eine AJAX-PUT-Anfrage mit den aktualisierten Daten an/api/watchlist-api/items/{id}. - Das Backend aktualisiert den Datensatz
Watchlist. Bei Erfolg wird das Modalfenster geschlossen undloadWatchlist()aktualisiert die Tabelle. Fehler lösen eine Warnmeldung aus.
- Die Schaltfläche „Bearbeiten“ in jeder Tabellenzeile ruft über eine AJAX-GET-Anfrage an
-
Löschen eines Eintrags in der Beobachtungsliste:
- Zweck: Löscht einen Eintrag aus der Beobachtungsliste.
- Backend-Interaktion:
- Die Schaltfläche „Löschen“ in jeder Tabellenzeile fordert zur Bestätigung auf und sendet eine AJAX-DELETE-Anfrage an
/api/watchlist-api/items/{id}(verarbeitet vonwatchlist_api_router). - Das Backend entfernt den Datensatz
Watchlist. Bei Erfolg aktualisiertloadWatchlist()die Tabelle. Fehler lösen eine Warnmeldung aus.
- Die Schaltfläche „Löschen“ in jeder Tabellenzeile fordert zur Bestätigung auf und sendet eine AJAX-DELETE-Anfrage an
-
Anzeigen der Ergebnisse der Beobachtungsliste:
- Zweck: Leitet zu einer Ergebnisseite für das Profil eines Elements der Beobachtungsliste weiter.
- Backend-Interaktion:
- Die Schaltfläche „Ergebnisse anzeigen“ in jeder Tabellenzeile verlinkt zu
/watchlist-profile/{id}(wird vonmain.py::watchlist_profileverarbeitet). - Das Backend rendert eine Vorlage mit den Ergebnissen aus den Überwachungsdaten des
Watchlist-Elements (z. B. Beiträge oder Kommentare). Es wird kein direkter AJAX-Aufruf durchgeführt, aber die Weiterleitung basiert auf dem Abruf von Backend-Daten.
- Die Schaltfläche „Ergebnisse anzeigen“ in jeder Tabellenzeile verlinkt zu
Vorlage für die Anzeige der Ergebnisse der Beobachtungsliste
Wir benötigen eine spezielle Vorlage für die Anzeige der Ergebnisse für jedes Ziel, da wir große Datenmengen verarbeiten, die aus Gründen der Übersichtlichkeit nach Datum sortiert werden müssen.
-
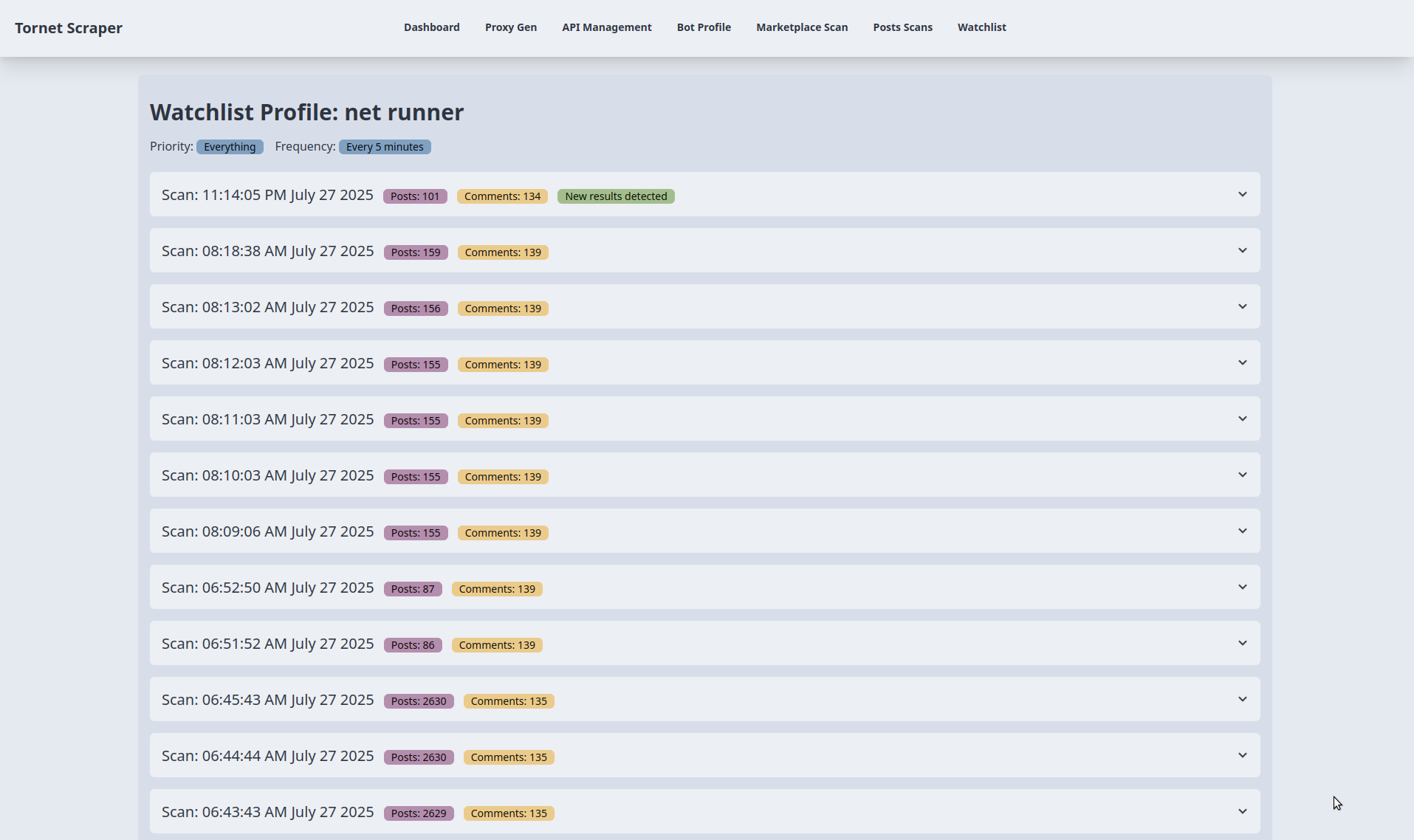
Anzeige der Scan-Ergebnisse:
- Zweck: Zeigt die Scan-Ergebnisse für einen Eintrag in der Beobachtungsliste in Akkordeon-Abschnitten an.
- Backend-Interaktion:
- Die Vorlage empfängt „watchlist_item” (Zielname, Priorität, Häufigkeit) und „scans” (Liste der Scandaten mit „profile_data”, die Beiträge und Kommentare enthält) von „main.py::watchlist_profile”.
- Jedes Akkordeon steht für einen Scan und zeigt den Zeitstempel des Scans, die Anzahl der Beiträge und die Anzahl der Kommentare (aus „profile_data“) an. Ein Badge „Neue Ergebnisse gefunden“ wird angezeigt, wenn sich die Anzahl der Beiträge oder Kommentare des letzten Scans von denen des vorherigen Scans unterscheidet. Die Daten werden ohne zusätzliche API-Aufrufe mit Jinja2 gerendert.
-
Beitrags- und Kommentartabellen:
- Zweck: Zeigt bis zu 15 Beiträge und Kommentare pro Scan in separaten Tabellen an.
- Backend-Interaktion:
- Für jeden Scan werden Beiträge (
profile_data.posts) und Kommentare (profile_data.comments) in Tabellen mit Spalten für Titel, URL und Erstellungsdatum (oder Kommentartext für Kommentare) gerendert. Wenn keine Daten vorhanden sind, wird die Meldung „Keine Beiträge/Kommentare gefunden“ angezeigt. - Die Daten werden über
main.py::watchlist_profileaus dem Backend vorab geladen, sodass für die Darstellung der Tabellen keine weiteren API-Anfragen erforderlich sind.
- Für jeden Scan werden Beiträge (
-
Paginierung für große Datensätze:
- Zweck: Paginierung für Scans mit mehr als 15 Beiträgen oder Kommentaren.
- Backend-Interaktion:
- Für Tabellen mit mehr als 15 Elementen wird eine Paginierungsschaltflächengruppe mit bis zu 5 Seitenschaltflächen gerendert, wobei „data-items“ (JSON-codierte Beiträge/Kommentare) und „data-total-pages“ aus „profile_data.post_count“ oder „comment_count“ verwendet werden.
- Die Funktion
changePage()verwaltet die clientseitige Paginierung und teilt die JSON-Daten so auf, dass 15 Elemente pro Seite ohne zusätzliche Backend-Aufrufe angezeigt werden. Sie aktualisiert die Seiten-Schaltflächen und den Tabelleninhalt dynamisch basierend auf der Navigation des Benutzers (Klicks auf „Zurück/Weiter“ oder die Seitennummer).
-
Herunterladen von Scan-Ergebnissen:
- Zweck: Exportiert Scan-Ergebnisse als Datei.
- Backend-Interaktion:
- Jedes Scan-Akkordeon enthält eine Schaltfläche „Ergebnisse herunterladen“, die zu
/api/watchlist-api/download-scan/{scan.id}führt (verarbeitet vonwatchlist_api_router). - Das Backend generiert eine herunterladbare Datei (z. B. JSON oder CSV) mit den
profile_data(Beiträge und Kommentare) des Scans. Der Link löst einen direkten Download ohne AJAX aus, der auf der Backend-Verarbeitung basiert.
- Jedes Scan-Akkordeon enthält eine Schaltfläche „Ergebnisse herunterladen“, die zu
Ich habe mich für Akkordeons entschieden, um die Scan-Ergebnisse nach Zeitstempeln zu organisieren, da ich dies für den effektivsten Ansatz zur Verwaltung großer Datensätze halte. Auch wenn Sie vielleicht eine andere Methode bevorzugen, bietet das Akkordeon-Format eine übersichtliche und effiziente Darstellung.
Testen
Um mit dem Testen zu beginnen, konfigurieren Sie die folgenden Komponenten:
- Richten Sie eine API für die CAPTCHA-Lösung ein.
- Erstellen Sie ein Bot-Profil mit dem Zweck „scrape_profile“ und melden Sie sich an, um eine Sitzung zu erhalten.
- Erstellen Sie eine Beobachtungsliste über die Seite „/watchlist“.
Um eine Beobachtungsliste zur Überwachung einer Bedrohung zu erstellen, geben Sie Folgendes an:
- Zielname: Eine beliebige Kennung für die Bedrohung.
- Profil-Link: Im Format „http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/profile/N3tRunn3r“.
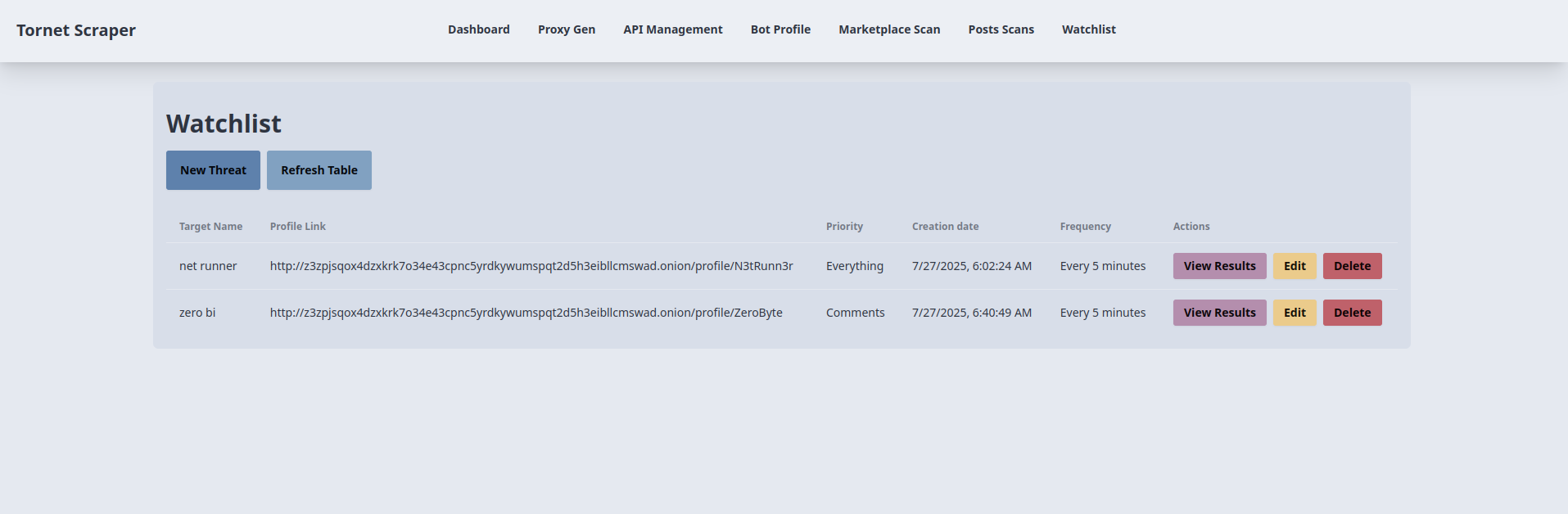
Navigieren Sie zum Menü „Watchlist“, klicken Sie auf „Neue Bedrohung“ und geben Sie die Details ein. Wenn Sie zum ersten Mal ein Ziel hinzufügen, kann es zu einer kurzen Unterbrechung kommen, während der Backend-Dienst einen ersten Scan durchführt. Dieser erste Scan bei der Erstellung eines Ziels ist nicht das Standardverhalten des Task-Schedulers in „watchlist.py“, sondern eine von mir implementierte benutzerdefinierte Funktion.
So werden Ziele angezeigt:
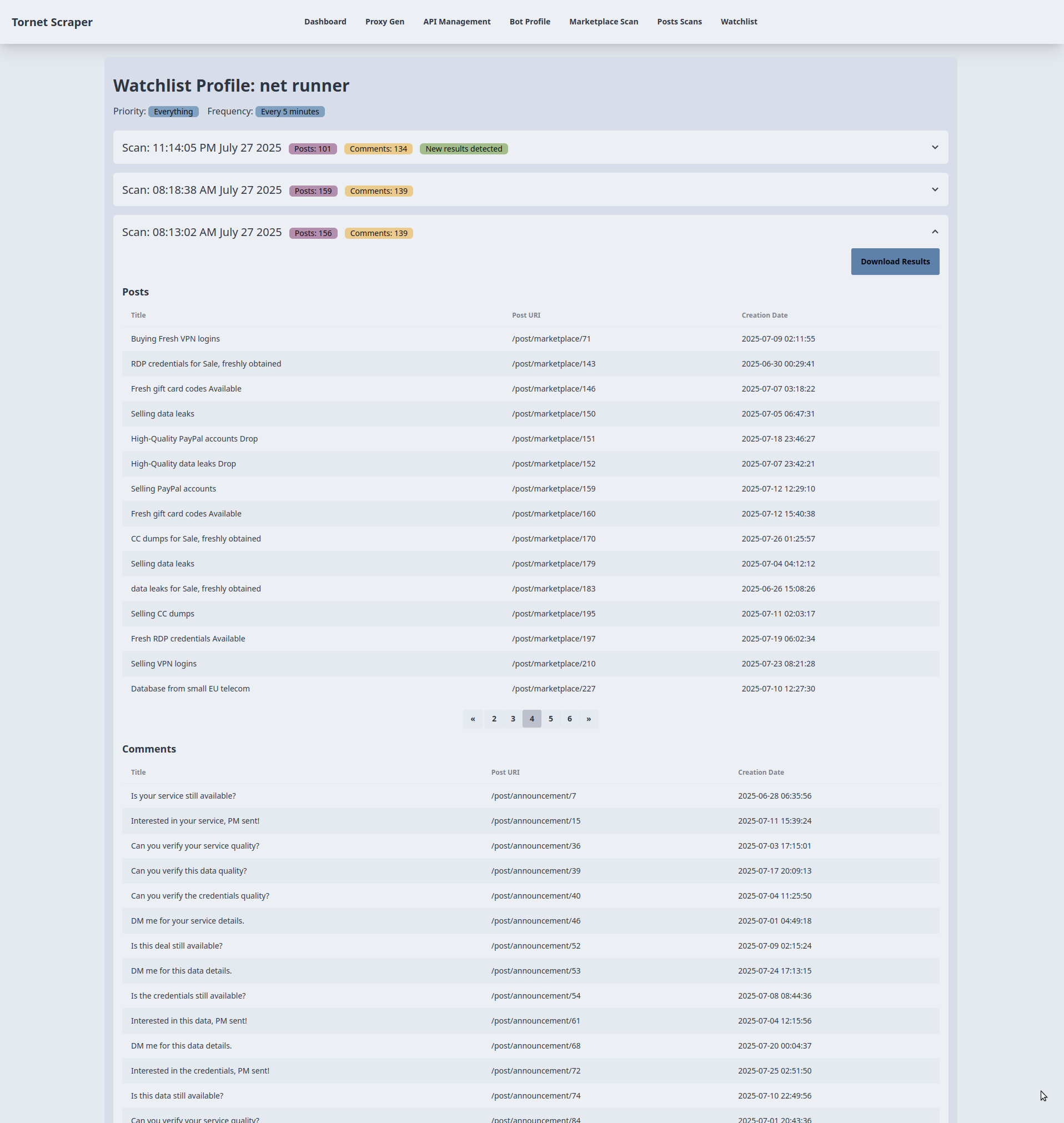
Im Folgenden werden die Ergebnisse der Überwachung angezeigt. Zu Testzwecken habe ich die kritische Planungshäufigkeit von alle 5 Minuten auf alle 1 Minute angepasst:
Sie können jede Akkordeon-Ansicht erweitern, um die Ergebnisse anzuzeigen und als JSON herunterzuladen: