Les mesures anti-bot sont très répandues. Elles apparaissent sur les principaux sites web et même sur certaines plateformes de cybercriminalité afin d'empêcher le spam ou les abus. L'un des systèmes anti-bot les plus avancés est Netacea, bien qu'il soit moins couramment utilisé sur les sites de cybercriminalité d'après mes observations. Pour les sites web plus sophistiqués, vous devrez peut-être contrôler par programmation un navigateur web de bureau plutôt qu'un navigateur sans interface graphique comme Playwright. Une approche à explorer est Hidden VNC pour l'automatisation des navigateurs, qui vous permet de simuler les interactions de la souris et du clavier.
Comme les sites web ne peuvent pas accéder directement à votre système, ils peuvent toujours détecter les navigateurs sans interface graphique ou les extensions de navigateur. Cependant, l'automatisation des interactions via votre système d'exploitation peut souvent passer inaperçue, car elle imite plus efficacement le comportement réel des utilisateurs. Bien que cette technique dépasse le cadre de ce cours, c'est une option que vous pouvez explorer de manière indépendante. La plupart des sites de cybercriminalité mettent en œuvre une limitation du débit basée sur les adresses IP et les CAPTCHA pour bloquer les bots.
Les sujets abordés dans cette section sont les suivants :
- Limitation du débit
- Interdiction d'adresses IP
- Contournement des CAPTCHA
- Verrouillage de compte
Limitation du débit
La plupart des sites Web ont activé la limitation du débit pour certains points de terminaison. L'objectif de la limitation du débit est d'empêcher l'envoi d'un nombre excessif de requêtes à une page Web. Du point de vue d'un développeur, voici comment la limitation du débit est configurée pour un itinéraire :
limiter = Limiter(
get_remote_address,
app=app,
default_limits=["500 per day", "200 per hour"],
storage_uri="memory://"
)
@app.route('/post/<post_type>/<int:post_id>')
@limiter.limit("30 per minute")
@login_required
def post_detail(post_type, post_id):
À titre de référence, j'exécute « tornet_forum » localement sans Tor.
La limite par défaut est de 500 requêtes par jour à partir d'une même adresse IP vers toutes les autres routes et de 200 requêtes par heure. Mais pour « /api/post », la limite est de 30 requêtes par minute. Après 30 requêtes, vous ne pourrez donc plus envoyer de requêtes supplémentaires. Cette route est utilisée pour afficher les détails d'une publication. Voici à quoi ressemble l'URL :
http://127.0.0.1:5000/post/announcements/272
Voici un exemple en Python qui montre ce qui se passe lorsque la limite est dépassée :
import requests
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
for reqnum in range(31):
response = requests.get(url, cookies=cookies)
print(f"Request number: {reqnum} | HTTP Status code: {response.status_code}")
Sortie :
-> % python3 rate_limit_test.py
Request number: 0 | HTTP Status code: 200
Request number: 1 | HTTP Status code: 200
Request number: 2 | HTTP Status code: 200
Request number: 3 | HTTP Status code: 200
Request number: 4 | HTTP Status code: 200
Request number: 5 | HTTP Status code: 200
Request number: 6 | HTTP Status code: 200
Request number: 7 | HTTP Status code: 200
Request number: 8 | HTTP Status code: 200
Request number: 9 | HTTP Status code: 200
Request number: 10 | HTTP Status code: 200
Request number: 11 | HTTP Status code: 200
Request number: 12 | HTTP Status code: 200
Request number: 13 | HTTP Status code: 200
Request number: 14 | HTTP Status code: 200
Request number: 15 | HTTP Status code: 200
Request number: 16 | HTTP Status code: 200
Request number: 17 | HTTP Status code: 200
Request number: 18 | HTTP Status code: 200
Request number: 19 | HTTP Status code: 200
Request number: 20 | HTTP Status code: 200
Request number: 21 | HTTP Status code: 200
Request number: 22 | HTTP Status code: 200
Request number: 23 | HTTP Status code: 200
Request number: 24 | HTTP Status code: 200
Request number: 25 | HTTP Status code: 200
Request number: 26 | HTTP Status code: 200
Request number: 27 | HTTP Status code: 200
Request number: 28 | HTTP Status code: 200
Request number: 29 | HTTP Status code: 200
Request number: 30 | HTTP Status code: 429
Dans des scénarios réels, vous ne pouvez généralement pas accéder au code source d'une application. Il faut donc déterminer par essais et erreurs la limite de débit, par exemple le nombre de requêtes autorisées par minute ou par 10 minutes. Bien que des scripts puissent automatiser ce processus, celui-ci reste fastidieux.
Maintenant que nous savons que la limite de débit est déclenchée après 30 requêtes, nous pouvons envoyer 29 requêtes, faire une pause de 60 secondes, envoyer 29 autres requêtes et répéter ce cycle :
import requests
import time
REQUEST_COUNT = 29
SLEEP_DURATION = 60
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
batch_num = 1
while True:
print(f"Starting batch {batch_num}")
for reqnum in range(REQUEST_COUNT):
response = requests.get(url, cookies=cookies)
print(f"Batch {batch_num} | Request number: {reqnum + 1} | HTTP Status code: {response.status_code}")
print(f"Batch {batch_num} completed. Sleeping for {SLEEP_DURATION} seconds...")
time.sleep(SLEEP_DURATION)
batch_num += 1
Output:
-> % python3 rate_limit_test.py
Starting batch 1
Batch 1 | Request number: 1 | HTTP Status code: 200
Batch 1 | Request number: 2 | HTTP Status code: 200
Batch 1 | Request number: 3 | HTTP Status code: 200
Batch 1 | Request number: 4 | HTTP Status code: 200
Batch 1 | Request number: 5 | HTTP Status code: 200
Batch 1 | Request number: 6 | HTTP Status code: 200
Batch 1 | Request number: 7 | HTTP Status code: 200
Batch 1 | Request number: 8 | HTTP Status code: 200
Batch 1 | Request number: 9 | HTTP Status code: 200
Batch 1 | Request number: 10 | HTTP Status code: 200
Batch 1 | Request number: 11 | HTTP Status code: 200
Batch 1 | Request number: 12 | HTTP Status code: 200
Batch 1 | Request number: 13 | HTTP Status code: 200
Batch 1 | Request number: 14 | HTTP Status code: 200
Batch 1 | Request number: 15 | HTTP Status code: 200
Batch 1 | Request number: 16 | HTTP Status code: 200
Batch 1 | Request number: 17 | HTTP Status code: 200
Batch 1 | Request number: 18 | HTTP Status code: 200
Batch 1 | Request number: 19 | HTTP Status code: 200
Batch 1 | Request number: 20 | HTTP Status code: 200
Batch 1 | Request number: 21 | HTTP Status code: 200
Batch 1 | Request number: 22 | HTTP Status code: 200
Batch 1 | Request number: 23 | HTTP Status code: 200
Batch 1 | Request number: 24 | HTTP Status code: 200
Batch 1 | Request number: 25 | HTTP Status code: 200
Batch 1 | Request number: 26 | HTTP Status code: 200
Batch 1 | Request number: 27 | HTTP Status code: 200
Batch 1 | Request number: 28 | HTTP Status code: 200
Batch 1 | Request number: 29 | HTTP Status code: 200
Batch 1 completed. Sleeping for 60 seconds...
Starting batch 2
Batch 2 | Request number: 1 | HTTP Status code: 200
Batch 2 | Request number: 2 | HTTP Status code: 200
Batch 2 | Request number: 3 | HTTP Status code: 200
Batch 2 | Request number: 4 | HTTP Status code: 200
Batch 2 | Request number: 5 | HTTP Status code: 200
Batch 2 | Request number: 6 | HTTP Status code: 200
Batch 2 | Request number: 7 | HTTP Status code: 200
Batch 2 | Request number: 8 | HTTP Status code: 200
Batch 2 | Request number: 9 | HTTP Status code: 200
Batch 2 | Request number: 10 | HTTP Status code: 200
Batch 2 | Request number: 11 | HTTP Status code: 200
Batch 2 | Request number: 12 | HTTP Status code: 200
Batch 2 | Request number: 13 | HTTP Status code: 200
Batch 2 | Request number: 14 | HTTP Status code: 200
Batch 2 | Request number: 15 | HTTP Status code: 200
Batch 2 | Request number: 16 | HTTP Status code: 200
Batch 2 | Request number: 17 | HTTP Status code: 200
Batch 2 | Request number: 18 | HTTP Status code: 200
Batch 2 | Request number: 19 | HTTP Status code: 200
Batch 2 | Request number: 20 | HTTP Status code: 200
Batch 2 | Request number: 21 | HTTP Status code: 200
Batch 2 | Request number: 22 | HTTP Status code: 200
Batch 2 | Request number: 23 | HTTP Status code: 200
Batch 2 | Request number: 24 | HTTP Status code: 200
Batch 2 | Request number: 25 | HTTP Status code: 200
Batch 2 | Request number: 26 | HTTP Status code: 200
Batch 2 | Request number: 27 | HTTP Status code: 200
Batch 2 | Request number: 28 | HTTP Status code: 200
Batch 2 | Request number: 29 | HTTP Status code: 200
Batch 2 completed. Sleeping for 60 seconds...
N'oubliez pas qu'ici, nous envoyons uniquement des requêtes à une seule URL, mais dans la réalité, vous devrez énumérer des centaines de publications, même si le processus reste le même.
Interdictions d'adresses IP
Les interdictions d'adresses IP étaient autrefois courantes, mais elles sont aujourd'hui moins répandues et se limitent principalement à certains systèmes de gestion de contenu. Je ne les ai jamais rencontrées sur des sites cybercriminels, mais ce cours vous apprendra à les contourner afin de vous préparer à toute éventualité.
Pour les sites web classiques, une adresse IP interdite peut être contournée à l'aide d'un VPN ou d'un proxy. Cependant, le web scraping à grande échelle nécessite de faire tourner des centaines de proxys, tels que des proxys résidentiels ou des proxys de centres de données.
Mon site préféré pour acheter des proxys est : https://decodo.com
Il s'agit d'une plateforme réputée que j'utilise pour la recherche de bogues et qui offre un service client réactif. Au 11 juillet 2025, le coût pour 100 proxys est de 3,80 $ :
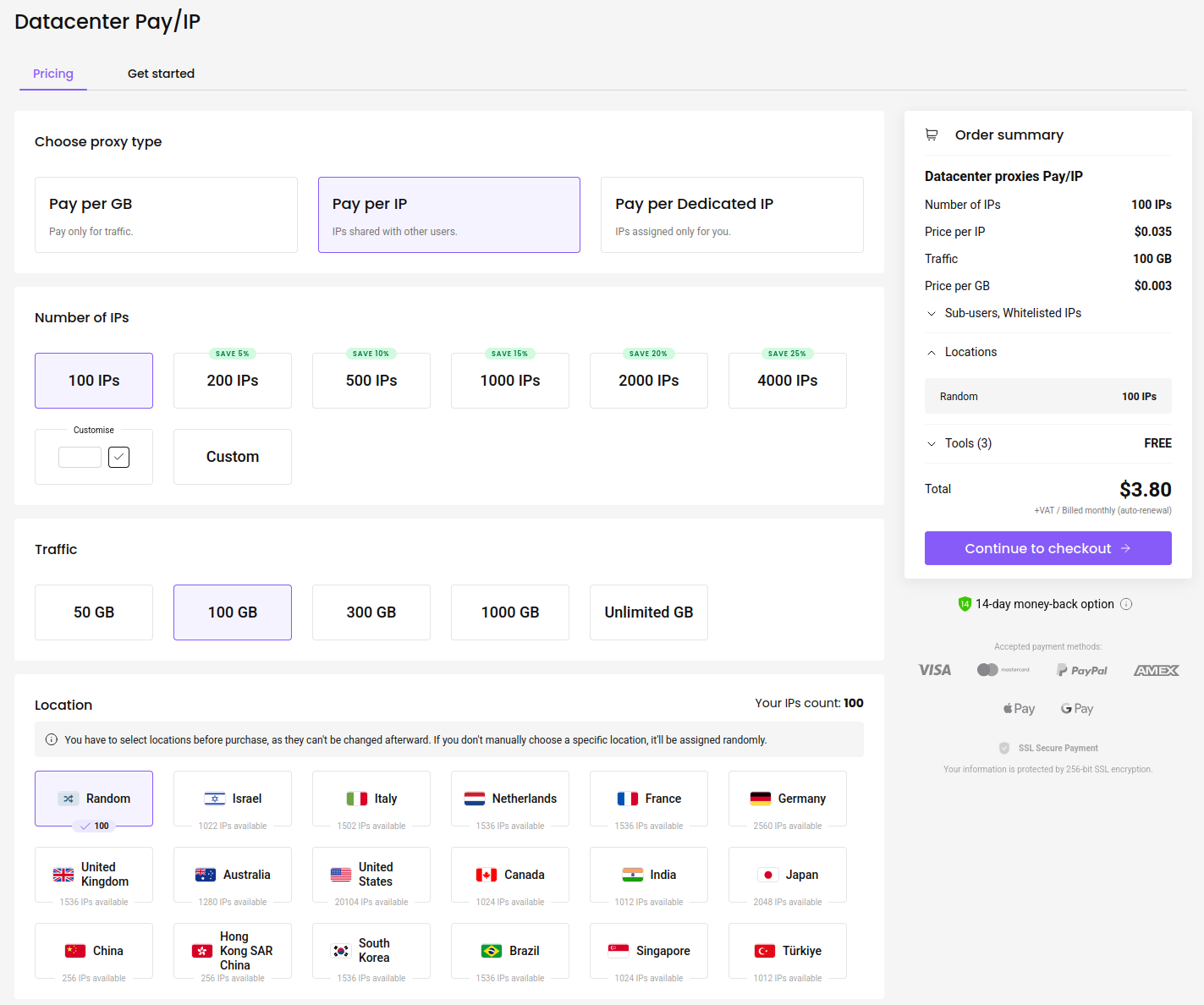
C'est assez bon marché. Une fois que vous avez acheté vos proxys, voici comment vous pouvez les utiliser :
import requests
REQUEST_COUNT = 29
PROXY_CHANGE_INTERVAL = 5
proxies_list = [
"http://sp96rgc8yz:[email protected]:10001",
"http://sp96rgc8yz:[email protected]:10002",
"http://sp96rgc8yz:[email protected]:10003",
"http://sp96rgc8yz:[email protected]:10004",
"http://sp96rgc8yz:[email protected]:10005",
"http://sp96rgc8yz:[email protected]:10006"
]
url = "http://127.0.0.1:5000/post/announcements/272"
cookies = {
"session": ".eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHE7pQ.HyexRW6P3g7njbSz53vZj77gmMU"
}
proxy_index = 0
request_count = 0
while True:
current_proxy = proxies_list[proxy_index % len(proxies_list)]
proxies = {
"http": current_proxy,
"https": current_proxy
}
response = requests.get(url, cookies=cookies, proxies=proxies)
print(f"Request number: {request_count + 1} | Proxy: {current_proxy} | HTTP Status code: {response.status_code}")
request_count += 1
# Change proxy every 5 requests
if request_count % PROXY_CHANGE_INTERVAL == 0:
proxy_index += 1
Le programme fonctionne dans une boucle infinie « while True », sélectionnant un proxy dans la liste à l'aide d'une opération modulo (« proxy_index % len(proxies_list) ») pour revenir au premier proxy après le dernier. Il applique le proxy sélectionné aux protocoles HTTP et HTTPS. Après chaque série de cinq requêtes, il incrémente « proxy_index » pour passer au proxy suivant, en recommençant depuis le premier proxy lorsque la fin de « proxies_list » est atteinte.
Contournement des CAPTCHA
Les CAPTCHA sont sans doute le sujet le plus intéressant de ce module et probablement la raison pour laquelle beaucoup d'entre vous sont ici. Tout comme nous avons analysé les pages web avant de les scraper, nous pouvons étudier le fonctionnement des CAPTCHA avant de les contourner.
Pour comprendre les CAPTCHA, rendez-vous sur la page de connexion où ils apparaissent généralement :
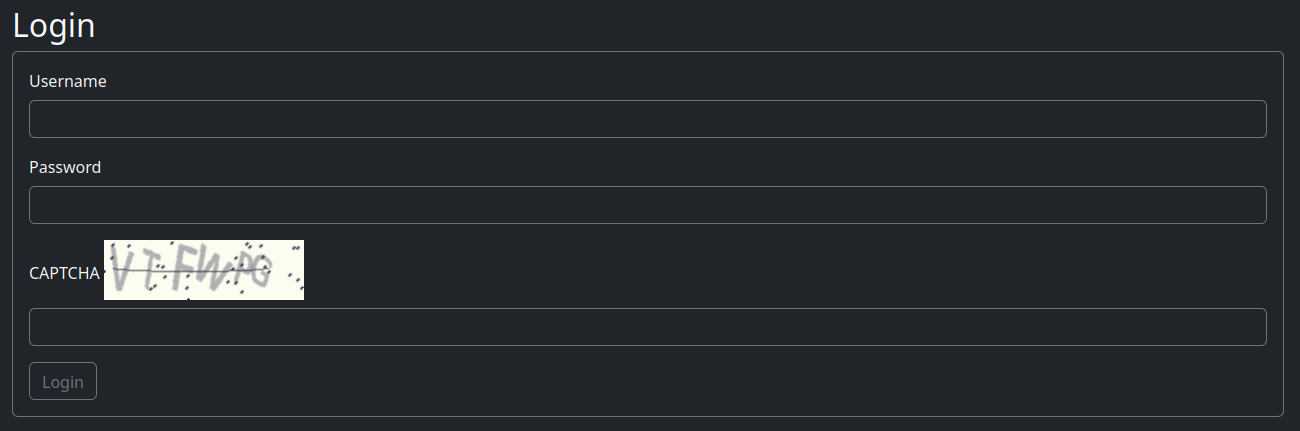
Rechargez la page plusieurs fois pour observer :
-
Combien de caractères chaque CAPTCHA utilise-t-il ? 6 caractères
-
Quels types de caractères sont utilisés (minuscules, majuscules, mixtes, chiffres) ? Toutes les lettres majuscules et les chiffres
-
Quelle est la taille de l'image CAPTCHA ? Téléchargez-la, ouvrez-la dans Chrome et notez qu'elle mesure 200 pixels de large sur 60 pixels de haut
-
Quelle est la résolution maximale lorsque vous redimensionnez l'image CAPTCHA ? Le redimensionnement améliore la lisibilité des caractères
Voici une version redimensionnée du CAPTCHA de connexion :

N'est-ce pas plus clair et plus facile à lire ? Voici comment je demande à ChatGPT o3 d'extraire le texte avec précision :
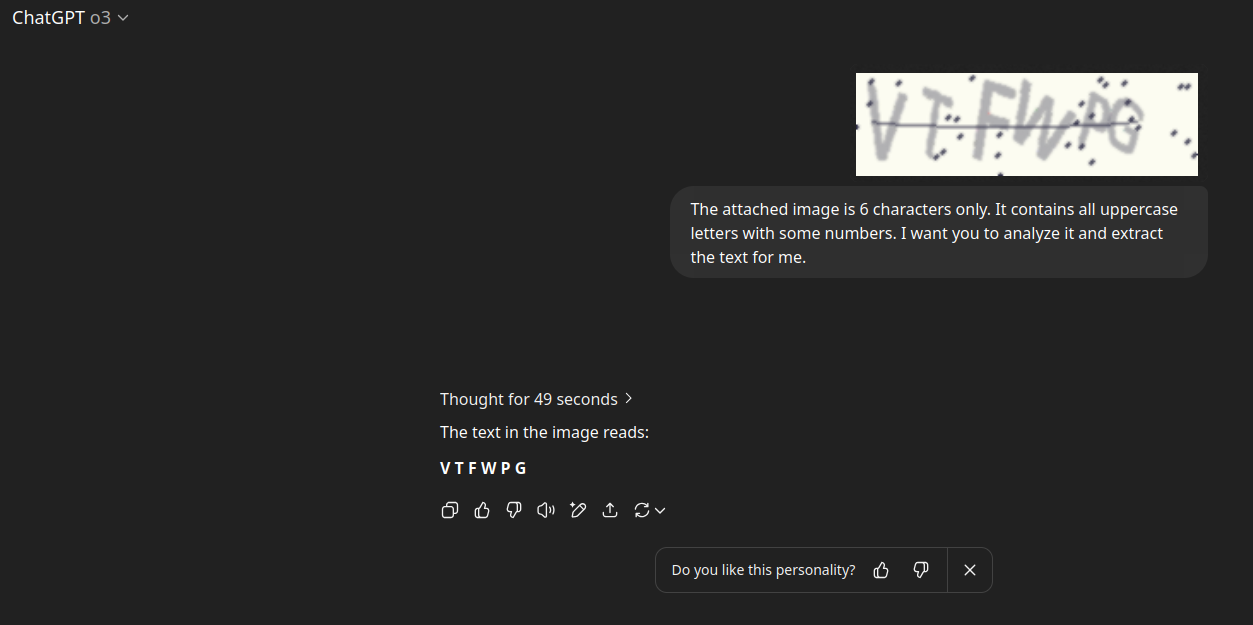
Ce processus peut prendre du temps, parfois 49 secondes ou jusqu'à une minute, mais l'OCR de ChatGPT o3 est complet, bien que parfois incohérent. Vous pouvez éventuellement analyser le CAPTCHA plusieurs fois et sélectionner le résultat avec le score de confiance le plus élevé.
Heureusement, les CAPTCHA ne sont généralement utilisés que sur les pages de connexion et d'inscription de la plupart des forums, il n'est donc pas toujours nécessaire de les contourner de manière extensive. Sur notre site principal de scraping web, lorsqu'un compte bot est ajouté, nous nous connectons automatiquement, contournons le CAPTCHA et créons une session. Si la session expire, nous effectuons une nouvelle connexion à l'aide des identifiants. Si la connexion échoue en raison d'un CAPTCHA incorrect, nous réessayons jusqu'à ce que cela fonctionne.
Une limitation de l'utilisation de o3 est que son modèle API OpenAI ne prend pas en charge le traitement d'images. Nous explorerons des modèles prenant en charge les images et l'accès à l'API dans les sections suivantes.
Dans les sections suivantes, vous apprendrez comment nous utilisons le modèle gpt-4.1 pour effectuer des tentatives de connexion continues, qui aboutissent généralement après cinq essais consécutifs, comme vous le découvrirez plus tard.
Verrouillage de compte
Les verrouillages ou interdictions de compte sont généralement manuels, mais peuvent parfois être automatisés. De nombreux forums consacrés à la cybercriminalité luttent contre les escrocs en mettant sur liste noire certains identifiants d'utilisateurs. Par exemple, publier un nom d'utilisateur Telegram tel que « @BluePig » peut déclencher une interdiction automatique.
J'ai souvent observé ce phénomène, donc le fait de passer d'un compte à l'autre ne résout pas toujours le problème. Cependant, si vous rencontrez des verrouillages automatiques, la rotation des comptes est une stratégie viable.
Certains sites utilisent des systèmes de connexion automatisés qui alertent les administrateurs en cas d'activités suspectes, telles que des requêtes excessives ou des comportements potentiellement malveillants.
Dans notre scraper web principal, nous allons mettre en place une rotation des comptes à l'aide de plusieurs comptes de bots afin d'éviter les verrouillages. Bien que les sites de test de ce cours ne disposent pas de mécanismes de verrouillage des comptes, nous allons vous apprendre à contourner ces protections afin de vous préparer à des scénarios réels.
Le code Python suivant montre comment passer d'un compte à l'autre et imprimer la page de profil de chaque compte afin de démontrer le principe de la rotation des comptes.
Lorsque vous êtes connecté en tant que « DarkHacker », la page de profil affiche « Vous êtes connecté en tant que DarkHacker ». Ce message n'apparaît pas lorsque vous consultez les pages de profil d'autres utilisateurs, ce qui confirme votre statut de connexion. Voici comment nous vérifions cela de manière programmatique en passant d'un compte à l'autre :
import requests
# JSON structure for profiles
profiles = {
"url": "http://127.0.0.1:5000/profile/",
"users": {
"CyberGhost": {
"cookie": "session=.eJwtzrkRwjAQAMBeFBNIJ-keN-PRfWNSG0cMvUPAVrDvsucZ11G213nHo-xPL1uBabksGWtPVu-1CgCBKzZhnzEU3ZQRuSG2aYvSCCVpVfAqg5S7-gAMmTJGl-k5slVzRgBvJKa0IJPDa8zRsmnajFTI3knKL3Jfcf435fMFvlsvkA.aHFScA.HYZ0jgZ5eb06WP5SzPnnf6pISJo"
},
"DarkHacker": {
"cookie": "session=.eJwlzjkOwjAQAMC_uKbwru098hmUvQRtQirE30FiXjDvdq8jz0fbXseVt3Z_RtsaLq_dS6iPEovRuyIyhhGoxMppFG5CJEAEy3cuZ9LivWN0nWwyLCZS6tI5h66oWdA9hBADWN14xyrJ6LkmFFj5yjKsMVjbL3Kdefw30D5fvlgvjw.aHFR-A.mcu8L_CTLdZrz2254OEzZhsqpbQ"
}
}
}
# Function to fetch profile and check for login string
def fetch_profile(username, cookie):
url = f"{profiles['url']}{username}"
headers = {'Cookie': cookie}
try:
response = requests.get(url, headers=headers)
# Check for the login confirmation string
login_string = f"You are logged in as {username}"
if login_string in response.text:
print(f"Confirmation: '{login_string}' found in the response for user: {username}.")
else:
print(f"Confirmation: '{login_string}' NOT found in the response.")
except requests.RequestException as e:
print(f"Error fetching profile for {username}: {e}")
# Fetch profiles for both users
for username, data in profiles['users'].items():
fetch_profile(username, data['cookie'])
Sortie :
-> % python3 profile_rotation.py
Confirmation: 'You are logged in as CyberGhost' found in the response for user: CyberGhost.
Confirmation: 'You are logged in as DarkHacker' found in the response for user: DarkHacker.
Vous pouvez améliorer l'expérience d'apprentissage en énumérant les publications avec chaque compte, mais l'approche actuelle est suffisante. Passer d'un compte à l'autre est une stratégie efficace pour éviter d'être signalé pour activité suspecte, car toutes les requêtes envoyées au site web sont enregistrées.