Dans cette section, nous allons apprendre à extraire les publications du marché des vendeurs et à répartir les tâches d'extraction entre plusieurs bots afin qu'elles s'exécutent simultanément.
L'objectif est de répartir les tâches entre les bots, car la plupart des forums imposent des limites sur le nombre de requêtes que vous pouvez envoyer. Dans tornet_forum, il n'y a pas de limite pour naviguer dans les pages, et vous pouvez passer d'une page à l'autre sans être connecté.
Cependant, afin de nous préparer à divers mécanismes de protection, nous utiliserons des bots avec des sessions actives pour le scraping. Bien que cela ne soit pas nécessaire pour tornet_forum, des sessions connectées peuvent être nécessaires pour d'autres sites cibles que vous rencontrerez. Ayant moi-même scrapé des données sur de tels sites, je comprends les défis auxquels vous pourriez être confronté, et cette approche vous permettra d'être prêt à faire face à n'importe quel scénario.
Les sujets abordés dans cette section sont les suivants :
- Modèles de base de données
- Modules de scraping de marketplace
- Routes backend de marketplace
- Modèle frontend de marketplace
- Tests
Modèles de base de données
Vos modèles se trouvent dans app/database/models.py. Vous avez besoin de 4 modèles pour organiser correctement les données :
class MarketplacePaginationScan(Base):
__tablename__ = "marketplace_pagination_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False)
pagination_url = Column(String, nullable=False)
max_page = Column(Integer, nullable=False)
batches = Column(Text, nullable=True)
timestamp = Column(DateTime, default=datetime.utcnow)
class ScanStatus(enum.Enum):
RUNNING = "running"
COMPLETED = "completed"
STOPPED = "stopped"
class MarketplacePostScan(Base):
__tablename__ = "marketplace_post_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False, unique=True)
pagination_scan_name = Column(String, ForeignKey("marketplace_pagination_scans.scan_name"), nullable=False)
start_date = Column(DateTime(timezone=True), default=datetime.utcnow)
completion_date = Column(DateTime(timezone=True), nullable=True)
status = Column(Enum(ScanStatus), default=ScanStatus.STOPPED, nullable=False)
timestamp = Column(DateTime, default=datetime.utcnow)
class MarketplacePost(Base):
__tablename__ = "marketplace_posts"
id = Column(Integer, primary_key=True, index=True)
scan_id = Column(Integer, ForeignKey("marketplace_post_scans.id"), nullable=False)
timestamp = Column(String, nullable=False)
title = Column(String, nullable=False)
author = Column(String, nullable=False)
link = Column(String, nullable=False)
__table_args__ = (UniqueConstraint('scan_id', 'timestamp', name='uix_scan_timestamp'),)
Pour cette fonctionnalité, nous avons besoin de plusieurs modèles pour effectuer toutes les tâches suivantes :
-
MarketplacePaginationScan:- Objectif : représente une configuration de scan de pagination pour le scraping d'une place de marché. Il stocke les détails d'un scan qui énumère les pages d'une place de marché, telles que l'URL de base et le nombre maximal de pages à scanner.
- Champs clés :
id: identifiant unique du scan.scan_name: nom unique du scan de pagination.pagination_url: URL de base utilisée pour la pagination.max_page: nombre maximal de pages à scanner.batches: stocke les données de lots sérialisées (par exemple, JSON) pour le traitement des pages.timestamp: enregistre la date de création de l'analyse.
-
ScanStatus (Enum):- Objectif : définit les états possibles d'une analyse postérieure, utilisés pour suivre le statut d'un
MarketplacePostScan. - Valeurs :
RUNNING: l'analyse est en cours.COMPLETED: le scan s'est terminé avec succès.STOPPED: le scan n'est pas en cours d'exécution (par défaut ou arrêté manuellement).
- Objectif : définit les états possibles d'une analyse postérieure, utilisés pour suivre le statut d'un
-
MarketplacePostScan:- Objectif : représente un scan qui collecte des publications à partir d'une place de marché, lié à un scan de pagination spécifique. Il suit les métadonnées et le statut du scan.
- Champs clés :
id: identifiant unique de l'analyse de publication.scan_name: nom unique de l'analyse de publication.pagination_scan_name: référence l'élémentMarketplacePaginationScanassocié par sonscan_name.start_date: date de début de l'analyse.completion_date: date de fin de l'analyse (le cas échéant).status: état actuel du scan (à partir de l'énumérationScanStatus).timestamp: enregistre la date de création du scan.
-
MarketplacePost:- Objectif : stocke les publications individuelles collectées lors d'un
MarketplacePostScan. Chaque publication est liée à un scan spécifique et comprend des détails sur la publication. - Champs clés :
id: identifiant unique de la publication.scan_id: référence leMarketplacePostScanauquel appartient cette publication.timestamp: horodatage de la publication (sous forme de chaîne).title: titre de la publication sur la place de marché.author: auteur de la publication.link: URL de la publication.__table_args__: garantit l'unicité des publications en fonction descan_idettimestampafin d'éviter les doublons.
- Objectif : stocke les publications individuelles collectées lors d'un
Modules de scraper de marketplace
Pour voir un exemple du fonctionnement du scraper de marketplace, ouvrez app/scrapers/marketplace_scraper.py.
import json
import requests
from bs4 import BeautifulSoup
import logging
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def create_pagination_batches(url_template, max_page):
"""
Given a web URL with max pagination number, this function returns batches of 10 pagination ranges.
"""
if max_page < 1:
return json.dumps({})
all_urls = [url_template.format(page=page) for page in range(max_page, 0, -1)]
batch_size = 10
batches = {f"{i//batch_size + 1}": all_urls[i:i + batch_size] for i in range(0, len(all_urls), batch_size)}
return json.dumps(batches)
def scrape_posts(session, proxy, useragent, pagination_range, timeout=30):
"""
Given a list of web pages, it scraps all post details from every pagination page.
"""
posts = {}
headers = {'User-Agent': useragent}
proxies = {'http': proxy, 'https': proxy} if proxy else None
for url in pagination_range:
logger.info(f"Scraping URL: {url}")
try:
response = session.get(url, headers=headers, proxies=proxies, timeout=timeout)
logger.info(f"Response status code: {response.status_code}")
response.raise_for_status()
# Log response size and snippet
logger.debug(f"Response size: {len(response.text)} bytes")
logger.debug(f"Response snippet: {response.text[:200]}...")
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.select_one('table.table-dark tbody')
if not table:
logger.error(f"No table found on {url}")
continue
table_rows = table.select('tr')
logger.info(f"Found {len(table_rows)} table rows on {url}")
for row in table_rows[:10]:
try:
title = row.select_one('td:nth-child(1)').text.strip()
author = row.select_one('td:nth-child(2) a').text.strip()
timestamp = row.select_one('td:nth-child(3)').text.strip()
link = row.select_one('td:nth-child(5) a')['href']
logger.info(f"Extracted post: timestamp={timestamp}, title={title}, author={author}, link={link}")
posts[timestamp] = {
'title': title,
'author': author,
'link': link
}
except AttributeError as e:
logger.error(f"Error parsing row on {url}: {e}")
continue
except requests.RequestException as e:
logger.error(f"Error scraping {url}: {e}")
continue
logger.info(f"Total posts scraped: {len(posts)}")
return json.dumps(posts)
if __name__ == "__main__":
# Create a proper requests.Session and set the cookie
session = requests.Session()
session.cookies.set('session', '.eJwlzsENwzAIAMBd_O4DbINNlokAg9Jv0ryq7t5KvQnuXfY84zrK9jrveJT9ucpWbA0xIs5aZ8VM5EnhwqNNbblWVlmzMUEH9MkDmwZQTwkFDlqhkgounTm9Q7U0nYQsw6MlmtKYqBgUpAMkuJpnuEMsYxtQfpH7ivO_wfL5AtYwMDs.aH1ifQ.uRrB1FnMt3U_apyiWitI9LDnrGE')
proxy = "socks5h://127.0.0.1:49075"
useragent = "Mozilla/5.0 (Windows NT 11.0; Win64; x64; rv:140.0) Gecko/20100101 Firefox/140.0"
pagination_range = [
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=1",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=2",
"http://y5extjdmtegzt6n6qe3titrmgjvff4hiualgzy7n2jrahbmfkggbmqqd.onion/category/marketplace/Sellers?page=3"
]
timeout = 30
result = scrape_posts(session, proxy, useragent, pagination_range, timeout)
print(result)
Nous avons besoin de deux fonctions distinctes pour effectuer ces tâches :
- create_pagination_batches(url_template, max_page)
- Génère des lots d'URL pour la pagination en créant des groupes de 10 URL de page à partir d'un modèle d'URL donné et d'un nombre maximal de pages, puis les renvoie sous forme de chaîne JSON.
- scrape_posts(session, proxy, useragent, pagination_range, timeout)
- Récupère les détails des publications (titre, auteur, horodatage, lien) à partir d'une liste d'URL de pages web à l'aide d'une session de requêtes, d'un proxy et d'un agent utilisateur, en analysant le HTML avec
BeautifulSoup, et renvoie les données collectées sous forme de chaîne JSON.
- Récupère les détails des publications (titre, auteur, horodatage, lien) à partir d'une liste d'URL de pages web à l'aide d'une session de requêtes, d'un proxy et d'un agent utilisateur, en analysant le HTML avec
Nous limitons les lots de pagination à 10 pages, car il s'agit du seuil que nous avons fixé. Vous pouvez ajuster cette limite, mais si vos bots accèdent à 50 pages de pagination en quelques secondes, cela pourrait déclencher le verrouillage de votre compte.
Plus tard, nous utiliserons la fonction scrape_posts pour traiter des plages de lots de pagination, ce qui permettra de scraper les publications de tous les lots.
Création du backend du marché
Le backend peut sembler plus intimidant que nos tâches précédentes. Vous trouverez le code du backend dans app/routes/marketplace.py.
Cette complexité provient de la concurrence, qui nous permet de répartir les tâches de scraping des données entre tous les bots disponibles, ce qui augmente l'efficacité mais ajoute de la complexité. Notez que toutes les analyses s'exécutent en arrière-plan, elles se poursuivent donc même si vous naviguez entre les pages.
Bien que les fonctionnalités puissent sembler complexes, cela fait naturellement partie du processus d'apprentissage. Notre objectif est de créer un scraper web avancé pour la collecte de données à long terme, une tâche intrinsèquement sophistiquée.
get_pagination_scans
- Point de terminaison :
GET /api/marketplace-scan/list - Objectif : récupère tous les scans de pagination de la base de données.
- Fonctionnalité :
- Interroge la table
MarketplacePaginationScanpour récupérer tous les enregistrements. - Enregistre le nombre de scans récupérés.
- Formate chaque scan dans un dictionnaire compatible JSON contenant
id,scan_name,pagination_url,max_page,batchesettimestamp. - Renvoie une
JSONResponseavec la liste des scans et un code d'état 200. - Gère les exceptions en enregistrant les erreurs et en levant une
HTTPExceptionavec un code d'état 500 si une erreur se produit.
- Interroge la table
enumerate_pages
- Point de terminaison :
POST /api/marketplace-scan/enumerate - Objectif : crée un nouveau scan de pagination pour énumérer les pages à extraire.
- Fonctionnalité :
- Vérifie que le
scan_namefourni n'existe pas déjà dans la base de données. - Appelle
create_pagination_batchespour générer des lots d'URL en fonction des paramètrespagination_urletmax_pagefournis. - Crée un nouvel enregistrement
MarketplacePaginationScanavec les détails du scan et stocke les lots au format JSON. - Enregistre l'enregistrement dans la base de données et consigne la création.
- Stocke un message de réussite dans la session et renvoie une
JSONResponseavec un code d'état 201. - Gère les noms de scan en double (400), les erreurs de base de données (500, avec retour en arrière) et autres exceptions en enregistrant et en levant les
HTTPExceptionappropriées.
- Vérifie que le
delete_pagination_scan
- Point de terminaison :
DELETE /api/marketplace-scan/{scan_id} - Objectif : supprime un scan de pagination en fonction de son ID.
- Fonctionnalité :
- Interroge la table
MarketplacePaginationScanpour le scan avec lescan_idspécifié. - Si le scan n'est pas trouvé, enregistre un avertissement et lève une exception
HTTPException404. - Supprime le scan de la base de données et valide la transaction.
- Enregistre la suppression et stocke un message de réussite dans la session.
- Renvoie une réponse
JSONResponseavec un code d'état 200. - Gère les erreurs en les enregistrant, en annulant la transaction et en levant une exception
HTTPException500.
- Interroge la table
get_post_scans
- Point de terminaison :
GET /api/marketplace-scan/posts/list - Objectif : récupère tous les scans publiés dans la base de données.
- Fonctionnalité :
- Interroge la table
MarketplacePostScanpour récupérer tous les enregistrements. - Enregistre le nombre de scans récupérés.
- Formate chaque scan dans un dictionnaire compatible JSON avec
id,scan_name,pagination_scan_name,start_date,completion_date,statusettimestamp. - Renvoie une
JSONResponseavec la liste des scans et un code d'état 200. - Gère les exceptions en les enregistrant et en levant une exception
HTTPException500.
- Interroge la table
get_post_scan_status
- Point de terminaison :
GET /api/marketplace-scan/posts/{scan_id}/status - Objectif : récupère le statut d'un scan publié spécifique à l'aide de son ID.
- Fonctionnalité :
- Interroge la table
MarketplacePostScanpour rechercher le scan avec l'IDscan_idspécifié. - Si le scan n'est pas trouvé, enregistre un avertissement et génère une exception
HTTPException404. - Enregistre le statut et renvoie une réponse
JSONResponseavec l'IDid, le nomscan_nameet le statutstatus(sous forme de chaîne) du scan avec un code d'état 200. - Gère les exceptions en les enregistrant et en générant une exception HTTP 500.
- Interroge la table
enumerate_posts
- Point de terminaison :
POST /api/marketplace-scan/posts/enumerate - Objectif : crée un nouveau scan de publication associé à un scan de pagination.
- Fonctionnalité :
- Vérifie que le
scan_namefourni n'existe pas déjà. - Vérifie si le
pagination_scan_nameréférencé existe dans la tableMarketplacePaginationScan. - S'assure qu'il existe des bots actifs avec l'objectif
SCRAPE_MARKETPLACEet des sessions valides. - Crée un nouvel enregistrement
MarketplacePostScanavec lescan_name, lepagination_scan_nameet le statut initialSTOPPEDfournis. - Enregistre l'enregistrement dans la base de données et consigne la création.
- Stocke un message de réussite dans la session et renvoie une
JSONResponseavec un code d'état 201. - Gère les erreurs liées aux noms de scan en double (400), aux scans de pagination manquants (404), à l'absence de bots actifs (400) ou à d'autres problèmes (500, avec retour en arrière).
- Vérifie que le
start_post_scan
- Point de terminaison :
POST /api/marketplace-scan/posts/{scan_id}/start - Objectif : lance un post scan en traitant des lots d'URL à l'aide des bots disponibles.
- Fonctionnalité :
- Récupère le
MarketplacePostScanparscan_idet vérifie s'il existe. - S'assure que le scan n'est pas déjà en cours (génère une erreur 400 si c'est le cas).
- Vérifie la disponibilité des bots avec l'objectif
SCRAPE_MARKETPLACE. - Récupère le
MarketplacePaginationScanassocié et ses lots. - Met à jour le statut du scan sur
RUNNING, définit lastart_dateet efface lacompletion_date. - Exécute une tâche asynchrone « scrape_batches » pour traiter les lots simultanément :
- Attribue les lots aux bots disponibles à l'aide d'un « ThreadPoolExecutor ».
- Chaque bot récupère un lot d'URL à l'aide de la fonction « scrape_posts », avec des cookies de session et un proxy Tor.
- Gère les erreurs d'analyse JSON en nettoyant les données (normalisation Unicode, suppression des caractères de contrôle).
- Enregistre les publications uniques dans la table « MarketplacePost », en évitant les doublons.
- Enregistre la progression et les erreurs pour chaque lot.
- Marque l'analyse comme « COMPLETED » en cas de succès ou « STOPPED » en cas d'échec.
- Stocke un message de réussite dans la session et renvoie une réponse JSON avec un code d'état 200.
- Gère les erreurs pour les analyses manquantes (404), les analyses en cours (400), l'absence de bots (400), les lots manquants (400) ou d'autres problèmes (500, avec retour en arrière).
- Récupère le
delete_post_scan
- Point de terminaison :
DELETE /api/marketplace-scan/posts/{scan_id} - Objectif : supprime un scan de publication en fonction de son ID.
- Fonctionnalité :
- Interroge la table
MarketplacePostScanpour trouver le scan avec l'IDscan_idspécifié. - Si le scan n'est pas trouvé, enregistre un avertissement et génère une exception
HTTPException404. - Supprime le scan de la base de données et valide la transaction.
- Enregistre la suppression et stocke un message de réussite dans la session.
- Renvoie une réponse
JSONResponseavec un code d'état 200. - Gère les erreurs en les enregistrant, en annulant la transaction et en générant une exception HTTP 500.
- Interroge la table
get_scan_posts
- Point de terminaison :
GET /api/marketplace-scan/posts/{scan_id}/posts - Objectif : récupère toutes les publications associées à une analyse de publication spécifique.
- Fonctionnalité :
- Interroge la table
MarketplacePostScanpour vérifier que le scan existe. - Si le scan n'est pas trouvé, enregistre un avertissement et génère une exception
HTTPException404. - Interroge la table
MarketplacePostpour toutes les publications liées àscan_id. - Enregistre le nombre de publications récupérées.
- Formate chaque publication dans un dictionnaire compatible JSON avec
id,timestamp,title,authoretlink. - Renvoie une
JSONResponseavec la liste des publications et un code d'état 200. - Gère les exceptions en les enregistrant et en générant une exception
HTTPException500.
- Interroge la table
Cette fonctionnalité nécessite le lancement manuel du scraping toutes les quelques heures afin de vérifier l'activité du forum. L'automatisation de ce processus est évitée afin de préserver les ressources, car un scraping continu collecterait souvent des données en double, ce qui entraînerait une consommation inefficace des ressources. Par conséquent, l'exécution ininterrompue de scans du marché n'est pas l'approche optimale.
D'après ma longue expérience, il est généralement déconseillé de mettre en place des scans continus toutes les quelques heures en raison des ressources importantes qu'ils requièrent.
Dans le module 5, nous allons mettre en œuvre un scraping continu des données, mais comme vous le découvrirez, ce processus génère souvent des données en double.
Modèle de frontend pour la place de marché
Pour la place de marché, nous avons besoin d'un modèle avec deux onglets, qui nous permettent de basculer entre plusieurs conteneurs au sein d'une même page. Au lieu de créer deux routes distinctes, nous allons utiliser une seule route avec des onglets afin de simplifier la conception.
Si les onglets peuvent parfois compliquer une application web, dans ce cas précis, ils la simplifient en évitant d'avoir recours à deux modèles distincts, ce qui alourdirait l'application. Au fur et à mesure que vous avancerez, nous explorerons plusieurs modèles, mais pour cette fonctionnalité spécifique, les onglets sont suffisants.
Le modèle se trouve dans app/templates/marketplace.html.
-
Navigation par onglets pour la pagination et l'analyse des publications :
- Objectif : Organise l'interface en onglets « Pagination du marché » et « Publications du marché ».
- Interaction avec le backend : la fonction
openTab()permet d'afficher ou de masquer le contenu de l'onglet (paginationouposts) sans appel direct au backend. Les données initiales pour les deux onglets (pagination_scansetpost_scans) sont fournies parmain.py::marketplaceet rendues à l'aide de Jinja2.
-
Énumération des scans de pagination :
- Objectif : lance un nouveau scan de pagination pour énumérer les pages du marché.
- Interaction avec le backend :
- Le bouton « Enumerate Pages » ouvre une fenêtre modale (
enumerate-modal) avec des champs pour le nom du scan, l'URL de pagination et le nombre maximal de pages. - La soumission du formulaire envoie une requête AJAX POST à
/api/marketplace-scan/enumerate(gérée parmarketplace_api_router) avec les données du formulaire. - Le backend crée un enregistrement
MarketplacePaginationScan, traite la pagination et stocke les résultats. En cas de succès, la page se recharge pour afficher la liste des scans mise à jour. Les erreurs déclenchent une alerte avec le message d'erreur.
- Le bouton « Enumerate Pages » ouvre une fenêtre modale (
-
Énumération post-analyse :
- Objectif : crée une nouvelle analyse post-analyse basée sur une analyse de pagination existante.
- Interaction avec le backend :
- Le bouton « Énumérer les publications » ouvre une fenêtre modale (
enumerate-posts-modal) avec des champs pour le nom de l'analyse et une liste déroulante des analyses de pagination existantes (remplie à partir depagination_scans). - La soumission du formulaire envoie une requête AJAX POST à
/api/marketplace-scan/posts/enumerate(gérée parmarketplace_api_router) avec le nom du scan et le scan de pagination sélectionné. - Le backend crée un enregistrement
MarketplacePostScanlié au scan de pagination choisi. En cas de succès, la page se recharge pour mettre à jour le tableau des scans publiés. Les erreurs déclenchent une alerte.
- Le bouton « Énumérer les publications » ouvre une fenêtre modale (
-
Gestion des scans publiés :
- Objectif : démarrer, afficher ou supprimer des scans publiés.
- Interaction avec le backend :
- Démarrer : chaque ligne de scan de publication (non en cours d'exécution) dispose d'un bouton « Démarrer » qui envoie une requête AJAX POST à
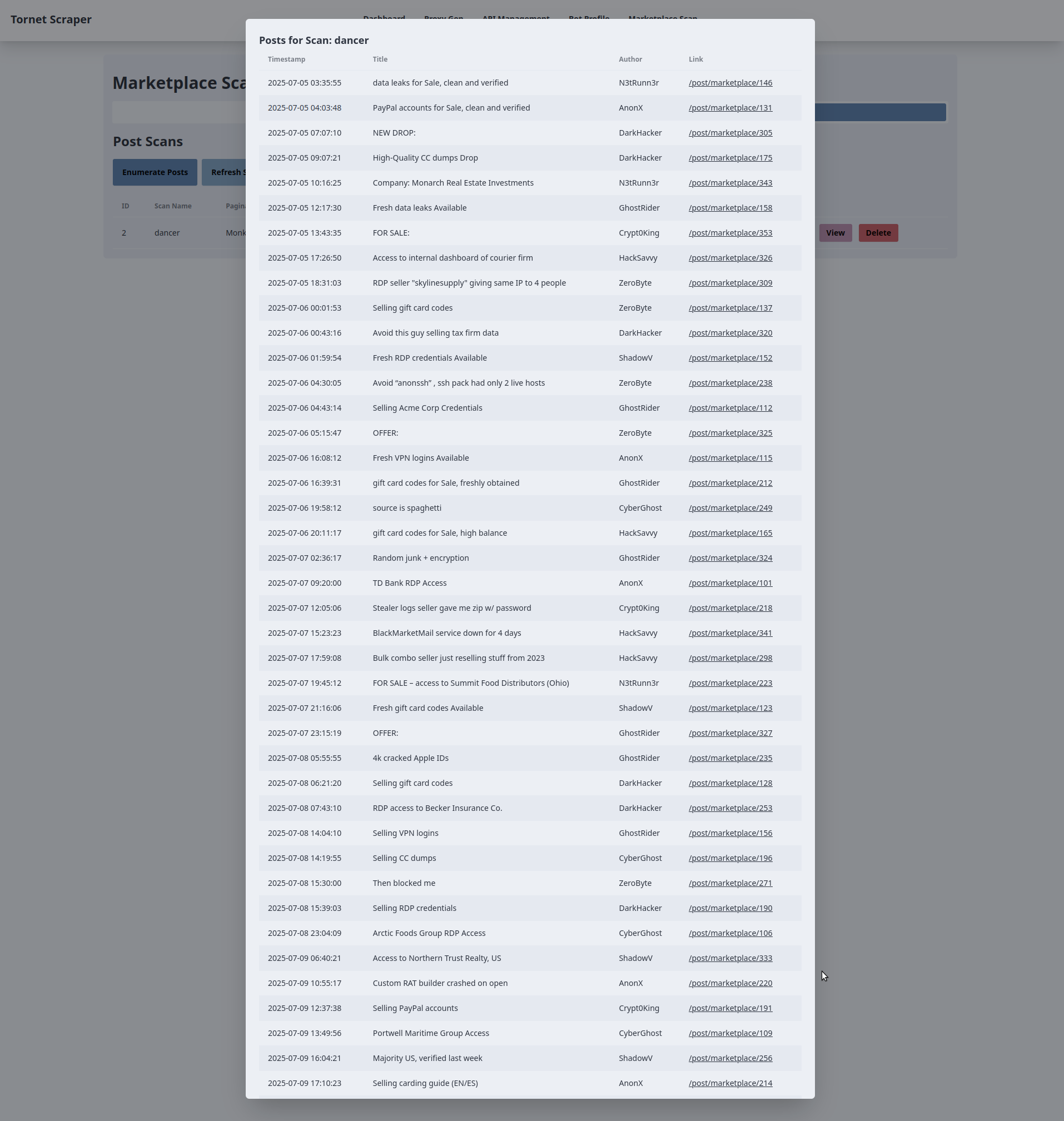
/api/marketplace-scan/posts/{scanId}/start(gérée parmarketplace_api_router) pour lancer le scan. En cas de succès,refreshScans()met à jour le tableau. - Afficher : un bouton « Afficher » ouvre une fenêtre modale (
view-posts-modal-{scanId}) qui récupère les données de publication via une requête AJAX GET vers/api/marketplace-scan/posts/{scanId}/posts, remplissant un tableau avec les détails de la publication (horodatage, titre, auteur, lien). Les erreurs déclenchent une alerte. - Supprimer : un bouton « Supprimer » demande une confirmation et envoie une requête AJAX DELETE à
/api/marketplace-scan/posts/{scanId}pour supprimer le scan de la tableMarketplacePostScan. En cas de succès, la page se recharge. Les erreurs déclenchent une alerte.
- Démarrer : chaque ligne de scan de publication (non en cours d'exécution) dispose d'un bouton « Démarrer » qui envoie une requête AJAX POST à
-
Affichage et suppression des scans paginés :
- Objectif : affiche les détails des scans paginés et permet leur suppression.
- Interaction avec le backend :
- Afficher : chaque ligne de scan paginé comporte un bouton « Afficher » qui ouvre une fenêtre modale (
view-modal-{scanId}) avec des champs en lecture seule pour le nom du scan, l'URL, le nombre maximal de pages et les lots (au format JSON). Les données sont préchargées à partir depagination_scansvia Jinja2, sans appel supplémentaire au backend. - Supprimer : un bouton « Supprimer » (
deleteScan()) demande une confirmation et envoie une requête AJAX DELETE à/api/marketplace-scan/{scanId}pour supprimer le scan de la tableMarketplacePaginationScan. En cas de succès, la page se recharge. Les erreurs déclenchent une alerte.
- Afficher : chaque ligne de scan paginé comporte un bouton « Afficher » qui ouvre une fenêtre modale (
-
Actualisation du tableau des scans postérieurs :
- Objectif : met à jour le tableau des scans postérieurs afin de refléter les statuts actuels.
- Interaction avec le backend :
- Le bouton « Actualiser les scans » déclenche
refreshScans(), qui envoie une requête AJAX GET à/api/marketplace-scan/posts/list(gérée parmarketplace_api_router). - Le backend renvoie une liste d'enregistrements
MarketplacePostScan(ID, nom du scan, nom du scan de pagination, dates de début/fin, statut). Le tableau est mis à jour avec des badges de statut (par exemple, Terminé, En cours, Arrêté). Les erreurs déclenchent une alerte.
- Le bouton « Actualiser les scans » déclenche
Test
Pour commencer le test, vous devez configurer les composants suivants :
- Ajoutez et activez une API CAPTCHA à partir du point de terminaison
/manage-api. - Créez au moins deux profils de bot et connectez-vous pour récupérer leurs sessions à partir du point de terminaison
/bot-profile. - Obtenez l'URL de pagination du marché à partir de
tornet_forum, par exemple :http://site.onion/category/marketplace/Sellers?page=1. - Accédez à
/marketplace-scan, sélectionnez l'ongletMarketplace Pagination, cliquez surEnumerate Pageset remplissez les champs comme suit :- Scan Name :
Monkey - URL de pagination :
http://site.onion/category/marketplace/Sellers?page={page} - Nombre maximal de paginations : 14 (ajustez en fonction du nombre total de pages de pagination disponibles).
- Scan Name :
Une fois l'analyse terminée, cliquez pour afficher les résultats. Une fenêtre modale s'affiche. Vous trouverez ci-dessous un exemple de présentation des lots de pagination au format JSON :
"{\"1\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=14\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=13\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=12\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=11\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=9\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=8\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=7\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=6\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=5\"], \"2\": [\"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=4\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=3\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=2\", \"http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=1\"]}"
Pour énumérer les publications sur la place de marché, procédez comme suit :
- Accédez à
/marketplace-scanet sélectionnez l'ongletMarketplace Posts. - Cliquez sur
Enumerate Posts, entrez un nom de scan, sélectionnez le scan de pagination nomméMonkey, puis cliquez surStart Scan. Cela prépare le scan, mais ne le lance pas. - Revenez à /marketplace-scan, accédez à l'onglet Marketplace Posts, localisez votre scan et cliquez sur le bouton Start pour lancer le scan.
Voici un exemple du résultat obtenu avec ma configuration :
2025-07-21 19:49:41,140 - INFO - Found 3 active bots for scan ID 6: ['DarkHacker', 'CyberGhost', 'ShadowV']
2025-07-21 19:49:41,141 - INFO - Starting post scan tyron (ID: 6) with 2 batches: ['1', '2']
2025-07-21 19:49:41,148 - INFO - Post scan tyron (ID: 6) status updated to RUNNING
2025-07-21 19:49:41,149 - INFO - Assigning batch 1 to bot DarkHacker (ID: 1)
2025-07-21 19:49:41,150 - INFO - Bot DarkHacker (ID: 1) starting batch 1 (10 URLs)
2025-07-21 19:49:41,150 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:41,151 - INFO - Assigning batch 2 to bot CyberGhost (ID: 2)
2025-07-21 19:49:41,151 - INFO - Bot CyberGhost (ID: 2) starting batch 2 (10 URLs)
2025-07-21 19:49:41,151 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=10
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=20
2025-07-21 19:49:46,804 - INFO - Extracted post: timestamp=2025-07-19 07:04:10, title=OFFER:, author=DarkHacker, link=/post/marketplace/1901
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 06:33:54, title=Avoid “anonssh” , ssh pack had only 2 live hosts, author=N3tRunn3r, link=/post/marketplace/588
2025-07-21 19:49:46,805 - INFO - Extracted post: timestamp=2025-07-19 05:56:53, title=Access to Northern Trust Realty, US, author=DarkHacker, link=/post/marketplace/1532
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 05:20:53, title=FOR SALE:, author=GhostRider, link=/post/marketplace/2309
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 04:24:04, title=Custom RAT builder crashed on open, author=ShadowV, link=/post/marketplace/968
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:35:29, title=Private obfuscator for Python tools, author=GhostRider, link=/post/marketplace/1845
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:23:21, title="RootedShells" panel has backconnect, author=ZeroByte, link=/post/marketplace/1829
2025-07-21 19:49:46,806 - INFO - Extracted post: timestamp=2025-07-19 03:09:27, title=RDP seller "skylinesupply" giving same IP to 4 people, author=N3tRunn3r, link=/post/marketplace/1710
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:39:40, title=FOR SALE: DA access into Lakewood Public Services, author=ShadowV, link=/post/marketplace/972
2025-07-21 19:49:46,807 - INFO - Extracted post: timestamp=2025-07-19 02:37:10, title=4k cracked Apple IDs, author=DarkHacker, link=/post/marketplace/1154
2025-07-21 19:49:46,807 - INFO - Scraping URL: http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/category/marketplace/Sellers?page=19
2025-07-21 19:49:46,995 - INFO - Response status code: 200
--- snip ---
--- snip ---
--- snip ---
2025-07-21 19:49:56,643 - INFO - Total posts scraped: 100
2025-07-21 19:49:56,643 - INFO - Bot CyberGhost completed batch 2, found 100 posts
2025-07-21 19:49:56,696 - INFO - Bot DarkHacker saved batch 1 posts to database for scan ID 6
2025-07-21 19:49:56,704 - INFO - Bot CyberGhost saved batch 2 posts to database for scan ID 6
2025-07-21 19:49:56,710 - INFO - Post scan tyron (ID: 6) completed successfully
Une fois la numérisation lancée, vous pouvez passer d'une page à l'autre, la numérisation se poursuivant en arrière-plan :
2025-07-21 19:49:41,152 - INFO - Launching 2 concurrent batch tasks
INFO: 127.0.0.1:34646 - "POST /api/marketplace-scan/posts/6/start HTTP/1.1" 200 OK
2025-07-21 19:49:41,158 - INFO - Fetched 6 post scans
INFO: 127.0.0.1:34646 - "GET /api/marketplace-scan/posts/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /manage-api HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/manage-api/list HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /proxy-gen HTTP/1.1" 200 OK
INFO: 127.0.0.1:34646 - "GET /api/proxy-gen/list HTTP/1.1" 200 OK
2025-07-21 19:49:46,794 - INFO - Response status code: 200
2025-07-21 19:49:46,804 - INFO - Found 10 table rows on
Les analyses ne reprendront pas après le redémarrage du système ou si vous quittez l'application.
Voici à quoi pourrait ressembler le résultat d'une analyse de votre côté :