Dans cette section, nous allons développer les fonctionnalités principales du scraper de données afin de collecter les publications.
La plupart des forums consacrés à la cybercriminalité offrent un accès gratuit à tous les utilisateurs, tandis que l'accès payant permet de débloquer des fonctionnalités telles que la publication dans des catégories spécifiques ou l'exécution d'actions supplémentaires. Lorsque vous utilisez des comptes gratuits pour le web scraping, les forums limitent souvent le contenu que vous pouvez consulter ou commenter au cours d'une période de 24 heures. Pour contourner cette restriction, vous devez limiter les requêtes et répartir les tâches sur plusieurs comptes.
Le fichier tornet_forum comprend une catégorie « marketplace » avec un contenu paginé. Chaque page affiche un tableau de 10 lignes, représentant 10 publications. S'il y a des centaines de pages, cela représente un volume important de contenu à scraper de manière exhaustive sans perdre aucune donnée.
Voici un exemple de pagination sur le marché :
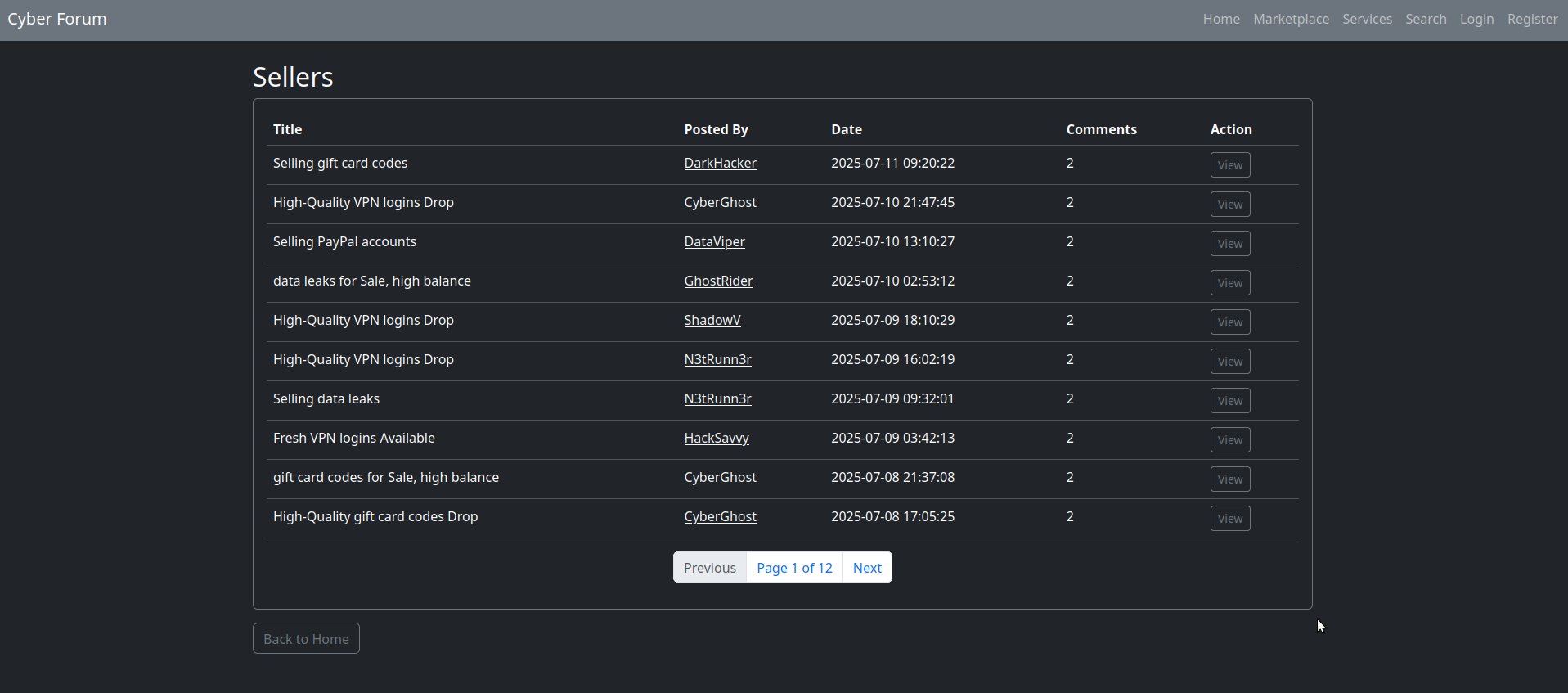
Mon approche consiste à créer un script qui prend en entrée une URL de pagination et le nombre maximal de pages. Il génère ensuite une liste d'URL de pagination, en les divisant en lots de 10. Par exemple, s'il y a 12 pages de pagination, le script crée deux lots : un avec 10 URL de pagination et un autre avec 2. Comme chaque page contient 10 articles, chaque bot extraira 100 liens d'articles par lot de 10 pages.
Voici un exemple de structure de lot :
http://127.0.0.1:5000/category/marketplace/Sellers?page=1
http://127.0.0.1:5000/category/marketplace/Sellers?page=2
http://127.0.0.1:5000/category/marketplace/Sellers?page=3
...
http://127.0.0.1:5000/category/marketplace/Sellers?page=10