Dans cette section, je vais expliquer comment surveiller en continu les menaces sur une longue période sans intervention manuelle. L'objectif est simple : créer des cibles avec des priorités spécifiques, en définissant le type de données à collecter et la fréquence de surveillance.
Ce module est ce qui se rapproche le plus de l'enseignement des techniques de surveillance que je puisse légalement proposer. Mon intention n'est pas de promouvoir la surveillance ; cependant, la surveillance est une pratique courante dans le domaine du renseignement sur les menaces. De nombreuses suites de renseignement sur les menaces destinées aux forces de l'ordre incluent une surveillance multiplateforme sur plusieurs forums et sites afin de suivre l'activité des utilisateurs, mais nous n'explorerons pas ce niveau de complexité ici.
Les sujets abordés dans cette section sont les suivants :
- Composants du scraper de profils
- Modèles de base de données
- Backend de la liste de surveillance
- Modèle pour créer des listes de surveillance
- Modèle pour afficher les résultats de la liste de surveillance
- Test
Composants du scraper de profil
Dans le tornet_forum, les profils des utilisateurs affichent les commentaires et les publications dans un tableau, ce qui nous permet de voir toutes les activités des utilisateurs et d'accéder aux liens vers les publications qu'ils ont commentées ou créées.
Voici un exemple de page de profil :

Dans app/scrapers/profile_scraper.py, la fonction scrape_profile accepte un paramètre appelé scrape_option, qui définit la priorité de scraping : everything (tout), comments (commentaires uniquement) ou posts (publications uniquement).
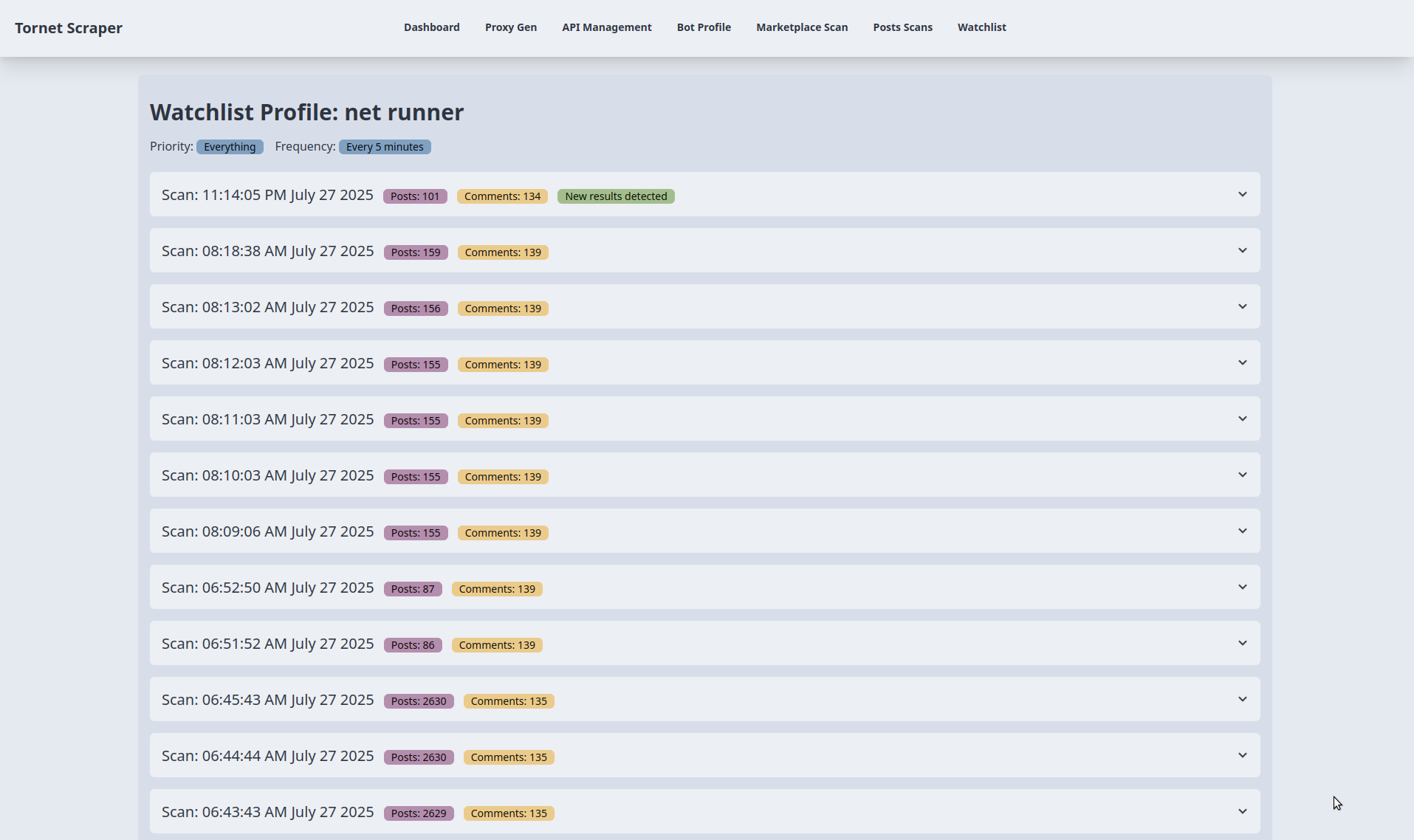
Les données de profil sont récupérées selon la fréquence spécifiée, par exemple toutes les 5 minutes, toutes les heures ou toutes les 24 heures.
1. scrape_profile :
- Objectif : récupère les détails du profil, les publications et les commentaires d'une URL de profil spécifiée à l'aide du scraping web avec BeautifulSoup.
- Paramètres clés :
url: URL de la page de profil à scraper.session_cookie: Cookie d'authentification pour accéder à la page.user_agent: Chaîne de l'agent utilisateur pour les en-têtes de requête HTTP.tor_proxy: adresse proxy pour le routage Tor.scrape_option: spécifie ce qu'il faut extraire : « comments », « posts » ou « everything » (par défaut).
- Retourne : dictionnaire sérialisable en JSON contenant les détails du profil, les publications, les commentaires et leur nombre, ou un dictionnaire d'erreurs si l'extraction échoue.
Plus tard, nous utiliserons cette fonction pour extraire les données de profil. Notez que nous nous concentrons sur l'extraction des titres des publications, des URL et des horodatages, et non sur le contenu complet des publications ou des commentaires.
Modèles de base de données
Nous avons besoin de deux tables : une pour gérer toutes les cibles et une autre pour stocker les données de chaque cible.
Vous trouverez ces tables définies dans app/database/models.py :
class Watchlist(Base):
__tablename__ = "watchlists"
id = Column(Integer, primary_key=True, index=True)
target_name = Column(String, unique=True, index=True)
profile_link = Column(String)
priority = Column(String)
frequency = Column(String)
timestamp = Column(DateTime, default=datetime.utcnow)
class WatchlistProfileScan(Base):
__tablename__ = "watchlist_profile_scans"
id = Column(Integer, primary_key=True, index=True)
watchlist_id = Column(Integer, ForeignKey("watchlists.id"), nullable=False)
scan_timestamp = Column(DateTime, default=datetime.utcnow)
profile_data = Column(JSON)
Nous stockons toutes les données du profil utilisateur sous la forme d'une chaîne JSON unique et complète.
Backend de la liste de surveillance
Le code backend se trouve dans app/routes/watchlist.py. Bien que le code soit volumineux et complexe, concentrez-vous sur les deux dictionnaires clés suivants :
# Map stored frequency values to labels
FREQUENCY_TO_LABEL = {
"every 5 minutes": "critical",
"every 1 hour": "very high",
"every 6 hours": "high",
"every 12 hours": "medium",
"every 24 hours": "low"
}
# Map frequency labels to intervals (in seconds)
FREQUENCY_MAP = {
"critical": 5 * 60,
"very high": 60 * 60,
"high": 6 * 60 * 60,
"medium": 12 * 60 * 60,
"low": 24 * 60 * 60
}
La fréquence détermine la fréquence à laquelle nous récupérons les profils. Une priorité critique déclenche des analyses toutes les 5 minutes, tandis qu'une priorité faible indique une cible moins urgente, avec des profils récupérés toutes les 24 heures.
Fonctions principales dans watchlist.py
-
schedule_all_tasks(db: Session):- Objectif : planifie les tâches de scraping pour tous les éléments de la liste de surveillance au démarrage de l'application.
- Fonctionnalité : interroge tous les éléments
Watchlistde la base de données et appelleschedule_taskpour chaque élément afin de configurer des tâches de scraping périodiques. - Paramètres clés :
db: session de base de données SQLAlchemy.
- Retourne : Aucun. Enregistre le nombre de tâches planifiées ou d'erreurs.
- Remarques : Gère les exceptions pour éviter les échecs de démarrage et enregistre les erreurs à des fins de débogage.
-
schedule_task(db: Session, watchlist_item: Watchlist):- Objectif : Planifie une tâche de scraping récurrente pour un élément spécifique de la liste de surveillance.
- Fonctionnalité : mappe la fréquence de l'élément à un intervalle (par exemple, « toutes les 24 heures » à 86 400 secondes) et planifie une tâche à l'aide d'APScheduler pour exécuter
scrape_and_saveà l'intervalle spécifié. - Paramètres clés :
db: session de base de données SQLAlchemy.watchlist_item: objetWatchlistcontenant les détails de l'élément.
- Retourne : Aucun. Enregistre les détails de la planification (par exemple, l'ID de l'élément, l'intervalle).
- Remarques : utilise
FREQUENCY_TO_LABELetFREQUENCY_MAPpour le mappage fréquence-intervalle.
-
scrape_and_save(watchlist_id: int, db: Session = None):- Objectif : effectue une seule opération de scraping pour un élément de la liste de surveillance et enregistre les résultats.
- Fonctionnalité : Récupère l'élément de la liste de surveillance et un bot aléatoire avec l'objectif
SCRAPE_PROFILEdans la base de données, appellescrape_profileavec les informations d'identification du bot et stocke le résultat dansWatchlistProfileScan. Crée une nouvelle session de base de données si aucune n'est fournie. - Paramètres clés :
watchlist_id: ID de l'élément de la liste de surveillance à scraper.db: session de base de données SQLAlchemy facultative.
- Retourne : Aucun. Enregistre les succès, les erreurs ou les résultats vides et valide les données dans la base de données.
- Remarques : gère l'analyse des cookies de session, valide les résultats de la récupération et garantit le nettoyage correct de la session.
-
get_watchlist(db: Session):- Objectif : récupère tous les éléments de la liste de surveillance.
- Fonctionnalité : interroge la table
Watchlistet renvoie tous les éléments sous forme de liste d'objetsWatchlistResponse. - Paramètres clés :
db: session de base de données SQLAlchemy (viaDepends(get_db)).
- Retourne : Liste d'objets
WatchlistResponse. - Remarques : Génère une erreur HTTP 500 avec journalisation si la requête échoue.
-
get_watchlist_item(item_id: int, db: Session):- Objectif : Récupère un seul élément de la liste de surveillance par ID.
- Fonctionnalité : interroge la table
Watchlistpour l'item_idspécifié et renvoie l'élément sous forme d'objetWatchlistResponse. - Paramètres clés :
item_id: ID de l'élément de la liste de surveillance.db: session de base de données SQLAlchemy.
- Retourne : objet
WatchlistResponseou lève une exception HTTP 404 si l'élément n'est pas trouvé. - Remarques : enregistre les erreurs et lève une exception HTTP 500 en cas de problèmes inattendus.
-
create_watchlist_item(item: WatchlistCreate, db: Session):- Objectif : crée un nouvel élément de la liste de surveillance et planifie sa tâche de scraping.
- Fonctionnalité : Vérifie que le
target_nameest unique, crée une entréeWatchlist, exécute une analyse immédiate si aucune analyse n'existe et planifie les analyses futures à l'aide deschedule_task. - Paramètres clés :
item: Modèle PydanticWatchlistCreateavec les détails de l'élément.db: session de base de données SQLAlchemy.
- Retourne : objet
WatchlistResponsepour l'élément créé. - Remarques : renvoie une erreur HTTP 400 si
target_nameexiste, une erreur HTTP 500 pour les autres erreurs.
-
update_watchlist_item(item_id: int, item: WatchlistUpdate, db: Session):- Objectif : met à jour un élément existant de la liste de surveillance et reprogramme sa tâche de scraping.
- Fonctionnalité : vérifie que l'élément existe et que
target_nameest unique (à l'exclusion de l'élément actuel), met à jour les champs et appelleschedule_taskpour ajuster le calendrier de scraping. - Paramètres clés :
item_id: ID de l'élément de la liste de surveillance.item: modèle PydanticWatchlistUpdateavec les détails mis à jour.db: session de base de données SQLAlchemy.
- Retourne : objet
WatchlistResponsemis à jour. - Remarques : génère une erreur HTTP 404 si l'élément est introuvable, une erreur HTTP 400 en cas de doublon de
target_nameou une erreur HTTP 500 en cas d'erreur.
-
delete_watchlist_item(item_id: int, db: Session):- Objectif : supprime un élément de la liste de surveillance et les analyses associées.
- Fonctionnalité : supprime l'élément de
Watchlist, ses analyses deWatchlistProfileScanet la tâche APScheduler correspondante. - Paramètres clés :
item_id: ID de l'élément de la liste de surveillance.db: session de base de données SQLAlchemy.
- Retourne : réponse JSON avec message de réussite.
- Remarques : génère une erreur HTTP 404 si l'élément est introuvable, une erreur HTTP 500 en cas d'erreur. Ignore les tâches de planification manquantes.
-
get_profile_scans(watchlist_id: int, db: Session):- Objectif : récupère tous les résultats d'analyse pour un élément de la liste de surveillance.
- Fonctionnalité : interroge
WatchlistProfileScanpour les analyses correspondant àwatchlist_id, triées par horodatage (décroissant), et les renvoie sous forme d'objetsWatchlistProfileScanResponse. - Paramètres clés :
watchlist_id: ID de l'élément de la liste de surveillance.db: session de base de données SQLAlchemy.
- Retourne : Liste d'objets
WatchlistProfileScanResponse. - Remarques : Génère une erreur HTTP 500 en cas d'erreur de requête.
-
download_scan(scan_id: int, db: Session):- Objectif : Télécharge les données de profil d'une analyse sous forme de fichier JSON.
- Fonctionnalité : récupère le scan par
scan_id, écrit sesprofile_datadans un fichier JSON temporaire et le renvoie sous forme deFileResponse. - Paramètres clés :
scan_id: ID du scan à télécharger.db: session de base de données SQLAlchemy.
- Retourne :
FileResponseavec le fichier JSON. - Remarques : génère une erreur HTTP 404 si le scan est introuvable, une erreur HTTP 500 en cas d'erreur.
-
startup_event():- Objectif : initialise l'APScheduler au démarrage de l'application.
- Fonctionnalité : vérifie si le planificateur n'est pas en cours d'exécution, crée une session de base de données, appelle
schedule_all_taskspour planifier tous les éléments de la liste de surveillance et démarre le planificateur. - Paramètres clés : aucun.
- Retourne : aucun. Enregistre l'état du planificateur.
- Remarques : garantit que le planificateur ne démarre qu'une seule fois afin d'éviter les tâches en double.
Si les fréquences par défaut ne vous conviennent pas, vous pouvez les modifier dans watchlist.py. Pour des raisons de cohérence, vous devrez également mettre à jour les modèles en conséquence. Toutefois, si vous ajustez les fréquences à des fins de débogage, vous pouvez les modifier uniquement dans watchlist.py sans modifier les modèles.
Modèle pour créer des listes de surveillance
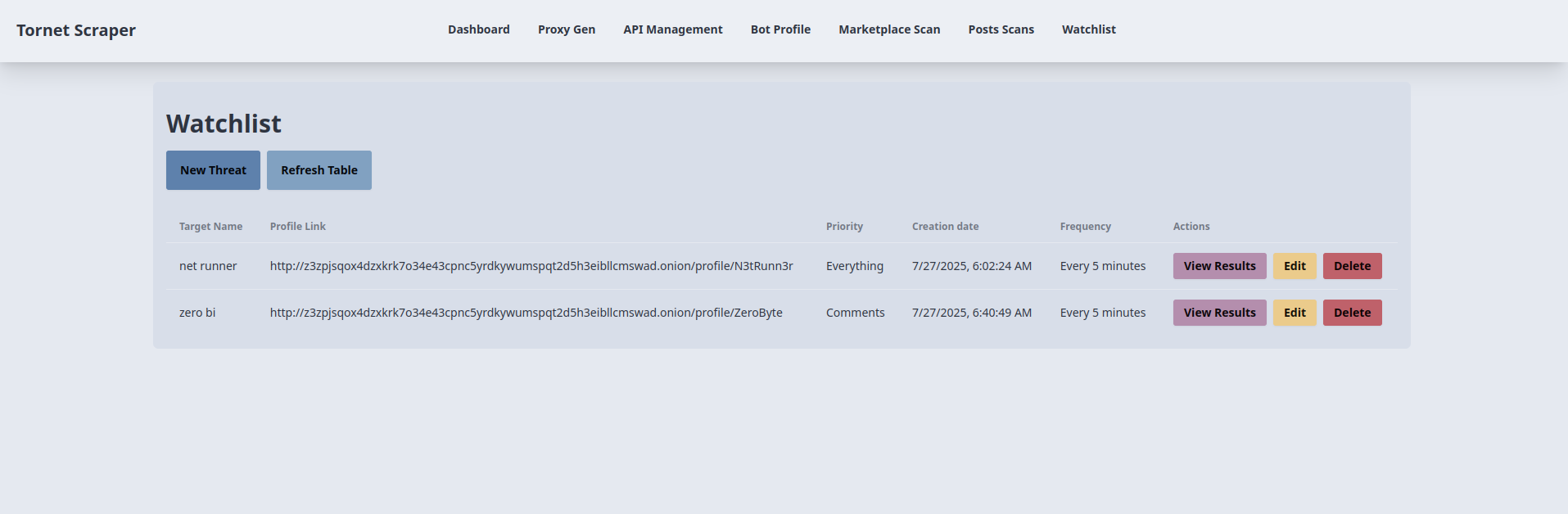
Le modèle que nous allons utiliser est un tableau CRUD simple, qui reste simple et fonctionnel. Vous pouvez le consulter en ouvrant app/templates/watchlist.html.
-
Création d'un élément de la liste de surveillance :
- Objectif : ajoute un nouvel élément à la liste de surveillance pour surveiller un profil cible.
- Interaction avec le backend :
- Le bouton « Nouvelle menace » ouvre une fenêtre modale (
newThreatModal) avec des champs pour le nom de la cible, le lien vers le profil (URL), la priorité (tout,publications,commentaires) et la fréquence (toutes les 24 heures,toutes les 12 heures, etc.). - La soumission du formulaire (
newThreatForm) valide le lien vers le profil et envoie une requête AJAX POST à/api/watchlist-api/items(gérée parwatchlist_api_router) avec les données du formulaire. - Le backend crée un enregistrement « Watchlist », l'enregistre dans la base de données et renvoie une réponse positive. En cas de succès, la fenêtre modale se ferme, le formulaire est réinitialisé et « loadWatchlist() » actualise le tableau. Les erreurs déclenchent une alerte.
- Le bouton « Nouvelle menace » ouvre une fenêtre modale (
-
Liste et actualisation des éléments de la liste de surveillance :
- Objectif : affiche et met à jour un tableau des éléments de la liste de surveillance.
- Interaction avec le backend :
- La fonction
loadWatchlist(), appelée lors du chargement de la page et par le bouton « Actualiser le tableau », envoie une requête AJAX GET à/api/watchlist-api/items(gérée parwatchlist_api_router). - Le backend renvoie une liste d'enregistrements
Watchlist(ID, nom de la cible, lien vers le profil, priorité, fréquence, horodatage). Le tableau est rempli avec ces informations et affiche « Aucun élément trouvé » s'il est vide. Les erreurs déclenchent une alerte et affichent un message d'échec dans le tableau.
- La fonction
-
Modification d'un élément de la liste de surveillance :
- Objectif : met à jour un élément existant de la liste de surveillance.
- Interaction avec le backend :
- Le bouton « Modifier » de chaque ligne du tableau récupère les données de l'élément via une requête AJAX GET vers
/api/watchlist-api/items/{id}(gérée parwatchlist_api_router) et remplit leeditThreatModalavec les valeurs actuelles. - La soumission du formulaire (
editThreatForm) valide le lien vers le profil et envoie une requête AJAX PUT à/api/watchlist-api/items/{id}avec les données mises à jour. - Le backend met à jour l'enregistrement
Watchlist. En cas de succès, la fenêtre modale se ferme etloadWatchlist()actualise le tableau. Les erreurs déclenchent une alerte.
- Le bouton « Modifier » de chaque ligne du tableau récupère les données de l'élément via une requête AJAX GET vers
-
Suppression d'un élément de la liste de surveillance :
- Objectif : supprime un élément de la liste de surveillance.
- Interaction avec le backend :
- Le bouton « Supprimer » de chaque ligne du tableau demande une confirmation et envoie une requête AJAX DELETE à
/api/watchlist-api/items/{id}(gérée parwatchlist_api_router). - Le backend supprime l'enregistrement
Watchlist. En cas de succès,loadWatchlist()actualise le tableau. Les erreurs déclenchent une alerte.
- Le bouton « Supprimer » de chaque ligne du tableau demande une confirmation et envoie une requête AJAX DELETE à
-
Affichage des résultats de la liste de surveillance :
- Objectif : redirige vers une page de résultats pour le profil d'un élément de la liste de surveillance.
- Interaction avec le backend :
- Le bouton « Afficher les résultats » de chaque ligne du tableau renvoie vers
/watchlist-profile/{id}(géré parmain.py::watchlist_profile). - Le backend affiche un modèle avec les résultats issus des données de surveillance de l'élément de la
Watchlist(par exemple, les publications ou les commentaires). Aucun appel AJAX direct n'est effectué, mais la redirection repose sur la récupération des données du backend.
- Le bouton « Afficher les résultats » de chaque ligne du tableau renvoie vers
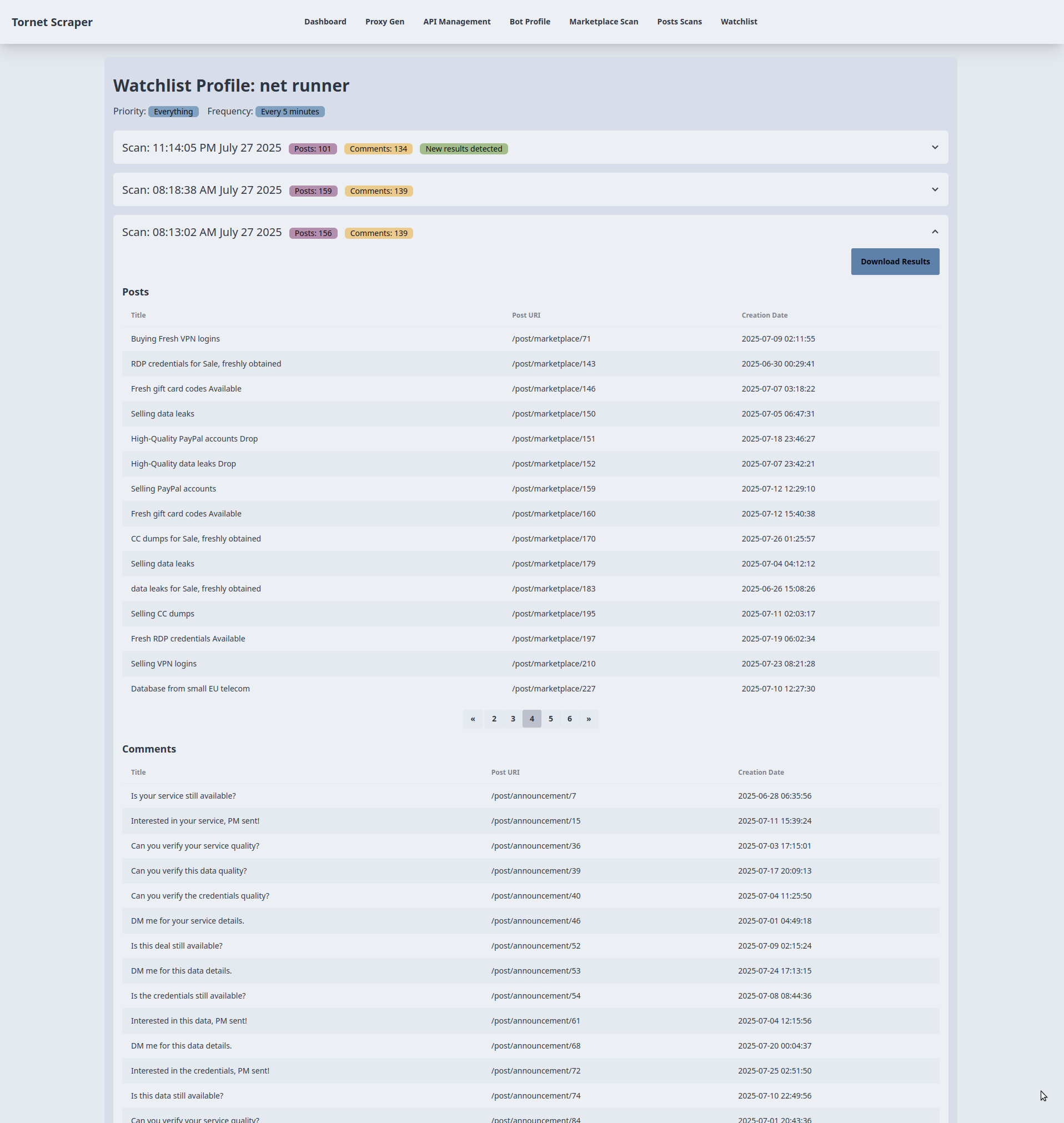
Modèle pour afficher les résultats de la liste de surveillance
Nous avons besoin d'un modèle dédié pour afficher les résultats pour chaque cible, car nous traitons un volume important de données qui doivent être organisées par date pour plus de clarté.
-
Affichage des résultats de l'analyse :
- Objectif : affiche les résultats de l'analyse d'un élément de la liste de surveillance dans des sections en accordéon.
- Interaction avec le backend :
- Le modèle reçoit
watchlist_item(nom de la cible, priorité, fréquence) etscans(liste des données d'analyse avecprofile_datacontenant les publications et les commentaires) demain.py::watchlist_profile. - Chaque accordéon représente une analyse et affiche l'horodatage de l'analyse, le nombre de publications et le nombre de commentaires (à partir de
profile_data). Un badge « Nouveaux résultats détectés » apparaît si le nombre de publications ou de commentaires du dernier scan diffère de celui du scan précédent. Les données sont rendues à l'aide de Jinja2 sans appel API supplémentaire.
- Le modèle reçoit
-
Tableaux des publications et des commentaires :
- Objectif : affiche jusqu'à 15 publications et commentaires par scan dans des tableaux séparés.
- Interaction avec le backend :
- Pour chaque scan, les publications (
profile_data.posts) et les commentaires (profile_data.comments) sont rendus dans des tableaux avec des colonnes pour le titre, l'URL et la date de création (ou le texte du commentaire pour les commentaires). Si aucune donnée n'existe, le message « Aucune publication/commentaire trouvé » s'affiche. - Les données sont préchargées depuis le backend via
main.py::watchlist_profile, ce qui ne nécessite aucune requête API supplémentaire pour le rendu des tableaux.
- Pour chaque scan, les publications (
-
Pagination pour les grands ensembles de données :
- Objectif : gère la pagination pour les scans contenant plus de 15 publications ou commentaires.
- Interaction avec le backend :
- Pour les tableaux contenant plus de 15 éléments, un groupe de boutons de pagination est affiché avec jusqu'à 5 boutons de page, en utilisant
data-items(publications/commentaires encodés en JSON) etdata-total-pagesprovenant deprofile_data.post_countoucomment_count. - La fonction
changePage()gère la pagination côté client, en découpant les données JSON pour afficher 15 éléments par page sans appels supplémentaires au backend. Elle met à jour dynamiquement les boutons de page et le contenu du tableau en fonction de la navigation de l'utilisateur (clics sur précédent/suivant ou sur le numéro de page).
- Pour les tableaux contenant plus de 15 éléments, un groupe de boutons de pagination est affiché avec jusqu'à 5 boutons de page, en utilisant
-
Téléchargement des résultats de l'analyse :
- Objectif : exporter les résultats de l'analyse sous forme de fichier.
- Interaction avec le backend :
- Chaque accordéon d'analyse comprend un bouton « Télécharger les résultats » qui renvoie vers
/api/watchlist-api/download-scan/{scan.id}(géré parwatchlist_api_router). - Le backend génère un fichier téléchargeable (par exemple, JSON ou CSV) contenant les
profile_data(publications et commentaires) du scan. Le lien déclenche un téléchargement direct sans AJAX, en s'appuyant sur le traitement du backend.
- Chaque accordéon d'analyse comprend un bouton « Télécharger les résultats » qui renvoie vers
J'ai choisi les accordéons pour organiser les résultats de l'analyse par horodatage, car je pense que c'est l'approche la plus efficace pour gérer de grands ensembles de données. Bien que vous puissiez préférer une autre méthode, le format accordéon offre un affichage clair et efficace.
Vous n'avez pas besoin de modifier le modèle, car vous pouvez exporter les données au format JSON et les visualiser dans n'importe quel format en dehors de tornet_scraper.
Test
Pour commencer le test, configurez les composants suivants :
- Configurez une API pour la résolution des CAPTCHA.
- Créez un profil de bot avec l'objectif défini sur « scrape_profile » et connectez-vous pour obtenir une session.
- Créez une liste de surveillance à l'aide de la page « /watchlist ».
Pour créer une liste de surveillance afin de surveiller une menace, fournissez les informations suivantes :
- Nom de la cible : tout identifiant de la menace.
- Lien vers le profil : au format « http://z3zpjsqox4dzxkrk7o34e43cpnc5yrdkywumspqt2d5h3eibllcmswad.onion/profile/N3tRunn3r ».
Accédez au menu « Watchlist », cliquez sur « New Threat » et saisissez les informations requises. Lorsque vous ajoutez une cible pour la première fois, la fenêtre modale peut s'interrompre brièvement pendant que le backend lance une analyse initiale. Cette analyse initiale lors de la création d'une cible n'est pas le comportement par défaut du planificateur de tâches dans « watchlist.py », mais une fonctionnalité personnalisée que j'ai implémentée.
Voici comment les cibles sont affichées :
Voici les résultats de la surveillance. À des fins de test, j'ai ajusté la fréquence de planification critique de toutes les 5 minutes à toutes les 1 minute :
Vous pouvez développer n'importe quel accordéon pour afficher les résultats et les télécharger au format JSON :