Dans cette section, je vais vous expliquer comment procéder à un scraping à grande échelle des publications collectées. Le travail préparatoire a déjà été effectué : les détails des publications ont été scrapés, mais leur contenu n'a pas encore été récupéré. Dans la phase finale, nous allons donc scraper le contenu et le traduire si nécessaire.
C'est la phase la plus intéressante, car nous arrivons à la fin du cours. Notre objectif initial était d'identifier les ventes de l'IAB, et c'est bien sûr la raison pour laquelle vous êtes ici, mais cette section est peut-être la plus compliquée de toutes, du moins à première vue.
Elle est complexe car nous construisons une solution pour le scan de données à grande échelle, ce qui va évidemment être compliqué avec de nombreux éléments mobiles, c'est simplement la réalité de la surveillance des menaces à grande échelle.
Les sujets abordés dans cette section sont les suivants :
- Composants du scraper de données
- Modèles de base de données
- Modèles pour la gestion et l'affichage des scans
- Modèle pour afficher le résultat de chaque analyse
- Routes backend
- Tests
Composants du scraper de données
Notre scraper de données comprend plusieurs composants, notamment des modules conçus pour des tâches telles que l'extraction des détails des publications, la traduction du contenu si nécessaire et la classification des données.
Les principaux composants se trouvent dans app/scrapers/post_scraper.py.
-
scrape_post_details:- Objectif : extrait les détails (titre, horodatage, auteur, contenu) d'une URL de publication spécifiée à l'aide de techniques de scraping web.
- Paramètres clés :
post_link: URL de la publication à extraire.session_cookie: cookie d'authentification pour accéder à la publication.tor_proxy: adresse proxy facultative pour le routage Tor.user_agent: chaîne de l'agent utilisateur pour les en-têtes de requête.timeout: durée du délai d'expiration de la requête (par défaut : 30 secondes).
- Retourne : chaîne JSON contenant les détails de l'article extraits ou des informations d'erreur si la requête échoue.
-
translate_string:- Objectif : détecte la langue d'une chaîne de caractères et la traduit en anglais (ou dans la langue cible spécifiée) à l'aide de l'API DeepL si elle n'est pas déjà en anglais.
- Paramètres clés :
input_string: texte à analyser et éventuellement à traduire.auth_key: clé d'authentification de l'API DeepL.target_lang: langue cible pour la traduction (par défaut : EN-US).
- Retourne : chaîne JSON avec le texte original, la langue détectée et le texte traduit (le cas échéant) ou les détails de l'erreur.
-
iab_classify:- Objectif : classe une publication à l'aide du modèle Claude d'Anthropic afin de déterminer si elle traite de la vente d'un accès initial, d'articles sans rapport ou d'avertissements/plaintes.
- Paramètres clés :
api_key: clé API Anthropic pour l'authentification.model_name: nom du modèle Claude à utiliser (par exemple, « claude-3-5-sonnet-20241022 »).prompt: invite textuelle contenant la publication à classer.max_tokens: nombre maximal de tokens en sortie (par défaut : 100).
- Retourne : chaîne JSON avec le résultat de la classification, les scores ou les informations d'erreur si la classification échoue.
Fonction scrape_post_details
Le forum Tornet nécessite une session connectée pour lire les messages, ce qui est courant pour la plupart des forums. Pour remédier à cela, j'ai développé une fonction qui prend un lien vers un message et récupère ses données.
Cette approche est logique, car la table marketplace_posts stocke tous les détails et liens des messages. En chargeant ces données, nous pouvons passer chaque lien vers un message à une fonction telle que scrape_post_details afin d'extraire les informations requises.
Fonction translate_string
Dans la fonction translate_string, nous utilisons DeepL pour la traduction des données. Cependant, dans app/routes/posts.py, nous utilisons d'abord la bibliothèque langdetect pour identifier la langue d'un message. Si la détection de la langue échoue ou si la langue détectée n'est pas l'anglais, nous transmettons le message à la fonction translate_string.
Un avantage clé est que si vous fournissez une chaîne contenant des sauts de ligne :
Venta de acceso a Horizon Logistics\nIngresos: 1200 millones de dólares\nAcceso: RDP con DA\nPrecio: 0,8 BTC\nDM para más detalles
La fonction les conserve dans la sortie traduite :
Sale of access to Horizon Logistics\nRevenue: $1.2 billion\nAccess: RDP with DA\nPrice: 0.8 BTC\nDM for more details
Fonction iab_classify
Dans iab_classify, notre température est réglée par défaut sur 0,1, mais vous pouvez la modifier si vous le souhaitez.
Dans les interactions avec l'IA ou les LLM, la température est un hyperparamètre qui contrôle le caractère aléatoire ou la créativité de la sortie du modèle :
- Objectif : ajuste la distribution de probabilité des sorties possibles du modèle (par exemple, des mots ou des tokens) pendant la génération.
- Fonctionnement :
- Basse température (par exemple, 0,1) : rend le modèle plus déterministe, en favorisant les sorties à forte probabilité. Donne des réponses plus ciblées, prévisibles et conservatrices.
- Température élevée (par exemple, 1,0 ou plus) : augmente le caractère aléatoire, donnant plus de chances aux sorties à faible probabilité. Conduit à des réponses plus créatives, diversifiées ou inattendues.
- Exemple dans le code : dans la fonction
iab_classifyfournie,temperature=0,1est utilisé pour rendre la sortie de classification du modèle Claude plus cohérente et moins aléatoire. - Plage : généralement comprise entre 0 et 1, bien que certains modèles autorisent des valeurs plus élevées pour un caractère aléatoire extrême.
Modèles de base de données
Pour extraire les publications, la taille des lots de publications et le stockage des données, nous avons besoin de deux tables. Voici à quoi ressemblent vos modèles :
class PostDetailScan(Base):
__tablename__ = "post_detail_scans"
id = Column(Integer, primary_key=True, index=True)
scan_name = Column(String, nullable=False, unique=True)
source_scan_name = Column(String, ForeignKey("marketplace_post_scans.scan_name"), nullable=False)
start_date = Column(DateTime(timezone=True), default=datetime.utcnow)
completion_date = Column(DateTime(timezone=True), nullable=True)
status = Column(Enum(ScanStatus), default=ScanStatus.STOPPED, nullable=False)
batch_size = Column(Integer, nullable=False)
site_url = Column(String, nullable=False)
timestamp = Column(DateTime(timezone=True), default=datetime.utcnow)
class MarketplacePostDetails(Base):
__tablename__ = "marketplace_post_details"
id = Column(Integer, primary_key=True, index=True)
scan_id = Column(Integer, ForeignKey("post_detail_scans.id"), nullable=False)
batch_name = Column(String, nullable=False)
title = Column(String, nullable=False)
content = Column(Text, nullable=False)
timestamp = Column(String, nullable=False)
author = Column(String, nullable=False)
link = Column(String, nullable=False)
original_language = Column(String, nullable=True)
original_text = Column(Text, nullable=True)
translated_language = Column(String, nullable=True)
translated_text = Column(Text, nullable=True)
is_translated = Column(Boolean, default=False)
sentiment = Column(String, nullable=True)
positive_score = Column(Float, nullable=True)
negative_score = Column(Float, nullable=True)
neutral_score = Column(Float, nullable=True)
timestamp_added = Column(DateTime(timezone=True), default=datetime.utcnow)
__table_args__ = (UniqueConstraint('scan_id', 'timestamp', 'batch_name', name='uix_scan_timestamp_batch'),)
post_detail_scans
La table post_detail_scans sert à créer des scans qui récupèrent des données de la table marketplace_post_scans. Elle stocke également la taille des lots, car de nombreux sites imposent des limites de débit, telles que des restrictions sur le nombre de publications que vous pouvez lire en 24 heures. Pour gérer cela, nous divisons les publications en lots de 10 ou 20 et attribuons ces lots à des robots configurés avec l'objectif scrape_post.
La table marketplace_post_scans stocke les métadonnées des publications, notamment le titre, le lien, l'horodatage et l'auteur, mais exclut le contenu détaillé.
marketplace_post_details
Cette table stocke les résultats de chaque scan. Nous lançons les analyses dans « post_detail_scans », les chargeons dans le scraper et commençons à collecter les données. Une fois collectées, les données sont enregistrées dans la table « marketplace_post_details ».
Nous suivons des détails complets, notamment le texte original, la langue d'origine, le texte traduit, le sentiment, les scores de confiance, l'auteur, l'horodatage, etc.
Modèles pour la gestion et l'affichage des analyses
Nous avons besoin de deux modèles : un pour gérer les analyses et un autre pour afficher les résultats de chaque analyse. Le modèle pour gérer les analyses est posts_scans.html. Voici un aperçu de son interface :
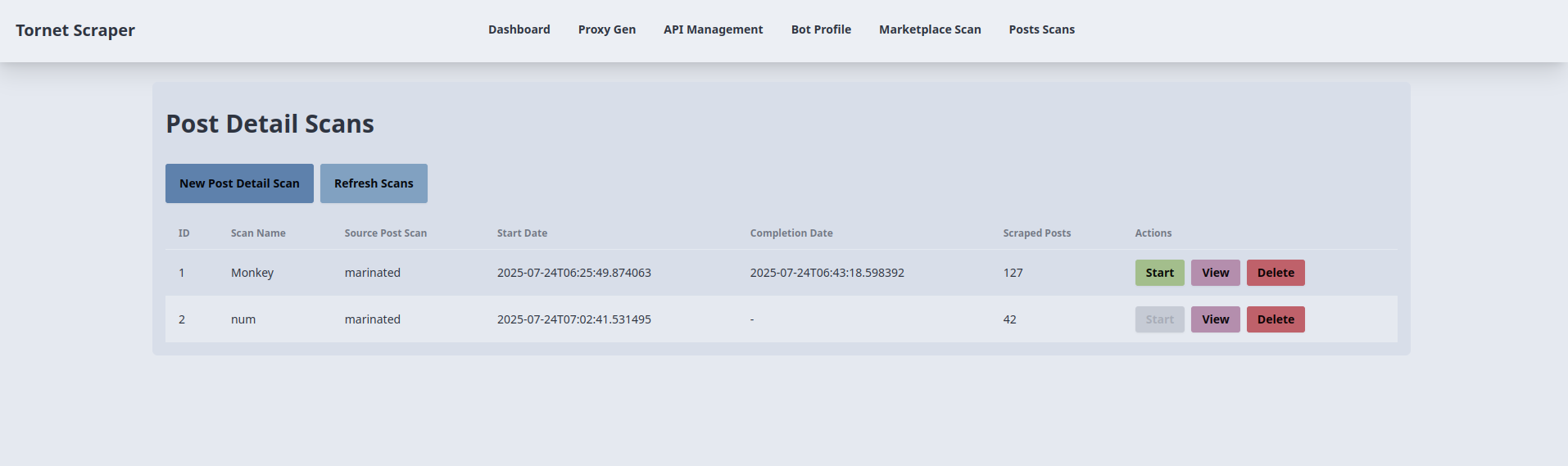
Le code correspondant se trouve dans app/templates/posts_scans.html.
-
Création et démarrage d'une numérisation détaillée d'un article :
- Objectif : crée et lance une nouvelle numérisation détaillée d'un article.
- Interaction avec le backend :
- Le bouton « Nouvelle numérisation détaillée d'un article » ouvre une fenêtre modale (
newScanModal) avec des champs pour le nom de la numérisation, la numérisation de l'article source (liste déroulante des numérisations terminées), la taille du lot et l'URL du site. - La soumission du formulaire déclenche une requête AJAX POST vers
/api/posts-scanner/create(gérée parposts_api_router) avec les données du formulaire, suivie d'une requête POST vers/api/posts-scanner/{id}/startpour lancer le scan. - Le backend crée un enregistrement
PostDetailScan, le lie à unMarketplacePostScanet commence le scraping. Les données du formulaire sont stockées danssessionStoragepour être réutilisées dansstartScan(). En cas de succès, une alerte de réussite s'affiche, la fenêtre modale se ferme etrefreshScans()met à jour le tableau. Les erreurs déclenchent une alerte avec le message d'erreur.
- Le bouton « Nouvelle numérisation détaillée d'un article » ouvre une fenêtre modale (
-
Liste et actualisation des scans détaillés des publications :
- Objectif : affiche et met à jour un tableau des scans détaillés des publications.
- Interaction avec le backend :
- La fonction
refreshScans(), appelée lors du chargement de la page et par le bouton « Refresh Scans », envoie une requête AJAX GET à/api/posts-scanner/list(gérée parposts_api_router). - Le backend renvoie une liste d'enregistrements
PostDetailScan(ID, nom du scan, nom du scan source, dates de début/fin, publications récupérées, statut). Le tableau est rempli avec des badges de statut (par exemple,badge-successpour terminé). Si aucun scan n'existe, le message « Aucun scan disponible » s'affiche. Les erreurs déclenchent une alerte.
- La fonction
-
Démarrage d'un scan détaillé des publications :
- Objectif : lance un scan détaillé des publications existantes.
- Interaction avec le backend :
- Le bouton « Démarrer » de chaque ligne du tableau (désactivé pour les analyses en cours) appelle
startScan(scanId), envoyant une requête AJAX POST à/api/posts-scanner/{scanId}/start(gérée parposts_api_router) avecbatch_sizeetsite_urlprovenant desessionStorage. - Le backend lance l'analyse et met à jour le statut
PostDetailScan. En cas de succès, une alerte s'affiche etrefreshScans()met à jour le tableau. Les erreurs déclenchent une alerte.
- Le bouton « Démarrer » de chaque ligne du tableau (désactivé pour les analyses en cours) appelle
-
Affichage des résultats de l'analyse :
- Objectif : redirige vers une page de résultats pour une analyse spécifique.
- Interaction avec le backend :
- Le bouton « Afficher » de chaque ligne du tableau appelle
viewResults(scanId, scanName), qui redirige vers/posts-scan-result/{scanId}?name={scanName}(géré parmain.py::posts_scan_result). - Le backend affiche un modèle avec les détails de l'analyse, en récupérant les enregistrements
MarketplacePostDetailsassociés. Aucun appel AJAX direct n'est effectué ici, mais la redirection repose sur les données du backend.
- Le bouton « Afficher » de chaque ligne du tableau appelle
-
Suppression d'une analyse détaillée d'une publication :
- Objectif : supprime une analyse détaillée d'une publication.
- Interaction avec le backend :
- Le bouton « Supprimer » de chaque ligne du tableau appelle
deleteScan(scanId)après confirmation de l'utilisateur, envoyant une requête AJAX DELETE à/api/posts-scanner/{scanId}(gérée parposts_api_router). - Le backend supprime l'enregistrement
PostDetailScan. En cas de succès, une alerte de réussite s'affiche etrefreshScans()met à jour le tableau. Les erreurs déclenchent une alerte.
- Le bouton « Supprimer » de chaque ligne du tableau appelle
-
Remplissage du menu déroulant des scans source :
- Objectif : Remplit le menu déroulant des scans source avec les scans de publication terminés.
- Interaction avec le backend :
- Au chargement de la page, une requête AJAX GET vers
/api/posts-scanner/completed-post-scans(gérée parposts_api_router) récupère une liste des nomsMarketplacePostScanterminés. - Le backend renvoie les noms des scans, qui sont ajoutés comme options dans le menu déroulant du nouveau modal de scan. Les erreurs sont consignées dans la console.
- Au chargement de la page, une requête AJAX GET vers
Modèle pour afficher le résultat de chaque scan
Pour afficher le résultat de chaque scan de la place de marché, nous avons utilisé des modaux. Mais ici, comme il y a beaucoup d'informations, de recherches et de filtrages, nous avons besoin d'un modèle différent juste pour afficher les résultats.
Voici comment j'utilise la recherche et la classification des sentiments pour filtrer les résultats positifs qui mentionnent l'IAB et contiennent le mot-clé « shell » dans le titre :
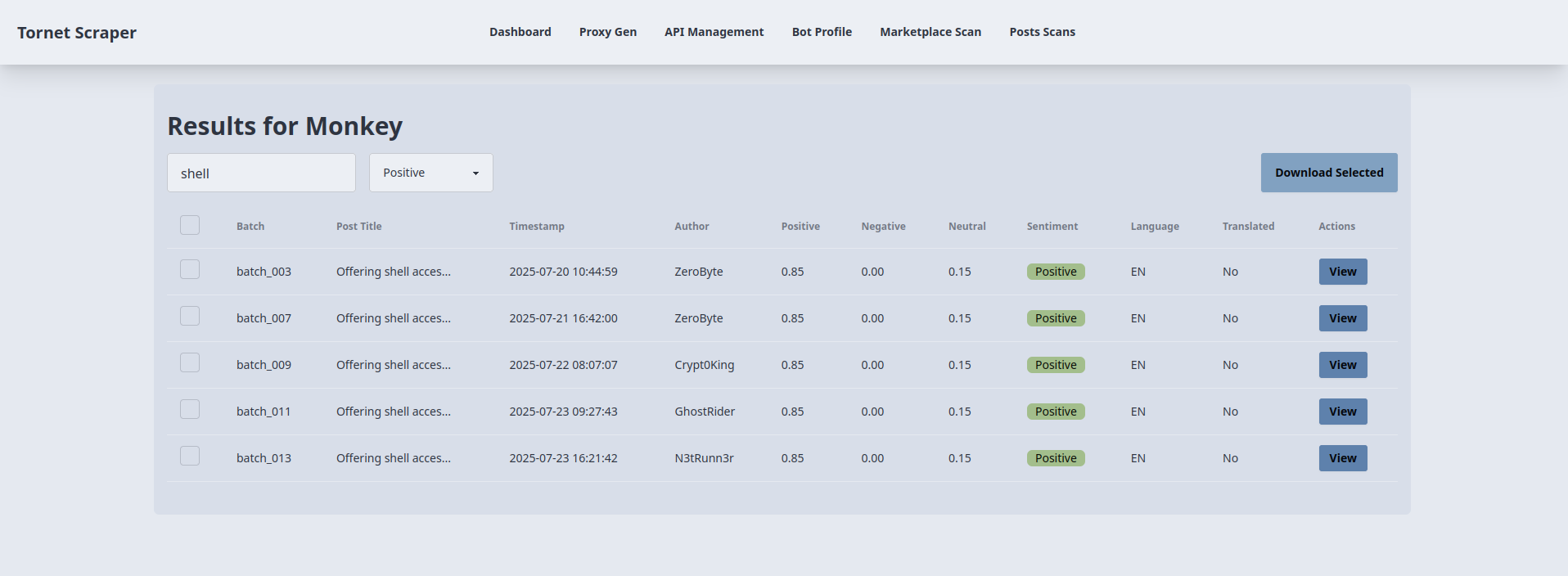
En tant qu'analyste, cela vous est extrêmement utile, car vous pouvez filtrer les résultats, afficher uniquement les éléments que vous jugez essentiels à votre enquête et les télécharger au format JSON.
Le modèle utilisé pour afficher le résultat de chaque analyse se trouve à l'emplacement suivant : app/templates/posts_scan_result.html.
-
Chargement des résultats de l'analyse :
- Objectif : affiche les résultats d'une analyse détaillée d'une publication spécifique dans un tableau.
- Interaction avec le backend :
- Lors du chargement de la page, la fonction
loadResults()extrait lescanIdde l'URL et envoie une requête AJAX GET à/api/posts-scanner/{scanId}/results(gérée parposts_api_router). - Le backend interroge la table
MarketplacePostDetailspour obtenir les résultats de l'analyse (ID, titre, horodatage, auteur, nom du lot, scores de sentiment, langue, texte traduit) et les renvoie au format JSON. - Le tableau est rempli avec des lignes, chacune affichant une case à cocher, le nom du lot, le titre tronqué, l'horodatage, l'auteur, les scores de sentiment (positif, négatif, neutre), le sentiment dominant (calculé côté client comme le score le plus élevé), la langue et le statut de la traduction. Les erreurs déclenchent une alerte.
- Lors du chargement de la page, la fonction
-
Recherche et filtrage des sentiments :
- Objectif : filtre le tableau des résultats par titre de publication et sentiment.
- Interaction avec le backend :
- La fonction
filterTable(), déclenchée par la touche « Entrée » sur#searchInputet la modification de#sentimentFilter, filtre les lignes du tableau côté client en fonction du terme recherché (titre) et du sentiment sélectionné (all,positive,negative,neutral). - Aucun appel direct au backend n'est effectué ; le filtrage utilise l'attribut
data-sentimentdéfini lors deloadResults(). Les lignes sont affichées ou masquées en fonction des correspondances, ce qui garantit des mises à jour dynamiques sans requêtes supplémentaires.
- La fonction
-
Affichage des détails d'une publication :
- Objectif : affiche les informations détaillées d'une publication sélectionnée dans une fenêtre modale.
- Interaction avec le backend :
- Le bouton « Afficher » de chaque ligne du tableau remplit le
viewModalavec les données stockées dans les attributsdata-*du bouton (titre, horodatage, auteur, lot, scores de sentiment, sentiment, langue, statut de traduction, lien, contenu original/traduit) provenant de la réponse initialeloadResults(). - Aucun appel backend supplémentaire n'est nécessaire ; la fenêtre modale affiche des champs en lecture seule et des zones de texte. Le bouton « Fermer » masque la fenêtre modale sans interaction avec le backend.
- Le bouton « Afficher » de chaque ligne du tableau remplit le
-
Téléchargement des résultats sélectionnés :
- Objectif : exporte les résultats des publications sélectionnées sous forme de fichier JSON.
- Interaction avec le backend :
- Le bouton « Télécharger la sélection » (
#downloadSelected) collecte les ID des lignes cochées (filtrées par visibilité) et envoie une requête AJAX POST à/api/posts-scanner/{scanId}/download(gérée parposts_api_router) avec le tableaupost_ids. - Le backend récupère les enregistrements
MarketplacePostDetailscorrespondants et les renvoie au format JSON. Le client crée un fichier JSON téléchargeable (scan_{scanId}_results.json) à l'aide d'unBlob. Si aucune ligne n'est sélectionnée ou si une erreur se produit, une alerte s'affiche.
- Le bouton « Télécharger la sélection » (
Routes backend
Le code backend se trouve dans app/routes/posts.py. Voici une explication des fonctions clés.
get_post_scans :
- Objectif : récupère toutes les analyses détaillées des publications dans la base de données, y compris des détails tels que l'ID de l'analyse, le nom, le nom de la source de l'analyse, les dates de début/fin, le statut et le nombre de publications récupérées.
- Principales fonctionnalités :
- Interroge
PostDetailScanet jointMarketplacePostDetailspour compter les publications récupérées. - Renvoie une réponse JSON avec les détails du scan.
- Gère les erreurs avec un code d'état 500 si la requête échoue.
- Interroge
get_completed_post_scans :
- Objectif : récupère les noms des analyses
MarketplacePostScanterminées pour les utiliser dans un menu déroulant. - Principales fonctionnalités :
- Filtre les analyses ayant le statut
COMPLETEDet une date d'achèvement non nulle. - Renvoie une liste JSON des noms des analyses.
- Génère une erreur 500 si la requête échoue.
- Filtre les analyses ayant le statut
create_post_scan :
- Objectif : Crée un nouveau scan détaillé de publication en fonction d'une configuration fournie.
- Principales fonctionnalités :
- Vérifie que le nom du scan est unique et que le scan source est terminé.
- Crée un enregistrement
PostDetailScanavec le statutSTOPPEDet stocke la taille du lot et l'URL du site. - Renvoie une réponse JSON avec l'ID du scan et un message de réussite.
- Gère les noms de scan en double (400) ou les scans source manquants (404).
start_post_scan :
- Objectif : Lance un scan détaillé des publications en traitant les publications d'un scan source par lots à l'aide de plusieurs bots.
- Principales fonctionnalités :
- Vérifie que le scan existe, qu'il n'est pas en cours d'exécution et qu'il dispose des API requises (traduction et IAB) et des bots actifs.
- Divise les publications en lots et les attribue à des bots pour le scraping, la traduction et la classification simultanés.
- Utilise
scrape_post_details,translate_stringetiab_classifypour traiter les publications. - Enregistre les résultats dans
MarketplacePostDetailset met à jour le statut du scan surRUNNINGouCOMPLETED/STOPPEDen fonction du résultat. - Gère les erreurs avec les codes d'état HTTP appropriés (404, 400, 500).
delete_post_scan :
- Objectif : supprime une analyse détaillée de publication spécifiée de la base de données.
- Principales fonctionnalités :
- Vérifie que l'analyse existe avant la suppression.
- Supprime l'enregistrement
PostDetailScanet valide la modification. - Renvoie un message de réussite au format JSON ou une erreur 404 si l'analyse est introuvable.
- Gère les erreurs inattendues avec un code d'état 500.
get_scan_results :
- Objectif : Récupère les résultats détaillés d'un scan de détails de publication spécifique.
- Principales fonctionnalités :
- Interroge
MarketplacePostDetailspour un ID de scan donné. - Renvoie une réponse JSON avec des détails tels que le titre, le contenu, l'auteur, l'horodatage, les données de traduction et les scores de classification.
- Génère une erreur 500 si la requête échoue.
- Interroge
download_post_results :
- Objectif : télécharge les détails d'une publication spécifique pour un identifiant de scan donné en fonction des identifiants de publication fournis.
- Principales fonctionnalités :
- Vérifie que le scan existe et que les identifiants de publication demandés sont valides.
- Renvoie une réponse JSON avec les détails de la publication sélectionnée, notamment le titre, l'horodatage, l'auteur, les scores de sentiment et les données de traduction.
- Génère une erreur 404 si le scan ou les publications sont introuvables, ou une erreur 500 pour d'autres problèmes.
Nous utilisons la fonction detect de la bibliothèque langdetect dans scrape_post_batches. Si vous le souhaitez, vous pouvez modifier la fonction « translate_string » dans « post_scraper.py » afin d'intégrer également « langdetect ». Bien que cela soit possible, je préfère l'approche actuelle pour son efficacité.
Test
Pour tester cette fonctionnalité, configurez les composants suivants :
- Récupérez les détails des publications du marché à l'aide de la page « /marketplace-scan ».
- Configurez une API IA pour contourner le CAPTCHA.
- Créez au moins deux profils de bot avec l'objectif « scrape_post » et connectez-vous pour obtenir les cookies de session.
- Configurez l'API DeepL pour la traduction.
- Configurez l'API IAB pour identifier les courtiers d'accès initiaux.
Pour l'API IAB, vous aurez besoin de l'invite suivante :
Does this post discuss selling initial access to a company (e.g., RDP, VPN, admin access), selling unrelated items (e.g., accounts, tools), or warnings/complaints? Classify it as:
- Positive Posts: direct sale of unauthorized access to a company, this usually include the target's name.
- Neutral Posts: general offers for tools, exploits or malware without naming a specific target.
- Negative Posts: off-topic or unrelated services such as hosting, spam tools or generic VPS sales.
The content must be specifically about selling access to a company or business whose name is mentioned in the post.
Return **only** a JSON object with:
- `classification`: "Positive", "Neutral", or "Negative".
- `scores`: Probabilities for `positive`, `neutral`, `negative` (summing to 1).
Wrap the JSON in ```json
{
...
}
``` to ensure proper formatting. Do not include any reasoning or extra text.
Post:
```markdown
TARGET-POST-PLACEHOLDER
```
Vous pouvez modifier l'invite et faire vos propres essais.